
BERT 톺아보기
2019년 1월 24일 KorQuAD 리더보드 추가
2018년 12월 31일 시각화 추가
2018년 12월 22일 한글 모델 추가
2018년 12월 17일 초안 작성
본 내용을 바탕으로 한글 모델의 성능을 실험하기 위해 KorQuAD에 참여하여 state-of-the-art를 달성하는 좋은 성과를 거두었습니다. EM, F1 모두 1위를 기록함은 물론, Human Performance를 능가하는 첫 번째 모델을 제출하였고, 회사 홍보팀의 제안을 받아 홍보팀의 도움으로 다음과 같이 보도자료를 배포하였습니다.
보도 자료: 카카오 AI, 한국어 독해능력 평가 인간 앞질렀다

서론

BERT는 Bidirectional Encoder Representations from Transformers의 약자로 올 10월에 논문이 공개됐고, 11월에 오픈소스로 코드까지 공개된 구글의 새로운 Language Representation Model 이다. 그간 높은 성능을 보이며 좋은 평가를 받아온 ELMo를 의식한 이름에, 무엇보다 NLP 11개 태스크에 state-of-the-art를 기록하며 요근래 가장 치열한 분야인 SQuAD의 기록마저 갈아치우며 혜성처럼 등장했다.
BERT is a method of pre-training language representations, meaning that we train a general-purpose “language understanding” model on a large text corpus ( BooksCorpus and Wikipedia), and then use that model for downstream NLP tasks ( fine tuning ) that we care about (like question answering — SQuAD).2
BERT는 Sebastian Ruder가 언급한 NLP’s ImageNet에 해당하는 가장 최신 모델 중 하나로, 대형 코퍼스에서 Unsupervised Learning으로 General-Purpose Language Understanding 사전 모델을 구축하고Pre-training Supervised Learning으로 Fine-tuning 해서 QA, STS등의 하위downstream NLP 태스크에 적용하는 Semi-Supervised Learning 모델이다. ULMFiT이 가능성을 보여주었고, 이후 ELMo, OpenAI GPT등이 놀라운 성능을 보여주면서 그 진가를 인정받았다. BERT의 경우 무려 11개의 NLP 태스크에서 state-of-the-art를 기록하면서 뉴욕 타임스의 지면을 장식하기도 했다.
이 글에서는 BERT의 특징과 구조를 하나씩 살펴보고 한국어로 서비스 적용을 위해 실험을 진행한 부분까지 자세히 살펴보면서 BERT를 파헤쳐보도록 한다. 이 글을 정리하는데는 Dissecting BERT 시리즈에 매우 큰 영감을 받았고 이 글의 많은 부분에 차용했음을 일러둔다.
모델

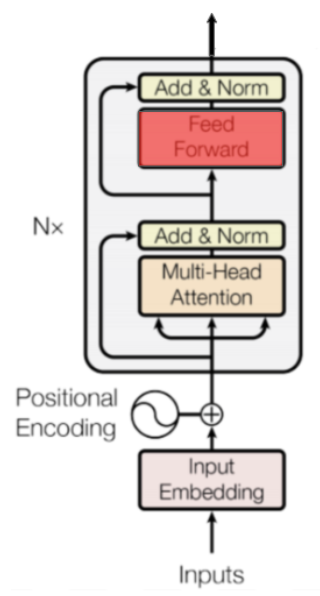
먼저, BERT의 모델은 Transformer를 기반으로 한다. 이 그림은 Transformer 논문에 있는 모델 아키텍처이며 인코더-디코더 모델은 언뜻 보기엔 상당히 복잡한 편이다. BERT는 이 중에서도 왼쪽, 인코더만 사용하는 모델이며 따라서 여기서는 인코더에 대한 부분을 상세히 살펴보도록 한다. Transformer 모델 전체에 대한 내용은 Michał Chromiak의 글과 Harvard NLP의 구현을 추천하며, 여기서는 인코더의 가장 아래 레이어 부터 차례대로 살펴보도록 한다.
Positional Encoding
먼저 Transformer 부터 얘기해보자. Transformer의 가장 큰 특징은 Convolution도, Recurrence도 사용하지 않는다는 점이다. Transformer 논문에는 아래와 같이 언급하고 있다.3
Since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence. (Vaswani et al., Attention Is All You Need, 2017)
토큰의 상대적 또는 절대적 위치에 대한 정보를 주입하는데 이를 Positional Encoding 이라 하며 앞서 Transformer 모델 그림에 잘 나와 있다. 이는 사인 함수sinusoid function를 이용한 아래 수식의 결과를 더해 네트워크가 토큰의 상대적 위치와 관련한 정보를 학습할 수 있게 한다.
\(\begin{aligned} \text{PE}_{(pos,2i)} = sin(pos/10000^{2i/d_{model}}) \\ \text{PE}_{(pos,2i+1)} = cos(pos/10000^{2i/d_{model}}) \end{aligned}\)4
수식을 풀어서 계산해보면 좌상단에서 우하단에 이르기까지 L 형태로 파동의 변화가 큰 형태를 띈다. 100차원 임베딩, 10개 토큰을 가정해 사인 함수를 히트맵으로 표현해 아래와 같이 직접 그려봤다.5

Positional Encoding은 이를 따로 이용할 수 있는 구현도 존재한다. 만약 동일하게 사인 함수를 이용한 포지션 정보를 주입하고 싶다면 PyTorch로 구현한 Positional-Encoding 구현을 참고할 수 있다.
