
위키피디어 글 자동 생성: 구조 중심 접근
2017년 7월 21일 초안 작성
서론
논문의 주제는 위키피디어의 글을 자동으로 생성하는 내용입니다. 도메인에 특화된 템플릿을 선정하고 주제별 검색 결과를 꽂아서 보여주는 방식이 최종 결과가 문서냐 검색 결과냐의 차이만 있을뿐 서치라이트의 구조와 매우 유사합니다. 좀 지난(2009년) 논문이긴 해도 당시 퍼셉트론을 이용해 파라미터를 학습하고 이를 통해 각각의 주제에서 발췌를 결합하여 새로운 문서를 만들어 냈습니다. 코드도 공개되어 있는데 퍼셉트론을 파이썬 코딩으로 직접 구현했습니다. 지금은 좋은 딥러닝 라이브러리가 많이 나와 있으니 논문의 코드보다 훨씬 더 세련되게 구현할 수 있을 것 같네요.
- 논문: Automatically Generating Wikipedia Article: A Structure-Aware Approach, C Sauper and R Barzilay, 2009 http://www.aclweb.org/anthology/P09-1024
- 코드: https://github.com/csauper/wikipedia
- 자동으로 생성된 위키피디어 문서: http://people.csail.mit.edu/csauper/?page_id=64
- 위키피디어 히스토리에서 조회한 예전에 실제로 생성한 문서 내용: https://en.wikipedia.org/w/index.php?title=3-M_syndrome&oldid=221932230
아울러 재밌게 볼만한 참고 자료를 소개합니다.
- 위키피디어는 문서 작성에 인공지능을 사용하나요? https://www.quora.com/Does-Wikipedia-use-artificial-intelligence-to-generate-any-of-its-articles
일부 팩트 기반의 문서를 작성할때는 봇을 활용한다고. 아래는 US census data를 기반으로 작성된 실제 사례:The 2010 United States Census reported that Palo Alto had a population of 64,403. The population density was 2,497.5 people per square mile (964.3/km²). The racial makeup of Palo Alto was 41,359 (64.2%) White, 17,461 (27.1%) Asian, 1,197 (1.9%) African American, 121 (0.2%) Native American, 142 (0.2%) Pacific Islander, 1,426 (2.2%) from other races, and 2,697 (4.2%) from two or more races. Hispanic or Latino of any race were 3,974 persons (6.2%).
- WikiWrite: Generating Wikipedia Articles Automatically https://siddbanpsu.github.io/publications/ijcai16-banerjee.pdf
비슷한 내용의 논문인데 아직 읽어보진 못했습니다. - Autopedia: Automatic Domain-Independent Wikipedia
Article Generation http://wwwconference.org/proceedings/www2011/companion/p161.pdf
중국에서 나온 논문인데 저자는 엄청 많은데 포스터 발표라 내용은 달랑 2장
아래에 논문을 번역하여 소개합니다. 비문인 경우에는 가능한 수정하려고 노력했으나 직역체라 다소 어색할 수 있는 점은 양해바랍니다.
위키피디어 글 자동 생성: 구조 중심 접근
초록
이 논문에서는 인터넷에서 가져온 정보로 구성된 주제에 대한 포괄적인 텍스트 개요를 작성하기 위한 접근 방법을 조사합니다. 인간이 작성한 텍스트의 상위 구조를 사용하여 새로운 개요의 주제 구조에 대한 도메인별 템플릿을 자동으로 유도합니다. 우리 작업의 알고리즘 혁신은 전체 템플릿을 위한 공동 컨텐츠 선택을 위한 주제별 추출기를 학습하는 방법입니다.
글로벌 정수 선형 프로그래밍(ILP) 공식을 사용하여 표준 퍼셉트론 알고리즘을 보강하여 각 주제에 대한 정보의 로컬 적합성과 전체 개요 전반의 글로벌 일관성을 최적화합니다. 평가 결과, 구조 정보를 컨텐츠 선택 프로세스에 통합할때 얻을 수 있는 이점을 확인할 수 있습니다.
1. 소개
이 글에서는 관심 주제에 대한 포괄적인 요약을 제공하는 여러 단락 개요 기사를 자동으로 작성하는 작업을 고려합니다. 이러한 개요의 예에는 IMDB의 배우 약력과 위키피디어의 질병 개요가 있습니다.
이러한 글을 손으로 작성하는 것은 특히 광범위한 인터넷 자원에, 관련된 정보가 광범위하게 분산될때 노동 집약적인 과제입니다. 우리의 목표는 이 프로세스를 자동화하는 것입니다. 인터넷을 통한 관련 인용문을 지능적으로 조합함으로써 주제 ‘3-M 증후군’의 개요를 만드는 것을 목표로 합니다.
먼저 다중 문서화 요약을 위해 개발된 방법을 채택할 수 있습니다. 그러나, 우리의 과제는 컨텐츠 계획에 관한 추가적인 기술적 도전에 직면합니다. 포괄적인 개요 문서를 생성하려면 인터넷 검색과 같은 관련 자료를 수집하는 사전 예방 전략이 필요합니다. 또한, 복수의 주제를 논의하는 더 긴 문서를 만들 때 출력 가독성을 유지하는 도전 과제에 직면합니다.
