
TensorFlow 추론 최적화
2019년 6월 19일 초안 작성
본론
Estimators API
TensorFlow는 1.1 이후 하이 레벨 추상화 API인 Estimators를 제공한다.
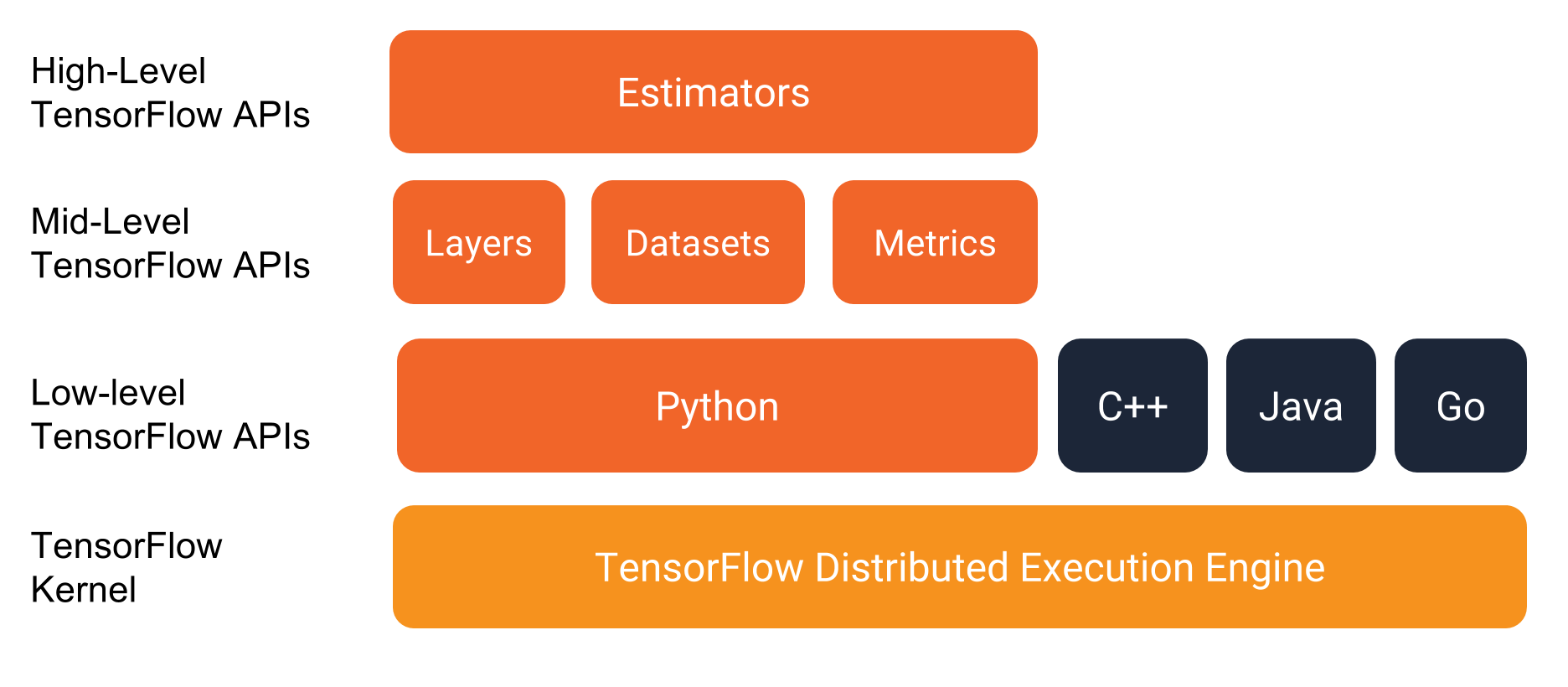
Premade Estimators를 제공하며, 이를 이용해 여러가지 실험을 하이 레벨에서 손쉽게 진행할 수 있다.
그러나,
It is still a mystery to me why the tf.estimator API does not offer an efficient predict method for on-the-fly requests. (Guillaume Genthial, 2018)
Estimators는 추론시 매 번 동적 그래프를 생성하며, 이를 최적화 하기 위해서는 모델을 익스포트 하고 서빙 등으로 구현해야 한다.
TensorFlow Serving
학습한 모델은 SavedModel로 export 하여 서비스를 구현한다.
참고: Serve TensforFlow Estimator with SavedModel
# Use `screen` to track foreground activity
$ screen -S serving
$ tensorflow_model_server --port=9000 --rest_api_port=9001 --model_base_path=/home/deploy/export
CLI
CLI를 통해 모델의 input/output을 조회할 수 있다.