Input Embeddings
그러나 BERT는 Transformer와 달리 Positional Encoding을 사용하지 않고 대신 Position Embeddings를 사용한다. 여기에 Segment Embeddings를 추가해 각각의 임베딩, 즉 3개의 임베딩을 합산한 결과를 취한다.

이를 코드로 나타내면 아래와 같다.
e = self.tok_embed(x) + self.pos_embed(pos) + self.seg_embed(seg)
pos는 각 토큰의 위치 정보. 위치에 따라 차례대로 값이 부여되는 range(0, max_len)이며 seg는 토큰 타입. 입력 문장의 종류에 따라 각각 다른 값을 부여한다. 여기서는 두 문장을 [SEP]로 구분해 입력했고 첫 번째 문장 위치에는 0, 두 번째 문장 위치에는 1을 시퀀스 길이만큼 부여했다. 이제 이 값에 대한 각각의 임베딩을 얻어와 합산하고 여기에 LayerNorm & Dropout 한 최종 결과를 인코더 블럭의 입력값으로 한다.
Encoder Block
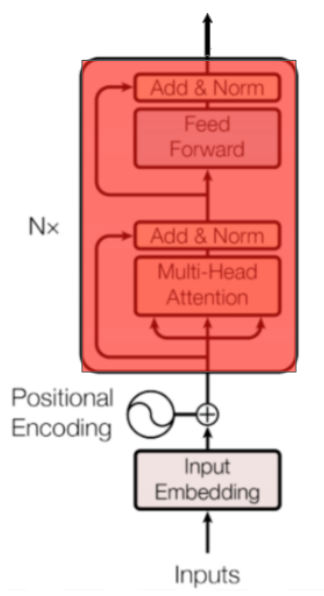
BERT는 \(N\)개의 인코더 블럭을 지니고 있다. Base 모델은 12개, Large 모델은 24개로 구성되는데, 이는 입력 시퀀스 전체의 의미를 \(N\)번 만큼 반복적으로 구축하는 것을 의미한다. 당연히 인코더 블럭의 수가 많을수록 단어 사이에 보다 복잡한 관계를 더 잘 포착할 수 있을 것이다.
인코더 블럭은 이전 출력값을 현재의 입력값으로 하는 RNN과 유사한 특징을 지니고 있다. 따라서 이 부분은 병렬 처리가 아닌 Base 모델은 12번, Large 모델은 24번, 전체가 Recursive하게 반복 처리되는 형태로 구성되며 블럭내에서 각각의 입력과 처리 결과는 도식에서 보는 바와 같이 매 번 Residual connections로 처리하여 이미지 분야의 ResNet이 보여준 것 처럼 그래디언트가 non-linear activations를 거치지 않고 네트워크를 직접 흐르게 하여 Exploding 또는 Vanishing Gradients 문제를 최소화 하고자 했다.
Multi-Head Attention
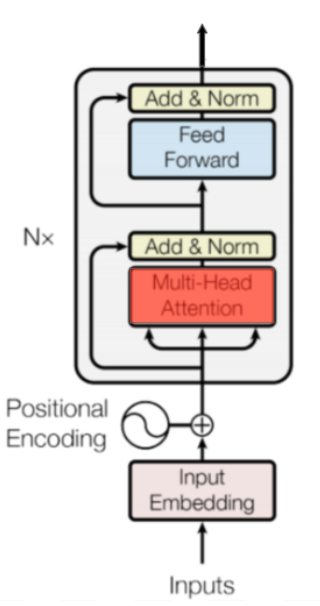
인코더 블럭의 가장 핵심적인 부분은 Multi-Head Attention 이다. 말 그대로 헤드가 여러개인 어텐션을 뜻하는데, 서로 다른 가중치 행렬을 이용해 어텐션을 \(h\)번 계산한 다음 이를 서로 연결Concatenates한 결과를 갖는다.
\(\begin{aligned} \text{MultiHead}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) &= [\text{head}_1; \dots; \text{head}_h]\mathbf{W}^O \\ \text{where head}_i &= \text{Attention}(\mathbf{Q}\mathbf{W}^Q_i, \mathbf{K}\mathbf{W}^K_i, \mathbf{V}\mathbf{W}^V_i) \end{aligned}\)4
BERT-Base 모델의 경우 각각의 토큰 벡터 768차원을 헤드 수 만큼인 12등분 하여 64개씩 12조각으로 차례대로 분리한다. 여기에 Scaled Dot-Product Attention을 적용하고 다시 768차원으로 합친다. 그렇게 되면 768차원 벡터는 각각 부위별로 12번 Attention 받은 결과가 된다. Softmax는 \(e\)의 \(n\)승으로 계산하므로 변동폭이 매우 크며, 작은 차이에도 쏠림이 두드러지게 나타난다. 즉, 값이 큰 스칼라는 살아남고, 작은 쪽은 거의 0에 가까운 값을 multiply 하게 되어 배제되는 결과를 낳는다.
Scaled Dot-Product Attention
Multi-Head Attention은 Scaled Dot-Product Attention을 \(h\)번 계산한 결과의 Concatenates 이다.