우리의 접근 방식에서는 인간이 작성한 문서의 고차원 구조가 잘 구성된 포괄적인 개요 기사를 작성하는 데 어떻게 사용될 수 있는지 탐구합니다. 도메인별로 자동 생성된 컨텐츠 템플릿을 사용하여 기사의 관련 자료를 선택합니다. 예를 들어, 질병에 대한 기사의 템플릿에는 진단, 원인, 증상 및 치료가 포함될 수 있습니다. 시스템은 관심 도메인에서 인간이 작성한 문서 구조의 패턴을 분석하여 이러한 템플릿을 유도합니다. 그런 다음 이 템플릿의 각 부분에 대해 인터넷에서 컨텐츠를 선택하여 새 글을 작성합니다.
시스템의 결과는 아래 그림 1에서 확인할 수 있습니다.

우리 작업의 알고리즘 혁신은 전체 템플릿에서 공동으로 컨텐츠 선택을 위한 주제별 추출기를 학습하는 방법입니다. 단일 주제별 추출기를 학습하는 것은 표준 분류 체계에서 쉽게 달성 할 수 있습니다. 그러나 템플릿의 여러 주제에 대한 선택은 상호 의존적입니다. 예를 들어, 다중 주제의 기사에서는 여러 주제에 걸쳐 중복될 가능성이 있습니다. 모든 주제에 대한 컨텐츠 선택을 동시에 학습하면 이러한 주제간 연결을 명시적으로 모델링 할 수 있습니다.
이 작업을 구조화된 분류 문제로 공식화합니다. 주어진 도메인에서 예제 기사의 학습 세트를 통해 실행되는 정수 선형 프로그래밍(ILP) 공식으로 보강된 퍼셉트론 알고리즘을 사용하여 모델의 매개 변수를 추정합니다.
이 구조 인식 방식의 핵심 기능은 두 가지입니다.
자동 템플릿 생성: 템플릿은 인간이 작성한 문서에서 자동으로 생성됩니다. 이렇게 하면 개요 기사가 다양한 인터넷 소스에서 가져온 내용으로 광범위한 요약 정보를 얻을 수 있습니다.
내용 선택을 위한 공동 매개 변수 추정: 매개 변수는 템플릿의 모든 항목에 대해 공동으로 학습됩니다. 이 절차는 각 주제에 대한 정보의 로컬 관련성과 전체 글 전반의 글로벌 일관성을 최적화합니다.
영화 배우와 질병이라는 두 영역의 기사를 작성하여 접근 방식을 평가합니다. 데이터 세트의 경우 위키피디어를 사용합니다. 위키피디어에는 길이와 폭의 관점에서 작성하고자 하는 것과 유사한 기사가 들어 있습니다. 이 데이터 세트의 장점은 위키피디어 기사가 명시적으로 주제별 윤곽을 그리며 구조 분석을 용이하게 한다는 점입니다. 평가 결과에서는 명시적으로 주제 구조를 모델링 하지 않는 접근 방식에 비해 구조 인식 컨텐츠 선택의 이점을 확인합니다.
2. 관련 연구
컨셉-텍스트 생성 및 텍스트-텍스트 생성은 컨텐츠 선택에 대해 매우 다른 접근 방식을 취합니다. 전통적인 컨셉-텍스트 생성에서 컨텐츠 플래너는 출력에 포함되어야 하는 정보와 이 정보가 어떻게 구성되어야 하는지에 대한 세부 템플릿을 제공합니다(Reiter and Dale, 2000). 텍스트-텍스트 생성에서 정보 조직을 위한 이러한 템플릿은 사용할 수 없습니다. 문장은 그들의 돌출 성질에 따라 선택됩니다(Mani and Maybury, 1999). 이 전략은 도메인간에 강력하고 이식성이 뛰어나지만 출력 요약은 종종 일관성 및 적용 범위 문제로 어려움을 겪습니다.
이 두 가지 접근 방식은 도메인에 특화된 텍스트-텍스트 생성 작업입니다. 이러한 작업의 예는 질문 응답의 요약 및 응답 정의 요청에서 배우의 약력 생성입니다. 일반 요약과 달리 이러한 응용 프로그램은 특정 도메인에서 필수적인 정보 유형을 특성화하는 것을 목표로 합니다. 이 특성은 세분성(아주 작은 정보 조각)에 따라 크게 다릅니다. 예를 들어, 몇몇 접근법은 약력 및 비 약력 정보를 조악하게 구별합니다(Zhou et al., 2004; Biadsy et al., 2008). 반면에 다른 사람들은 작은 이벤트(직업 및 결혼 상태)를 식별함으로써 이진 구별을 뛰어 넘습니다(Weischedel et al., 2004; Filatova and Prager, 2005; Filatova et al., 2006). 일반적으로 이러한 템플릿은 수동으로 지정되며 특정 도메인에 대해 하드 코딩됩니다(Fujii 및 Ishikawa, 2004, Weischedel et al., 2004).