$ saved_model_cli show --dir saved_model/1558520396 \
--tag_set serve \
--signature_def translate
The given SavedModel SignatureDef contains the following input(s):
inputs['input'] tensor_info:
dtype: DT_INT64
shape: (-1, -1)
name: input_tensor:0
The given SavedModel SignatureDef contains the following output(s):
outputs['outputs'] tensor_info:
dtype: DT_INT32
shape: (-1, -1)
name: model/Transformer/strided_slice_19:0
outputs['scores'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: model/Transformer/strided_slice_20:0
Method name is: tensorflow/serving/predict
직접 predict를 진행할 수도 있다.
$ saved_model_cli run --dir=saved_model/1558520396 \
--tag_set=serve \
--signature_def=translate \
--input_expr="input=[[26228, 145, 178, 1, 0, 0, 0]]"
Result for output key outputs:
[[5964 1 0 0 0 0 0]]
Result for output key scores:
[-3.9668984]
하지만 만약 이미 서빙이 구동 중인 상태라면 GPU의 Out of Memory로 predict가 진행되지 않는다.
Docker
TensorFlow Serving을 구동하는 방법으로 Docker를 이용한 방법이 권장된다. 상기 예제의 Iris 모델은 아래와 같이 Docker 명령으로 실행한다. 포트 8500은 gRPC, 8501은 REST API를 제공한다.
$ TESTDATA="$(pwd)/export"
$ sudo docker run -it --rm -p 8501:8501 \
-v "$TESTDATA:/models/iris" \
-e MODEL_NAME=iris \
tensorflow/serving
서빙을 동시에 2개 이상을 구동하면 GPU의 Out of Memory 오류가 발생한다. 따라서 두 개 이상의 모델은 아래와 같이 설정을 주입하여 하나의 서빙에서 구동할 수 있도록 구성한다.
# config.conf
model_config_list: {
config: {
name: "enko",
base_path: "/models/enko",
model_platform: "tensorflow",
model_version_policy: {
all: {}
}
},
config: {
name: "koen",
base_path: "/models/koen",
model_platform: "tensorflow",
model_version_policy: {
all: {}
}
}
}
nvidia-docker run -it --rm -p 8500:8500 -p 8501:8501 \
--mount type=bind,source=/home/ec2-user/models/saved_model_enko/,target=/models/enko \
--mount type=bind,source=/home/ec2-user/models/saved_model_koen/,target=/models/koen \
--mount type=bind,source=/home/ec2-user/models/config.conf,target=/config/config.conf \
-t tensorflow/serving:latest-gpu --model_config_file=/config/config.conf
gRPC 클라이언트는 아래와 같은 형태로 작성할 수 있다. (Example)
stub = prediction_service_pb2_grpc.PredictionServiceStub(
grpc.insecure_channel('{host}:{port}'.format(host='127.0.0.1', port='8500'))
)
# Call translation model to make prediction on the encoded sentence.
request = predict_pb2.PredictRequest()
if enko:
request.model_spec.name = 'enko'
else:
request.model_spec.name = 'koen'
request.model_spec.signature_name = 'translate'
request.inputs['input'].CopyFrom(make_tensor_proto(
[encoded_txt],
shape=[1, len(encoded_txt)], dtype=tf.int64))
translation = stub.Predict(request).outputs['outputs'].int_val
REST API
직접 모델 서버를 구성할때와 달리 Docker로 구동한 상태에서는 REST API 호출이 어렵다. Iris 모델 예제에서 input tensor type이 DT_STRING 인데 직접 JSON을 만들어야 해서 curl 페이로드를 만드는 방식이 다소 혼란스럽다. SO에 질문을 올렸고, 다른 질문에 답변도 달렸으나 모두 제대로 동작하지 않았다.
한 달 후 SO에 답변이 달렸고 문제가 해결됐다. 파라미터를 examples로 지정해 문제가 해결됐다.
POST http://tensorflow-serving.pg1.krane.xx:9001/v1/models/default:classify
Content-Type: application/json
{
"examples": [
{
"SepalLength": [
5.1
],
"SepalWidth": [
3.3
],
"PetalLength": [
1.7
],
"PetalWidth": [
0.5
]
}
]
}
TensorRT
2017년 TensorRT 버전 2가 등장했고, 벌써 5.1까지 업그레이드 됐다. Inference Server와 함께 아래 깃헙에 오픈소스로 진행되고 있다.
TensorRT-based applications perform up to 40x faster than CPU-only platforms during inference.
TensorRT는 CPU-only에 비해 최대 40x 빠르다고 홍보한다.