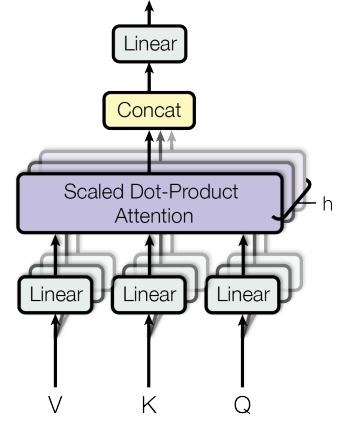
Scaled Dot-Product Attention은 입력값으로 Q, K, V 세 개를 받는다. 이는 입력값에 대한 플레이스 홀더로 맨 처음에는 임베딩의 fully-connected 결과, 두 번째 부터는 RNN과 유사하게 이전 인코더 블럭의 결과를 다음 인코더 블럭의 입력으로 사용한다. 원래 Transformer에서 Q는 주로 디코더의 히든 스테이트, K는 주로 인코더의 히든 스테이트, V는 K에 어텐션을 부여 받은 Normalized Weights가 되며, 초기값은 V와 K가 동일하다. 그러나 BERT는 디코더를 사용하지 않으며 Q, K, V의 초기값이 모두 동일하다. 물론 저마다 각각 다른 초기화로 인해 실제로는 서로 다른 값에서 출발하지만 입력값의 구성은 동일하다. BERT는 이처럼 동일한 토큰이 문장내의 다른 토큰에 대한 Self-Attention 효과를 갖는다.
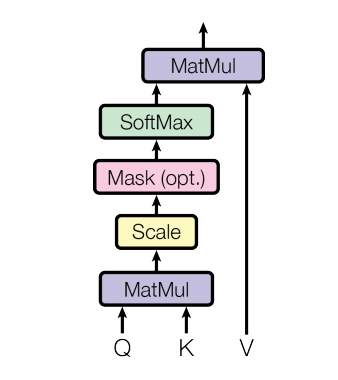
Q, K, V에 대한 Scaled Dot-Product Attention 수식은 아래와 같다.
\[{ Attention } ( Q , K , V ) = \operatorname { softmax } \left( \frac { Q K ^ { T } } { \sqrt { d _ { k } } } \right) V\]이를 도식화 하면 아래와 같다.
 4
4
Masked Attention
위 도식에 Mask는 Optional로 되어 있으며, BERT 공식 구현을 살펴보면 아래와 같다.
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and -10000.0 for masked positions.
adder = (1.0 - tf.cast(attention_mask, tf.float32)) * -10000.0
BERT의 경우 Inference시에는 제로 패딩으로 입력된 토큰에 대해서는 항상 마스킹 처리를 하며 이 토큰에 대해서는 페널티를 부과해 어텐션 점수를 받지 못하도록 구현되어 있다.
Position-wise Feed-Forward Network
이제 마지막으로 어텐션의 결과를 Position-wise Feed-forward Network로 통과한다.
\[{ FFN } ( x ) = \max \left( 0 , x W _ { 1 } + b _ { 1 } \right) W _ { 2 } + b _ { 2 }\]두 개의 Linear Transformations로 구성되어 있으며, Transformer는 그 사이에 ReLU activation을 적용했고, BERT는 보다 부드러운 형태인 GELU7를 적용했다. 아래 그래프에서 보는바와 같이 GELU는 음수에 대해서도 미분이 가능해 약간의 그래디언트를 전달할 수 있다.

그런데 Tranformer 논문을 보면,
While the linear transformations are the same across different positions, they use different parameters from layer to layer. Another way of describing this is as two convolutions with kernel size 1.
라고 언급하고 있다. 커널 사이즈가 1인 두 개의 컨볼루션을 통과하면 동일한 결과를 얻을 수 있다고 했고, 이로 인해 공식 코드가 공개되기 전 초기 구현에는 컨볼루션으로 처리한 구현이 많이 남아 있다. 카카오 브레인 박규병님의 코드를 보면 아래와 같이 두 번의 커널 사이즈 1 컨볼루션을 중첩하고 입력과의 Residual connection으로 처리했다.
# Inner layer
params = {"inputs": inputs, "filters": num_units[0], "kernel_size": 1,
"activation": tf.nn.relu, "use_bias": True}
outputs = tf.layers.conv1d(**params)
# Readout layer
params = {"inputs": outputs, "filters": num_units[1], "kernel_size": 1,
"activation": None, "use_bias": True}
outputs = tf.layers.conv1d(**params)
# Residual connection
outputs += inputs
또 다른 PyTorch 구현을 보면 커널 사이즈를 3으로 주어 주변 컨텍스트의 정보를 보다 더 잘 모으도록 해 성능을 높이는 트릭을 사용했다.
layers.append(Conv(*s, kernel_size=3, pad_type=padding))
우리팀 카카오 신명철님이 NER 실험 중 기대한 만큼의 성능이 나오지 않아 이 부분에 대해 문의하였고, 필터 사이즈를 3으로 높이면 컨텍스트 정보가 보다 더 잘 표현된다는 피드백을 받기도 했다.
Setting the filter size to 3 essentially takes the context information as you rightly pointed out.
이 처럼 커널 사이즈가 클때 인코더 블럭이 반복되면 주변 컨텍스트 정보를 점점 더 모아올 수 있어 성능에 도움이 된다고 얘기 한다.