우리의 연구는 이러한 접근법과 관련되어 있습니다. 그러나 컨텐츠 선택은 도메인에 따라 자동으로 유도되는 템플릿에 의해 좌우됩니다. 실험 결과에 따르면 도메인별 학습 데이터에서 관찰된 패턴은 포괄적인 텍스트에 필수적인 주제 구성에 충분한 제약을 제공합니다.
우리의 작업은 위키피디어 자료를 사용하는 최근 작업의 큰 부분과 관련이 있습니다. 이 작업의 예는 정보 추출, 온톨로지 유도 및 자원 획득이 포함됩니다(Wu and Weld, 2007; Biadsy et al., 2008; Nastase, 2008; Nastase and Strube, 2008). 우리의 초점은 위키피디어 기사의 구조를 따르는 새로운 개요 기사의 생성이라는 다른 작업에 있습니다.
3. 방식
시스템의 목표는 타이틀과 함께 포괄적인 개요 기사(예: Cancer)를 제작하는 것입니다. 주제에 관한 관련 정보는 인터넷에서 사용할 수 있지만 노이즈가 산재된 여러 페이지 사이에 흩어져 있다고 가정합니다. n 개의 문서 \(d_1\) … \(d_n\)으로 구성된 훈련 코퍼스를 제공받습니다. 동일한 도메인(예: 질병)의 \(d_i\) 각 문서는 제목과 일련의 윤곽이 지정된 섹션 \(s_{i1}\) … \(s_{im}\)으로 구성됩니다. 섹션 m의 수는 문서마다 다릅니다. 각 섹션 \(s_{ij}\)에는 대응하는 표제 \(h_{ij}\)(예: 치료)를 갖고 있습니다.
개요 기사 작성 프로세스는 세 부분으로 구성됩니다. 첫째, 전처리 단계는 템플릿을 생성하고 인터넷에서 다수의 발췌 내용을 검색합니다. 다음으로, 학습 데이터 세트를 사용하여 컨텐츠 선택 알고리즘에 대한 매개 변수를 학습해야 합니다. 마지막으로, 후보자 발췌물의 일부를 결합하여 완전한 기사를 만들 수 있습니다.
1. 전처리(Section 3.1)
사전 처리 단계에서는 주제 선택 및 쿼리 재구성에 대한 이전 작업을 활용하여 컨텐츠 선택을 위한 템플릿 및 후보 발췌 모음을 준비합니다. 템플릿 생성은 도메인당 한 번 발생해야 하며, 검색은 기사가 학습 및 애플리케이션 모두에서 생성 될때마다 발생합니다.
(a) 템플릿 유도
컨텐츠 템플릿을 만들려면 모든 문서 \(d_i\)에 대한 모든 섹션 머리글 \(h_{i1}\) … \(h_{im}\)을 묶습니다. 각 클러스터는 클러스터 내에서 가장 일반적인 제목 \(h_{ij}\)로 표시됩니다. 가장 큰 k 클러스터는 도메인별 컨텐츠 템플릿을 구성하는 주제 \(t_1\) … \(t_k\)가 되도록 선택됩니다.
(b) 검색
우리가 만들고자하는 각각의 문서에 대해 인터넷에서 템플릿 주제 \(t_j\)에 대한 발췌문 \(e_{j1}\) … \(e_{jr}\)의 집합을 검색합니다. 요청된 문서 제목과 주제 \(t_j\)를 사용하여 적절한 검색 쿼리를 정의합니다.
2. 컨텐츠 선택 학습(Section 3.2)
각 주제 \(t_j\)에 대해 주어진 발췌의 품질을 결정하기 위해 해당 주제별 매개 변수 \(w_j\)를 학습합니다. 전역 최적화를 위해 ILP 공식으로 보강된 퍼셉트론 프레임워크를 사용하여 시스템은 각 문서 \(d_i\)와 각 주제 \(t_j\)에 대한 최상의 발췌를 선택하도록 학습됩니다. 학습을 위해 가장 좋은 발췌 부분이 인간이 작성한 원본 텍스트 \(s_{ij}\)라고 가정합니다.
3. 어플리케이션(Section 3.2)
요청된 문서의 제목이 주어지면 검색 절차(1b)에서 반환된 후보 벡터에서 여러 발췌문을 선택하여 포괄적인 개요 문서를 만듭니다. 학습된 파라미터 \(w_1\) … \(w_k\)와 글로벌 최적화를 위한 동일한 ILP 공식을 사용하여 디코딩 절차를 공동으로 수행합니다. 결과는 k 개의 발췌 부분을 가진 새로운 문서로 각 주제에 대해 하나씩 있습니다.
3.1 전처리
템플릿 유도
컨텐츠 템플릿은 하나의 도메인에 있는 문서의 주제별 구조를 지정합니다. 예를 들어 배우에 대한 기사의 템플릿은 네 가지 주제 \(t_1\) … \(t_4\): 전기, 초기 생애, 경력 및 개인 생활로 구성됩니다. 이 템플릿을 사용하여 새로운 배우의 자서전을 작성하면 정보 범위가 기존의 인간이 작성한 문서와 일치하는지 확인할 수 있습니다.