A filter of width 3 allows interactions to happen with adjacent time steps to improve performance.
Building the Mighty Transformer for Sequence Tagging in PyTorch : Part I
보다 자세한 사항은 위 링크의 미디엄 글을 추천한다.
BERT 구현에 이르러서는 더 이상 컨볼루션 트릭은 사용하지 않고 공식 코드를 포함해 모든 구현이 Feed-forward Network를 사용하는 방식으로 처리하고 있다.
# The activation is only applied to the "intermediate" hidden layer.
with tf.variable_scope("intermediate"):
intermediate_output = tf.layers.dense(
attention_output,
intermediate_size,
activation=intermediate_act_fn,
kernel_initializer=create_initializer(initializer_range))
# Down-project back to `hidden_size` then add the residual.
with tf.variable_scope("output"):
layer_output = tf.layers.dense(
intermediate_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
layer_output = dropout(layer_output, hidden_dropout_prob)
layer_output = layer_norm(layer_output + attention_output)
prev_output = layer_output
all_layer_outputs.append(layer_output)
아래는 카카오 브레인 이동현님의 PyTorch 구현으로 코드가 매우 깔끔하여 읽기 쉽다. 마찬가지로 각 포지션별 Fully-connected로 처리했고, 다음 스텝에서 Residual connection으로 처리한다.
class PositionWiseFeedForward(nn.Module):
""" FeedForward Neural Networks for each position """
def __init__(self, cfg):
super().__init__()
self.fc1 = nn.Linear(cfg.dim, cfg.dim_ff)
self.fc2 = nn.Linear(cfg.dim_ff, cfg.dim)
def forward(self, x):
# (B, S, D) -> (B, S, D_ff) -> (B, S, D)
return self.fc2(gelu(self.fc1(x)))
학습
BERT 학습 방식의 가장 큰 특징은 Bidirectional 하다는 점이다. 이는 OpenAI GPT와 구분되는 뚜렷한 차이점으로, 원래 Transformer는 Bidirectional 하다. 하지만 이후 출현하는 단어의 예측 확률을 계산해야 하는 Statistical Language Model은 Bidirectional 하게 구축할 수 없다.
Language modeling is the task of assigning a probability to sentences in a language. […] Besides assigning a probability to each sequence of words, the language models also assigns a probability for the likelihood of a given word (or a sequence of words) to follow a sequence of words
— Page 105, Neural Network Methods in Natural Language Processing, 2017.8
따라서 BERT는 이 문제를 다른 형태의 문제로 전환해 Bidirectional이 가능하게 했다. 여기에는 두 가지 방식이 사용되었는데, Masked Language Model과 Next Sentence Prediction이다. 이를 위해 BERT는 Input Embeddings에 특별한 식별자를 추가했다. 앞서 Input Embeddings 항목에서도 확인할 수 있는 [CLS]와 [SEP]이 그것이다.9
[SEP]는 문장의 끝을 나타내는 식별자로 두 문장을 구분하는 역할로도 쓰인다. 이를 통해 QA등의 문제 해결과 Pre-training시 Next Sentence Prediction 문제를 해결하는데 사용한다. 또한 문장의 맨 앞에는 클래스를 뜻하는 [CLS]를 추가했다. 이를 통해 분류 문제Classification Tasks를 해결하는데 사용하며 아래 성능 항목에서 볼 수 있는 두 문장의 유사도를 판별하는데도 이 레이어의 벡터를 사용한다.
Masked Language Model
Masked Language Model은 문장의 다음 단어를 예측하는 것이 아니라 문장내 랜덤한 단어를 마스킹하고 이를 예측하도록 하는 방식으로 Word2Vec의 CBOW 모델과 유사하다. 하지만 MLM은 Context 토큰을 Center 토큰이 되도록 학습하고 Weights를 벡터로 갖는 CBOW와 달리, 마스킹된 토큰을 맞추도록 학습한 결과를 직접 벡터로 갖기 때문에 보다 직관적인 방식으로 볼 수 있다. 마스킹은 전체 단어의 15% 정도만 진행하며, 여기에는 재밌게도 모든 토큰을 마스킹 하는게 아니라 80% 정도만 <MASK>로 처리하고 10%는 랜덤한 단어, 나머지 10%는 정상적인 단어를 그대로 둔다.
<MASK> 토큰에 대해서만 학습한다면 Fine-tuning시 이 토큰을 보지 못할 것이고 아무것도 예측할 필요가 없다고 생각해 성능에 영향을 끼칠 것이다. 때문에 <MASK> 토큰이 아닌 것도 예측하도록 학습하여 문장의 모든 단어에 대한 문맥 표현Contextual Representation이 학습되도록 한다.
Word2Vec의 경우 Softmax의 연산 비용이 높기 때문에 Hierachical Softmax 또는 Negative Sampling을 사용하는데, BERT는 전체 Vocab Size에 대한 Softmax를 모두 계산한다. 구글에서 공개한 영문 학습 모델의 Vocab Size는 30,522개로, Output Size는 Vocab Size와 동일한 갯수의 Linear Transformation 결과의 Softmax를 정답으로 한다. 따라서, Loss는 정답 벡터 위치와 Vocab Size 만큼의 Softmax 차이가 된다. 한편 한글 모델의 경우에는 형태소 분석 결과가 10만개를 넘어가는 경우가 흔하므로 학습에 더욱 오랜 시간이 걸린다.
Next Sentence Prediction
Next Sentence Prediction은 두 문장을 주고 두 번째 문장이 코퍼스 내에서 첫 번째 문장의 바로 다음에 오는지 여부를 예측하도록 하는 방식이다. 이 방식을 사용하는 이유는 BERT는 Transfer Learning으로 사용되고 QA와 Natural Language Inference(NLI)등의 태스크에서는 Masked Language Model로 학습하는 것 만으로는 충분하지 않았기 때문이다. 두 문장이 실제로 이어지는지 여부는 50% 비율로 참인 문장과 랜덤하게 추출되어 거짓인 문장의 비율로 구성되며, [CLS] 벡터의 Binary Classification 결과를 맞추도록 학습한다.
임베딩
ELMo를 포함한 BERT의 가장 큰 특징은 다이나믹 임베딩이라는 점이다. 이는 기존 Word2Vec, GloVe와 구분되는 가장 뚜렷한 특징으로 문장 형태와 위치에 따라 동일한 단어도 다른 임베딩을 갖게 되어 이를 통해 중의성을 해소할 수 있다. 예를 들어 “bank account”와 “bank of the river”의 bank는 Word2Vec 또는 GloVe에서는 동일한 벡터를 갖는다. 그러나 이 단어는 문맥에 따라 전혀 다른 의미를 지녀야 하며 실제로 ELMo 또는 BERT에서는 전혀 다른 벡터를 갖는다.
아래 예제에서는 1) 나는 너를 사랑해 2) 나는 너를 사랑했다 3) 사랑 누가 말했나. 이 세 문장에 대한 형태소 분석 결과를 입력값으로 코사인 디스턴스를 확인했다.
sentences = [
'나 는 너 를 사랑 하다 여',
'나 는 너 를 사랑 하다 였 다',
'사랑 누 가 말하다 였 나',
]
(q_length, q_tokens, q_embedding, q_ids) = bc.encode(sentences)
love_1 = q_embedding[0][5]
love_2 = q_embedding[1][5]
love_3 = q_embedding[2][1]
spatial.distance.cdist([love_2, love_3], [love_1], metric='cosine')
--
array([[0.0546998 ],
[0.52740145]])
모두 동일하게 ‘사랑’ 위치에 대한 워드 임베딩 값을 취했고 코사인 디스턴스를 출력했다. 이 중 문장이 비슷한 1번과 2번의 ‘사랑’ 벡터는 매우 가까운 거리로 나타난다. 반면, 문장이 전혀 다른 3번은 동일한 ‘사랑’이라도 거리가 상당히 멀다.
Weighted Sum
이번에는 2번, 3번 ‘사랑’ 벡터의 단순 Sum으로 1번 ‘사랑’ 벡터와의 거리를 측정해본다.
spatial.distance.cdist([love_2 + love_3], [love_1], metric='cosine')
--
array([[0.17104624]])
두 벡터 Sum과의 거리는 0.17 정도다. 이 중 거리가 가까운 2번 벡터에 가중치를 부여한 Weighted Sum과의 거리를 살펴본다.
spatial.distance.cdist([love_2 * 10 + love_3], [love_1], metric='cosine')
--
array([[0.05463206]])
거리가 훨씬 가까워졌다. 반대로 거리가 먼 3번 벡터에 가중치를 부여해본다.
spatial.distance.cdist([love_2 + love_3 * 10], [love_1], metric='cosine')
--
array([[0.45999701]])
더 멀어지는 것을 확인할 수 있다. 코사인 디스턴스는 앵글을 측정하기 때문에 벡터가 커져도 거리는 동일하며, 아래는 벡터를 10배 더 크게 해도 동일한 거리를 나타내는 경우를 보여준다. 보다 자세한 내용은 코사인 유사도의 의미에서 확인할 수 있다.
spatial.distance.cdist([(love_2 + love_3) * 10], [love_1], metric='cosine')
--
array([[0.17104624]])
Sentence Representation
bert-as-service를 만든 Han Xiao가 효율적인 Sentence Representation을 위해 다양한 실험을 했다. BERT는 Fine-tuning 하지 않고도 ELMo처럼 fixed feature vectors를 추출하여 Pre-trained Contextual Embeddings를 활용할 수 있는데, 이를 문장 단위로 mean을 취하여 Sentence Representation으로 간주했다. 실제로 이 방식은 최근까지 여러 연구와 논문에서 주로 사용되는 Representation이지만 BERT 논문 저자는 이 방식에 부정적인 견해를 보인다.
we never suggested that this will generate meaningful sentence representations.