관심 도메인의 문서 구성에서 일반적인 패턴을 발견함으로써 이러한 템플릿을 유도하는 것을 목표로 합니다. 선형 분할(Hearst, 1994)에서 내용 모델링(Barzilay and Lee, 2004)에 이르는 구조 유도에 대한 상당한 연구가 있었습니다. 이러한 방법의 핵심은 유사한 정보를 전달하는 텍스트 단편이 비슷한 단어 분포 패턴을 갖는다는 가정입니다. 따라서 도메인 텍스트 전체에 걸친 간단한 세그먼트 클러스터링은 컨텐츠 구조에서 강력한 패턴을 식별할 수 있습니다(Barzilay and Elhadad, 2003). 많은 문서의 단편을 포함하는 클러스터는 포괄적인 요약에 필수적인 주제를 나타냅니다. 이 접근법의 단순성과 견고함을 고려하여 템플릿 유도에 활용합니다.
모든 섹션 제목 \(h_{i1}\) … \(h_{im}\)을 클러스터링합니다(Zhao et al., 2005). 유사도 함수로는 TF * IDF를 가중치로한 코사인 유사도를 사용합니다. 통합된 주제로 산출되지 않는 “기타(miscellaneous)”클러스터 즉, 내부 유사도가 낮은(0.5보다 작은) 클러스터는 제거합니다.
학습 세트의 모든 문서에 대해 섹션 k의 평균 개수를 결정한 다음 k 개의 가장 큰 섹션 클러스터를 주제로 선택합니다. 이 주제들을 \(t_1\) … \(t_k\)로 주문합니다. 이 알고리즘은 데이터 세트에서 관찰된 쌍 관계의 최대 수와 일치하는 클러스터 사이의 전체 순서를 찾습니다. 각 주제 \(t_j\)는 클러스터 내에서 발견되는 가장 빈번한 표제(예: 원인)로 식별됩니다. 이 주제 세트는 도메인의 컨텐츠 템플릿을 형성합니다.
검색
관련 발췌문을 검색하려면 각 주제 \(t_1\) … \(t_k\)에 대해 적절한 검색 쿼리를 정의해야 합니다. 쿼리 재구성은 활발한 연구 영역입니다(Agichtein et al., 2001). 각 주제의 본문에 있는 대표 단어에서 검색 쿼리를 그리는 몇 가지 방법을 실험했습니다. 그러나 최상의 성능은 문서 제목과 주제(예: “3-M 증후군” 진단)의 결합에서 쿼리를 유도하여 제공됩니다. 이 쿼리를 사용하여 야후 검색 각 주제에 대한 처음 10개의 결과 페이지를 검색 할 수 있습니다. 이 각 페이지에서 표준화된 경계 표시기(예: <p> 태그) 사이에 텍스트 덩어리로 구성된 모든 발췌 부분을 추출합니다. 실험에서 각 페이지에서 평균 6건의 발췌 내용이 있습니다. 우리가 만들고자 하는 각 문서의 각 주제 \(t_j\)에 대해 인터넷에서 발견된 종류별 발췌 수는 다를 수 있습니다. \(e_{j1}\) … \(e_{jr}\)의 발췌 부분에 레이블을 붙입니다.
3.2 선택 모델
선택 모델은 컨텐츠 템플릿 \(t_1\) … \(t_k\)와 이전 단계에서 생성된 각 주제 \(t_j\)에 대한 후보 발췌 부분 \(e_{j1}\) … \(e_{jr}\)을 사용합니다. 그런 다음 일련의 k 발췌를 선택하여 각 주제에서 하나씩 일관된 요약을 작성합니다. 하나의 가능한 접근법은 각 발췌 \(e_{j1}\) 세트에서 개별 선택을 수행하는 것입니다. 이 전략은 일반적으로 다중 문서 요약(Barzilay et al., 1999; Goldstein et al., 2000; Radev et al., 2000)에서 사용되며, 조합 단계는 선택된 발췌 부분에서 중복을 제거합니다. 그러나 두 단계를 분리하는 것이 이 작업에 적합하지 않을 수 있습니다. 여러 단락 요약이 생성될때 적용 범위와 중복 간의 균형을 이루기가 어렵습니다. 또한 후보 발췌가 노이즈로 오염 될 수 있기 때문에 웹에서 직접 발췌한 경우에는 더 차별적인 선택 전략이 필요합니다. 모든 주제에 대한 선택 기준을 동시에 학습하는 새로운 공동 학습 알고리즘을 제안합니다. 이러한 접근 방식을 통해 로컬 적합성과 글로벌 일관성을 극대화 할 수 있었습니다. 수렴 보증을 유지하면서 구조화된 예측을 위해 쉽게 수정할 수 있으므로 퍼셉트론 프레임워크를 사용하여 이 알고리즘을 구현합니다(Daum’e III and Marcu, 2005; Snyder and Barzilay, 2007). 이 절에서는 먼저 우리 모델의 구조와 디코딩 절차를 설명합니다. 그런 다음 모든 주제 모델의 매개 변수를 공동으로 학습하는 알고리즘을 제시합니다.
3.2.1 모델 구조
모델 입력은 다음과 같습니다.
- 원하는 문서의 제목
- \(t_1\) … \(t_k\) - 컨텐츠 템플릿의 주제
- \(e_{j1}\) … \(e_{jr}\) - 각 주제 \(t_j\)에 대한 후보 발췌
또한 특징과 매개 변수 벡터를 정의합니다.
- \(φ(e_{jl})\) - 주제 \(t_j\)에 대한 l번째 후보 발췌에 대한 특징 벡터
- \(w_1\) … \(w_k\) - 각 주제 \(t_1\) … \(t_k\)에 대한 하나의 파라미터 벡터
우리 모델은 다음 두 단계를 따라 새로운 기사를 만듭니다.
랭킹
첫째, 각 개별 주제의 대표성을 토대로 발췌 후보를 순위 매김합니다. 각 주제 \(t_j\)에 대해 각 발췌 \(e_{j1}\) … \(e_{jr}\)를 점수로 맵핑하여 순위를 유도합니다.
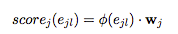
각 주제에 대한 후보자는 최고 점수에서 최저 점수까지 평가됩니다. 이 절차 후에 주제 특정 후보 벡터 내에서 발췌 \(e_{jl}\)의 위치 l은 발췌의 순위입니다.
글로벌 목표의 최적화
주제간 중복을 피하기 위해 발췌 순위를 사용하여 최종 기사를 작성하는 최적화 문제를 계산합니다. k 개의 주제가 주어진다면, 각 주제 \(t_j\)에 대해 순위가 최소화된 하나의 발췌 \(e_{jl}\)(즉, \(score_j(e_{jl})\)가 가장 높은)을 선택합니다.
최적 발췌를 선택하기 위해 정수 선형 프로그래밍(ILP)을 사용합니다. 이 프레임워크는 선택 프로세스가 여러 제약 조건에 의해 유도되는 생성 및 요약 응용 프로그램에서 주로 사용됩니다(Marciniak and Strube, 2005, Clarke and Lapata, 2007).
일련의 지시자 변수 \(x_{jl}\)을 사용하여 출력물에 포함된 발췌문을 나타냅니다. 각 발췌 \(e_{jl}\)에 대해 발췌가 최종 문서에 포함되어 있으면 해당 표시기 변수 \(x_{jl}\) = 1이고 그렇지 않으면 \(x_{jl}\) = 0입니다.
목표는 최종 문서를 위해 선택된 발췌 부분의 순위를 최소화하는 것입니다.
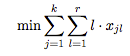
두 가지 유형의 제약 조건을 가지고 이 공식을 증가시킵니다.
배타성 제약
각 주제 \(t_j\)에 대해 정확하게 하나의 지표 \(x_{jl}\)이 0이 아닌지 확인하고자합니다. 이러한 제약 조건은 다음과 같이 공식화됩니다.
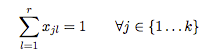
중복성 제약
또한 여러 주제에 걸쳐 중복성을 방지하고자 합니다. 주제 \(t_j\)의 발췌 \(e_{jl}\)과 주제 \(t_{j'}\)의 \(e_{j'l'}\)사이의 코사인 유사도로 \(sim(e_{jl},e_{j'l'})\)을 정의합니다. 발췌의 쌍이 0.5보다 큰 유사성을 갖지 않도록 하는 제약 조건을 도입합니다.
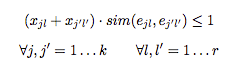
만약 \(e_{jl}\)과 \(e_{j'}\)가 코사인 유사성 \(sim(e_{jl},e_{j'l'}) > 0.5\)를 가지고 있다면 즉, \(x_{jl}\) 또는 \(x_{j'l'}\) 하나의 발췌문만 최종 문서를 위해 선택될 수 있습니다. 반대로 \(sim(e_{jl},e_{j'l'}) ≤ 0.5\)인 경우 두 발췌가 선택 될 수 있습니다.
ILP 풀이
정수 선형 프로그램 풀이는 NP-hard 입니다(Cormen et al., 1992); 그러나 실제로는 특정 ILP를 효율적으로 해결하기 위한 몇 가지 전략이 있습니다. 우리 연구에서 분기 및 바운드 알고리즘을 구현하는 효율적인 혼합 정수 프로그래밍 솔버인 lp_solve를 사용했습니다. 대규모 배낭 문제에 대한 동적 프로그래밍 근사와 같은 ILP 결과를 근사화하는 몇 가지 대안이 있습니다(McDonald, 2007).