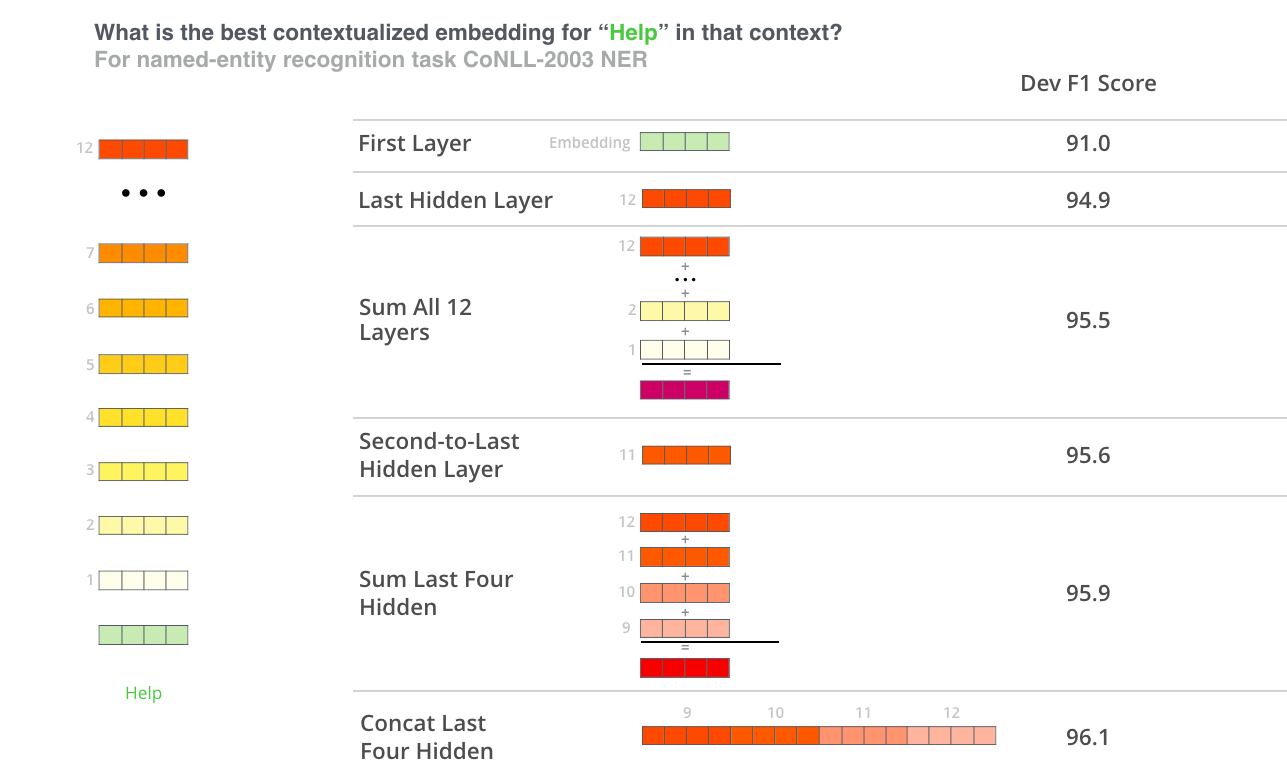
BERT의 경우 Classification을 위한 [CLS] 벡터를 따로 갖고 있으며, 각각의 벡터가 토큰의 의미를 정확히 1:1로 표현한다고 보기는 어렵다. 따라서 분류 문제에서 어떤 레이어가 좋은 Representation인지 차원 축소dimensionality reduction을 통해 시각화를 진행했고, 결과는 아래와 같다.
BERT-Base 모델의 인코더 블럭은 12개이며 각각의 출력 결과를 차례대로 시각화 했다. pooling_layer=-1은 출력에 가장 가까운 레이어이고, 지나치게 타겟과는 편향된 결과를 보인다. 만약 Fine-tuning을 하지 않고 Pre-trained 모델을 그대로 사용한다면 좋은 Representation으로 보기 어렵다. 여기서는 입력에 가장 가까운 첫 번째 레이어 pooling_layer=-12가 워드 임베딩에 가장 유사한 모습을 보였고, 분류에서는 이를 이용한다면 가장 좋은 성능을 얻을 수 있을 것으로 보인다.

NER 태스크의 경우 논문에는 마지막 4개 레이어를 Concatenates 했을때 Fine-tuned 모델과 거의 차이가 없는 결과를 보였다고 보고한바 있다. 이를 도식화 하면 아래와 같다.
성능
MRPC
카카오 브레인 이동현님의 PyTorch 구현을 이용해 MRPC 태스크(두 문장의 유사도 판별)에 대해 Fine-tuning하고 성능을 측정했다.

논문 구현에는 Sentence Pair Classification에서 학습 항목에서 확인한 바 있는 첫 번째 레이어 [CLS]의 벡터로 판별하도록 되어 있고 동일한 구현으로 아래와 같은 결과를 얻을 수 있었다.

GLUE 벤치마크에서 BERT는 Base 모델이 88.9, Large 모델은 89.3으로 등록되어 있는데 이동현님이 페이스북 댓글로 test set 임을 알려주셨고, dev set의 경우 구글 공식 repo에서 MRPC 태스크에 아래 수치로 표기되어 있다.
***** Eval results *****
eval_accuracy = 0.845588
eval_loss = 0.505248
global_step = 343
loss = 0.505248
eval_accuracy의 경우 우리가 구현한 결과에서 완전히 동일하게 재현할 수 있었고, PyTorch 구현이 매우 잘 동작하고 있음을 보여준다. fine-tuning에 불과 5분 정도의 시간을 투자해 이 정도의 결과를 얻었다는 점은 매우 고무적이다.
IMDB
IMDB Sentimental Analysis의 경우 매우 좋은 결과를 확인할 수 있다. CNN 또는 RNN으로 구현할 경우 85% 수준에 머무르고 그 이상 성능을 높이는 일은 매우 어려운데 BERT는 단순히 Pre-trained 모델을 Fine-tuning 하는 만으로도 93.3%에 달하는 결과를 얻을 수 있었다.