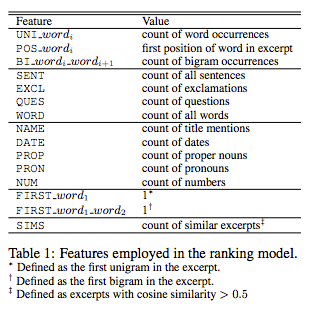
특징
표 1에서 볼 수 있듯이 우리 모델에서 선택한 대부분의 기능은 요약 작업에 사용되었습니다(Mani 및 Maybury, 1999). SIMS 기능을 제외한 모든 기능은 개별 발췌 부분에 대해 별도로 정의됩니다. 각각의 발췌 \(e_{jl}\)에 대해, SIMS 특징의 값은 \(sim(e_{jl},e_{jl'}) > 0.5\)인 동일한 토픽 \(t_j\)에서의 발췌 \(e_{jl'}\)의 수입니다. 이 기능은 주제 내의 반복 정도를 정량화하여 종종 발췌의 정확성과 관련성을 나타냅니다.
3.2.2 모델 학습
학습 데이타 생성
학습을 위해 주제 \(t_1\) … \(t_k\)와 각 문서 \(d_i\)와 주제 \(t_j\) 후보 발췌 \(e_{ji1}\) … \(e_{ijr}\)구성된 n 개의 원본 문서 \(d_1\) … \(d_n\)을 받습니다. 각 문서의 각 섹션에 대해, 금 발췌gold excerpt \(s_{ij}\)를 후보 발췌 \(e_{ij1}\) … \(e_{jir}\)의 해당 벡터에 추가합니다. 이 발췌는 학습 알고리즘의 목표를 나타냅니다. 이 알고리즘에는 주석이 달린 순위 데이터가 필요하지 않습니다. “최적”발췌에 대한 지식만 필요합니다. 그러나 학습 자료에 제공된 발췌 내용의 품질이 낮으면 시스템에 노이즈가 낍니다.
학습 절차
우리의 알고리즘은 몇 가지 순위 문제(Daum’e III and Marcu, 2005; Snyder and Barzilay, 2007)에 걸친 공동 학습을 허용하는 퍼셉트론 순위 알고리즘(Collins, 2002)의 수정입니다. 이 알고리즘에 대한 의사 코드는 그림 2에 나와 있습니다.

\(Rank(e_{ij1} ... e_{ijr},w_j)\)를 정의하는데, 이는 문서 \(d_i\)와 주제 \(t_j\)에 대한 발췌 후보 벡터 \(e_{ij1}\) … \(e_{ijr}\)에서 순위를 매깁니다. 발췌 부분은 현재 매개 변수 값을 사용하여 \(score_j(e_{jl})\)에 의해 정렬됩니다. 또한 발췌 \(e_{ij1}\)의 랭킹리스트가 주어진 발췌(주제당 하나)의 최적 선택을 찾는 \(Optimize(e_{ij1} ... e_{ijr})\)를 정의합니다. 이 함수는 3.2.1 절에 설명된 순위 및 최적화 절차를 따릅니다. 이 알고리즘은 최종 기사에서 원하는 각 주제 \(t_j\)와 연관된 하나의 k 매개 변수 벡터 \(w_1\) … \(w_k\)를 유지합니다. 초기화 하는 동안 모든 매개 변수 벡터는 0으로 설정됩니다(2 행).
최적의 매개 변수를 배우려면 이 알고리즘은 매개 변수가 수렴되거나 최대 반복 횟수에 도달 할 때까지(3 행) 학습 세트를 반복합니다. 트레이닝 세트(4 행)의 각 문서에 대해 다음 단계가 발생합니다. 첫째, 각 주제에 대한 후보 발췌가 순위 지정됩니다(5-6 행). 다음으로 ILP 최적화를 통해 해독된 후보 발췌 목록의 모든 목록에 대해 각 주제에 대해 하나의 발췌문을 선택하여 수행합니다(7 행). 마지막으로 매개 변수가 공동으로 업데이트됩니다. 각 토픽(8 행)에 대해, 선택된 발췌가 금 발췌와 유사하지 않은 경우(9 행), 해당 주제에 대한 매개 변수는 표준 퍼셉트론 업데이트 규칙(10 행)을 사용하여 업데이트됩니다. 수렴에 도달하거나 최대 반복 횟수를 초과하면 학습된 매개 변수 값이 반환됩니다(12 행).
학습의 각 단계에서 ILP를 사용하면 이전 알고리즘과 별개로 이 알고리즘이 설정됩니다. 이전 연구에서 ILP는 중복성을 제거하고 매개 변수에 대한 다른 세계적인 결정을 내리기 위한 후처리 단계로 사용되었습니다(McDonald, 2007; Marciniak and Strube, 2005, Clarke and Lapata, 2007). 그러나 학습 과정에서 완전한 디코딩 절차와 매개 변수 업데이트를 연결합니다. 우리의 공동 학습 접근법은 컨텐츠 선택을 위한 전역 디코딩 절차에 최대로 적합한 주제별 매개 변수 값을 찾습니다.
4. 실험 설정
다양한 도메인에서 자동 생성된 기사의 품질을 관찰하여 방법을 평가합니다. 요약 품질에 대한 표준 척도인 ROUGE를 사용하여 우리 시스템과 여러 기준에 의해 생성된 많은 수의 기사와 원래의 인간이 작성한 기사의 유사성을 계산합니다. 또한, 위키피디어에 제출된 시스템 생산물에 대한 편집자 반응에 대한 분석을 수행합니다.
데이타
평가를 위해 미국 영화 배우와 질병의 두 영역을 고려합니다. 이러한 영역은 요약에 대한 이전 연구에서 일반적으로 사용되어 왔습니다(Weischedel et al., 2004; Zhou et al., 2004; Filatova and Prager, 2005, DemnerFushman and Lin, 2007, Biadsy et al). 텍스트 코퍼스는 위키피디어의 해당 카테고리에서 가져온 기사들로 구성되어 있습니다. 미국 영화 배우에는 2,150편의 기사가, 질병에는 523편의 기사가 있습니다. 각 도메인에 대해 학습을 위해 기사의 90%를 무작위로 선택하고 나머지 10%를 테스트합니다. 두 도메인 모두에서 인간이 작성한 기사는 평균 4개의 주제를 포함하며 각 주제는 평균 193단어를 포함합니다.
위키피디어 기사를 항상 이용할 수 없는 현실적인 시나리오를 모델링 하기 위해, 검색 절차(섹션 3.1)에서 평가를 위해 위키피디어 출처는 제외합니다.
기준점
검색어로 사용하여(예: Bacillary Angiomatosis)이 방법은 검색 엔진에서 첫 번째로 선정된 웹 페이지를 선택합니다. 이 페이지에서 k가 전체 모델에서와 같은 방식으로 정의된 첫 번째 k 단락을 선택합니다. 페이지에 k 단락 미만인 경우 모든 단락이 선택되지만 다른 소스는 사용되지 않습니다. 이것은 우리 시스템의 산출량에 필적하는 크기의 문서를 산출합니다. 단순함에도 불구하고 이 기준은 순진하지 않습니다. 단일 문서에서 자료를 추출하면 결과물이 일관되고 페이지 검색 엔진에 의해 높은 순위가 매겨지기 때문에 주제에 대한 포괄적인 개요가 포함될 수 있습니다.
두 번째 기준인 템플릿 없음은 템플릿을 사용하여 원하는 주제를 지정하지 않습니다. 따라서 컨텐츠 선택에는 제약이 없습니다. 대신 분류자가 약력 문장을 구분할 수 있도록 학습된 약력 생성에 대한 이전 연구의 단순화된 형태를 따릅니다(Zhou et al., 2004; Biadsy et al., 2008).
이 경우 도메인별 텍스트를 구별하기 위해 분류자를 학습합니다. 긍정적인 학습 데이터는 주어진 도메인 코퍼스의 모든 주제에서 추출됩니다. 부정적인 학습 데이터를 찾으려면 기사 제목만 검색 쿼리로 사용하여 풀 모델(섹션 3.1 참조)에서와 같이 검색 절차를 수행합니다. 원본 기사와의 유사성이 매우 낮은 발췌문이 부정적인 예로 사용됩니다. 디코딩 절차 중에 동일한 검색 절차를 사용합니다. 그런 다음 각 발췌 내용을 관련성이 있거나 관련성이 없는 것으로 분류하고 관련성 신뢰도 점수가 가장 높은 비 중복 발췌문을 선택합니다.
세 번째 기준인 연결 끊어짐은 전체 시스템과 마찬가지로 순위 퍼셉트론 프레임워크를 사용합니다. 그러나 학습 및 디코딩 중에 최적화 단계를 수행하는 대신 각 주제에 대해 가장 높은 순위의 발췌문을 선택하기만 하면 됩니다. 이것은 각 섹션에 대한 표준 선형 분류와 개별적으로 동일합니다.
이러한 기준선 외에도 오라클 시스템과 비교합니다. 인간이 작성한 기사에 있는 각 주제에 대해 오라클은 인간이 작성한 텍스트와 가장 유사한 코사인 유사성을 가진 전체 모델의 발췌 목록에서 발췌문을 선택합니다. 이 발췌는 사용 가능한 결과에서 최적의 자동 선택이므로 발췌 선택 작업의 상한을 나타냅니다. 일부 기사는 템플릿에 있는 주제를 넘어선 추가 주제를 포함합니다. 이 경우 오라클 시스템은 우리의 알고리즘보다 긴 기사를 생성합니다.
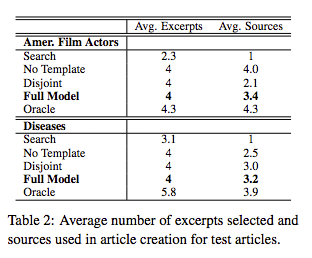
표 2는 전체 모형과 각 기준선에 의해 작성된 기사에서 사용된 발췌의 평균 수와 출처를 보여줍니다.
자동 평가
결과 개요 문서의 품질을 평가하기 위해 원래의 인간 저작 문서와 비교합니다. 인간이 작성한 텍스트와의 근접성이 요약 품질을 나타내는 지표라고 가정하는 DUC(Document Understanding Conferences)에서 사용되는 평가 척도인 ROUGE를 사용합니다. 공개적으로 이용 가능한 ROUGE 툴킷(Lin, 2004)을 사용하여 ROUGE-1에 대한 재현율, 정확도 및 F-점수를 계산합니다. Wilcoxon Signed Rank Test를 사용하여 통계적 유의성을 결정합니다.