결과 또한 valid, test의 차이가 거의 없을 정도로 안정적이다. 현재 NLP-progress에 등록된 state-of-the-art는 다름 아닌 Sebastian Ruder가 참여한 ULMFiT(Howard et al., 2018) 모델로 95.4%를 기록하고 있는데, BERT의 경우 아무런 튜닝 작업 없이도 거의 state-of-the-art에 근접한 매우 뛰어난 성능을 확인할 수 있다.
네이버 영화 리뷰
얼마전 카카오 한글 형태소 분석기를 공개한 우리팀 카카오 임재수님의 도움으로 BERT의 한국어 코퍼스 학습을 진행했다. 학습 데이터셋으로 세종 코퍼스를 카카오에서 패치한 문종 코퍼스를 포함해 다양한 한글 데이터셋의 형태소 분석 결과를 준비했고, 처음부터 Pre-training을 진행했다.
Tesla V100 4장으로 약 2주간의 학습을 마치고, Pre-trained 한글 모델을 이용해 마찬가지로 Fine-tuning 하고 성능을 확인했다. 네이버 영화 코퍼스를 이용했고, 다양한 글에서 83% ~ 85%에 달하는 결과를 찾아볼 수 있는 데이터셋이다.

BERT로 88.77% 결과를 얻을 수 있었다.
형태소 분석에는 카카오 내부에서 사용중인 형태소 분석기 DHA2를 사용했으며, Pre-trained 모델의 성능에 따라 최대 2% 까지 성능 차이가 나기도 했다. Pre-trained 코퍼스는 대부분이 문어체로, 평가에 사용된 리뷰의 경우 구어체라 OOV가 많이 나왔음에도 불구하고 좋은 결과를 확인할 수 있다. 만약 문어체 모델을 사용했다면 훨씬 더 좋은 결과가 나올거라 예상된다.
시각화
BERT가 사용하는 Transformer 모델은 이미 2017년에 출시되어 다양한 실험 및 분석 도구가 존재한다. 여기서는 그 중에서도 어텐션의 주요 특징이기도 한 직관적인 시각화로 해석interpretable에 집중해보도록 한다. 블랙박스에 가까운 ML 알고리즘에 있어 Interpretable은 매우 중요한 문제이며 개인적으로 Interpretable Machine Learning은 올해 가장 인상적으로 읽었던 eBook이기도 하다.
다행히 구글 공식 라이브러리 중에 Transformer 시각화가 존재한다. 여기에 Jesse Vig이 BERT에 적합하도록 수정하고, Hugging Face의 PyTorch 구현을 이용해 시각화를 진행했다.
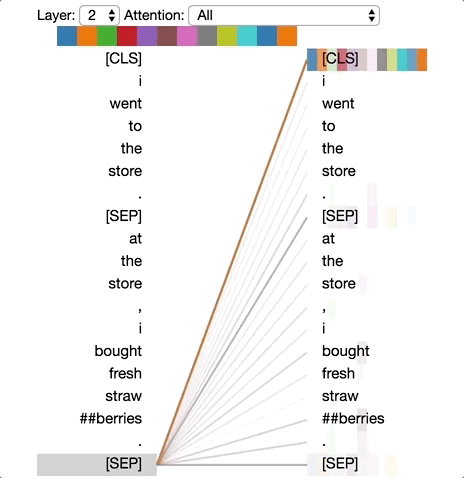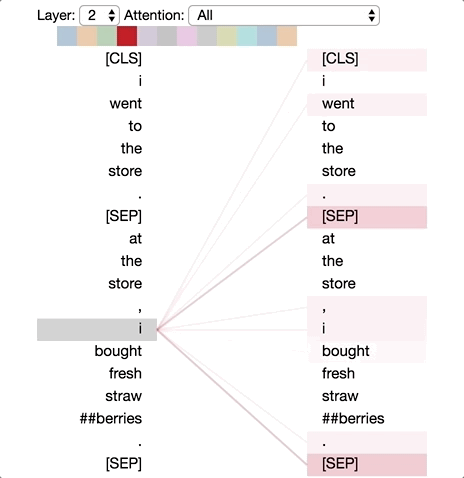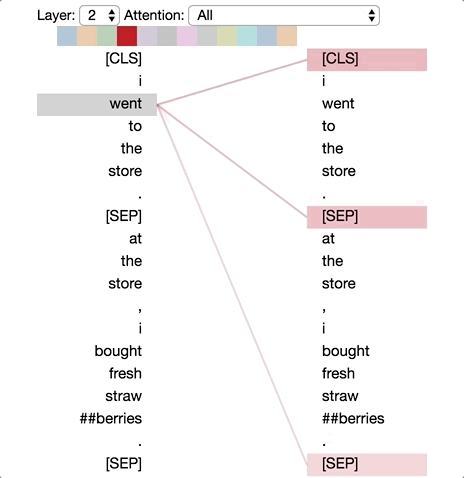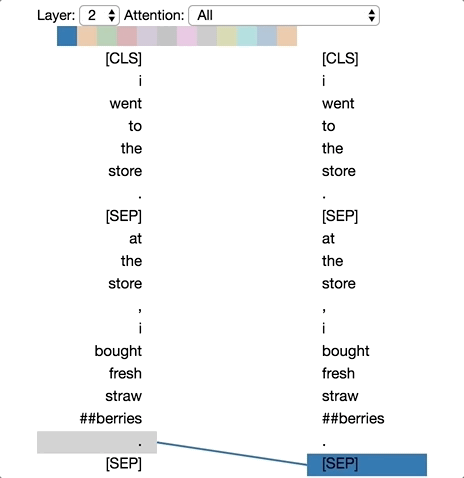
왼편은 업데이트 되는 위치이며, 오른편은 어텐션을 받는 위치이다. 각각의 색상은 어텐션 헤드를 구분하며, Base 모델의 어텐션 헤드는 12개로 구성된다. 라인의 굵기는 어텐션 점수를 뜻한다.