인간의 편집 분석
자동 평가 외에도 인간의 시스템 제작 기사에 대한 반응을 연구합니다. 이 목표를 달성하기 위해 자동으로 글을 작성하여 위키피디어 자체에 삽입하고 위키피디어 편집자의 피드백을 검토합니다. 특정 기사의 선택은 유효한 기사를 작성하기 위해 인터넷에서 충분한 정보를 얻을 수있는 “스터브”상태에 있는 주제를 찾아야 할 필요성 때문에 제약을 받습니다. 일정 기간이 경과한 후에 기사 편집을 분석하여 전반적인 편집자 반응을 결정했습니다. 질병 범주의 15개 기사에 대한 결과를 보고합니다.
위키피디어는 실제 리소스이기 때문 우리의 기준 시스템을 위한 절차를 반복하지 않습니다. 이전에 품질이 좋지 않았던 시스템의 기사를 추가하는 것은 부적절한 결과를 초래할 수 있습니다(특히 질병). 따라서 이 분석을 엄격한 기술 연구 라기 보다는 추가적인 관찰로서 제시합니다.
5. 결과
자동 평가
이 평가 결과는 표 3에 나와 있습니다.
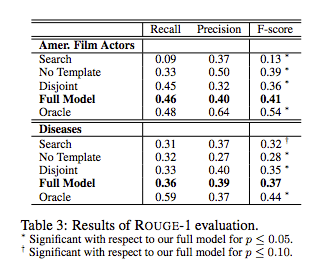
전체 모델이 모든 기준선보다 우수한 성능을 보입니다. 분리 기준선을 뛰어 넘음으로써 공동 분류의 이점을 입증합니다. 또한 전체 기준 모델과 다른 기준선과 비교한 분리 기준선의 높은 성능은 구조 인식 컨텐츠 선택의 중요성을 보여줍니다. 시스템 성능에 대한 상한을 나타내는 오라클 시스템이 잘 작동합니다. 나머지 기준선에는 다른 결함이 있습니다. 서식 파일 없음 기준에 의해 생성된 문서는 다양한 주제 선택을 보장하는 제약이 없으므로 범위를 희생시키면서 단일 주제에 집중하는 경향이 있습니다. 반면에 검색 기준의 성능은 극적으로 다릅니다. 이것은 예상됩니다. 이 기준선은 검색 엔진과 개별 웹 페이지 모두에 크게 의존합니다. 검색 엔진은 관련 페이지의 순위를 올바르게 지정해야 하며 웹 페이지는 중요한 자료를 먼저 제공해야 합니다.
인간의 편집 분석
편집 패턴에 대한 관찰 결과는 표 4에 나와 있습니다.
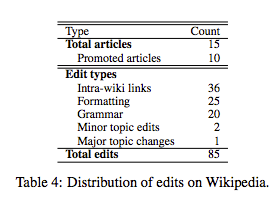
이 기사는 위키피디어에서 5개월에서 11개월까지 남아 있었습니다. 문서 모두는 편집되었으나 품질 부족으로 인해 삭제된 기사는 없었습니다.
또한, 재료의 품질과 커버리지를 바탕으로한 10개의 자동화된 위키피디어에 의해 인간 편집자들에 의해 자동으로 만들어진 기사들이 발간되었습니다. 정보는 관련되지 않은 세개의 부분과 두개의 작은 조각으로 나뉘어져 있었습니다. 가장 일반적인 변화는 본문의 다른 위키피디어 문서에 대한 링크를 포맷하고 도입하는 것에 대한 작은 편집 정도였습니다.
6. 결론
이 글에서는 웹에서 관련 자료를 선택하고 하나의 일관된 텍스트로 구성하여 여러 단락 개요 기사를 작성하는 방법을 조사했습니다. 우리의 알고리즘은 구조에 독립적인 접근법에 비해 상당한 이득을 얻습니다. 또한, 우리 결과는 독립적으로 학습된 로컬 분류기를 능가하는 구조화된 분류의 이점을 입증합니다. 전반적으로 평가 결과와 인간 편집의 분석 결과는 제안된 방법이 포괄적인 개요 기사를 효과적으로 생성 할 수 있음을 확인합니다. 이 연구는 향후 연구를 위한 몇 가지 방향을 제시합니다. 질병 및 미국 영화 배우는 공정한 일관된 기사 구조를 보여 주며, 이는 간단한 템플릿 작성 프로세스에 의해 성공적으로 캡처됩니다. 그러나 구조적 다양성을 나타내는 범주의 경우 정확한 템플릿을 생성하려면 더 정교한 통계적 접근이 필요할 수 있습니다. 유망한 방향은 RST(Mann and Thompson, 1988)와 같은 계층적 담론 형식을 고려하여 템플릿 기반 접근 방식을 보완하는 것입니다.