우리가 학습한 한글 모델에 1) 신용 대출을 신청 하고 싶어요 2) 신용 대출 신청은 어떻게 하나요? 이 두개의 실험 문장을 대입하여 시각화 결과를 확인해보도록 한다.
먼저, 한글 모델에는 SentencePiece Tokenizer 대신 한글 형태소 분석 결과를 Tokenizer로 사용한다. 여기서는 카카오 내부에서 사용중인 형태소 분석기 DHA2를 사용해 분석된 결과를 입력으로 사용했다.
sentence_a = "신용 대출 을 신청 하다 고 싶다 어요"
sentence_b = "신용 대출 신청 은 어떻게 하다 나요 ?"
attention_visualizer = visualization.AttentionVisualizer(model, tokenizer, tokenized=True)
tokens_a, tokens_b, attn = attention_visualizer.get_viz_data(sentence_a, sentence_b)
attention.show(tokens_a, tokens_b, attn)

두 번째 문장의 마지막 [SEP]의 어텐션 위치를 보면 당연히 두 번째 문장의 토큰 전체가 영향을 끼친다는 점을 확인할 수 있다. 여기에는 재밌게도 맨 처음 [CLS] 토큰도 강하게 영향을 끼친다는 점인데, 이는 [CLS]의 벡터만으로 분류 문제를 해결한다는 점을 생각한다면 납득이 되는 결과다. RNN은 Long-Term Dependency 문제로 인해 20여개나 되는 토큰의 거리를 뛰어 넘어 강하게 영향을 끼치기는 쉽지 않다.

이번에는 ‘어떻게’라는 토큰에 대한 Self-Attention 결과다. 각각 첫 번째, 두 번째 인코더 블럭의 결과이며, 첫 번째에는 ‘신용’, ‘대출’, ‘신청’에 약하게 영향을 주고, ‘나요’, ‘?’에 강하게 영향을 준다. 이를 연결해보면 ‘신용 대출 신청 어떻게 나요 ?’와 같은 직관적인 결과를 확인할 수 있다.
두 번째 인코더 블럭은 좀 더 흥미로운데, ‘어떻게’가 ‘?’에 매우 강하게 영향을 끼치는걸 확인할 수 있다. 실제로 ‘어떻게’는 형용사로, 영어에서는 의문 형용사로 쓰인다는 점을 생각해본다면 언어학 적으로도 의미있는 결과로 볼 수 있다.
서비스
BERT를 서비스로 구현하기 위해 여기서는 앞서 Sentence Representation에서 살펴본 bert-as-service를 이용해 데모를 구현했다. bert-as-service는 ZeroMQ를 이용해 웹서비스 형태로 구현한 오픈소스로 초기 버전의 경우 몇몇 심각한 버그가 있었고 때문에 고생을 많이 하였으나 일부 버그는 직접 패치를 제출했고, 원저자의 적극적인 피드백으로 빠르게 패치될 수 있었다. 현재까지도 매우 활발하게 개선되고 있어 앞으로가 더욱 기대되는 프로젝트다. 속도 또한 배치 사이즈 디폴트인 256으로 했을때 Tesla V100 GPU 1대에서 Inference에 1,000 TPS 가까이 얻을 수 있었다. 이 정도면 서비스를 하기에도 충분한 속도를 지니고 있다고 볼 수 있다.
한국어 적용
한국어로 서비스를 구현하면서 벡터의 단순 sum/mean을 넘어 보다 다양한 변형으로 실험을 진행하고 품질을 확인했다. 여기서 구현하고자 하는 모델은 입력 문장에 대한 각 문장의 유사도 순위를 판별하는 모델이며, 앞서 [CLS] 벡터를 이용하거나 Pooling Layer의 변경, 벡터 sum/mean 방식의 변형 등 다양한 방안을 고민할 수 있다. 여기서는 baseline으로 Zero Padding에 대한 벡터는 제외하고, BM25로 Weighted Sum을 구현해 중요 벡터에 가중치를 높이는 방식으로 아래와 같은 품질을 얻을 수 있었다.

실험은 정량적인 평가가 가능하도록 테스트셋을 구축해 지속적인 실험 개선이 가능하도록 했다. Fine-tuning 및 여러가지 실험을 계속 진행하면서 보다 효율적인 Sentence Representation을 찾아 본다면 더 좋은 결과를 얻을 수 있을 것으로 기대한다.
참고 문헌
-
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding ↩ ↩2 ↩3
-
Gentle Introduction to Statistical Language Modeling and Neural Language Models ↩
-
The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning) ↩
-
Deconstructing BERT: Distilling 6 Patterns from 100 Million Parameters ↩