
TIME_WAIT 상태란 무엇인가
2015년 6월 14일 1차 개정
2015년 6월 4일 초안 작성
서론
TIME_WAIT 이란 TCP 상태의 가장 마지막 단계이여, 이미 지난 CLOSE_WAIT 문서에서도 살펴본바 있다. Active Close 즉, 먼저 close()를 요청한 곳에서 최종적으로 남게되며, 2 MSL 동안 유지된다.
이 단순한 과정이 매 번 어렵게 느껴지는 이유는 대부분은 고급언어로 소켓을 랩핑해서 사용하기 때문에(이전 문서에서 예제로 제시한 Java 코드1도 accept() 이전 모든 과정이 라이브러리로 랩핑되어 있음) 소켓에 문제가 생기지 않는한 로우 레벨로 내려가 확인할 일이 흔치 않고, 또한 확인하는 방법을 아는 이도 드물다.
구현 및 재현에 나름 고급 기술이 필요하다보니 거의 대부분은 실제 검증 과정을 거치지 못하고 문서로 익히곤 한다. 그러다 보니 잘못된 정보, 오래된 정보로 더 이상 유효하지 않은 내용들이 무분별하게 전제된다.
제대로 된 검증과정도 거치지 않은채 또는 검증할 능력이 부족한 상태에서 계속 인용되면서 잘못된 정보가 지속적으로 확대 재생산된다. 심지어 스택오버플로우에도 절반 이상은 잘못된 정보다. 그나마 해외에는 제대로 된 문서가 일부 있지만 우리말로 된 문서 중에는 100% 정확한 문서가 전혀 없다고 봐도 틀리지 않다.
잘못된 정보를 접한 이들은 서버 동작과 일치하지 않으니 계속 이해를 못하게 되고 점점 더 어렵게 느껴진다. 그야 말로 ‘진퇴양난’이다.
현재 시점에서 인터넷에 있는 가장 정확한 문서는 Vincent Bernat 가 작성한 Coping with the TCP TIME-WAIT state on busy Linux servers 이다. 이외 대부분의 문서는 잘못된 내용을 담고 있는 경우가 대부분이므로 주의가 필요하다.
참고로 이 문서는 리눅스 커널 4.1 커널 소스를 직접 파악하여 리눅스의 TCP 동작을 정리한 내용이다. TCP 는 몇년새 큰 변화가 없기 때문에 3.x 이상은 대부분 동일하다. 그러나 BSD나 윈도우의 동작 방식과는 다를 수 있으므로 참고 바란다.
본론
TIME_WAIT 상태가 왜 필요하고, 왜 그렇게 길게 설정되어 있는지 이유를 살펴보도록 한다. 만일 TIME_WAIT이 짧다면 아래와 같은 두 가지 문제2가 발생한다.

첫 번째는 지연 패킷이 발생할 경우다.
이미 다른 연결로 진행되었다면 지연 패킷이 뒤늦게 도달해 문제가 발생한다. 매우 드문 경우이긴 하나 때마침 SEQ까지 동일하다면 잘못된 데이타를 처리하게 되고 데이타 무결성 문제가 발생한다.

두 번째는 원격 종단의 연결이 닫혔는지 확인해야할 경우다.
마지막 ACK 유실시 상대방은 LAST_ACK 상태에 빠지게 되고 새로운 SYN 패킷 전달시 RST를 리턴한다. 새로운 연결은 오류를 내며 실패한다. 이미 연결을 시도한 상태이기 때문에 상대방에게 접속 오류 메시지가 출력될 것이다.
따라서 반드시 TIME_WAIT이 일정 시간 남아 있어서 패킷의 오동작을 막아야 한다.
RFC 793 에는 TIME_WAIT을 2 MSL로 규정했으며 CentOS 6에서는 60초 동안 유지된다. 아울러 이 값은 조정할 수 없다.
틀린 정보
net.ipv4.tcp_fin_timeout 을 설정하면 TIME_WAIT 타임아웃을 변경할 수 있다.
TIME_WAIT의 타임아웃 정보는 커널 헤더 include/net/tcp.h 에 하드 코딩 되어 있으며 변경이 불가능하다.
// include/net/tcp.h
#define TCP_TIMEWAIT_LEN (60*HZ) /* how long to wait to destroy TIME-WAIT
* state, about 60 seconds */
샘플 서버
지난 번과 달리 이번에는 소켓의 로우 레벨까지 확인하기 위해 샘플 서버 프로그램을 C 로 구현했다. 리눅스를 포함한 모든 유닉스 기반 OS 의 API 가 C 로 구현되어 있고 특히 네트워크 프로그램에서 커널의 동작과 C 의 어플리케이션 API 는 정확히 1:1 로 대응 된다. 따라서 구체적으로 네트워크가 어떻게 동작하는지를 C 로 직접 구현해 하나씩 확인해보도록 한다.
먼저 서버 프로그램은 예전에 커넥션 테스트 용도로 개발해 깃헙에 공개한 CONTEST 서버를 기반으로 일부 코드를 추가해서 구현했다.
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <time.h>
#include <pthread.h>
#include <net/if.h>
#include <sys/ioctl.h>
#define BACKLOG 128 // backlog for listen()
#define DEFAULT_PORT 5000 // default listening port
#define BUF_SIZE 1024 // message chunk size
time_t ticks;
typedef struct {
int client_sock;
} thread_param_t;
thread_param_t *params; // params structure for pthread
pthread_t thread_id; // thread id
void error(char *msg) {
perror(msg);
exit(EXIT_FAILURE);
}
/**
* thread handler after accept()
*/
void *handle_client(void *params) {
char msg[BUF_SIZE];
thread_param_t *p = (thread_param_t *) params; // thread params
// clear message buffer
memset(msg, 0, sizeof(msg));
ticks = time(NULL);
snprintf(msg, sizeof(msg), "%.24s\r\n", ctime(&ticks));
write(p->client_sock, msg, strlen(msg));
printf("Sent message to Client #%d\n", p->client_sock);
// wait
usleep(10);
// clear message buffer
memset(msg, 0, sizeof(msg));
// active close, It will remains in `TIME_WAIT` state.
if (close(p->client_sock) < 0)
error("Error: close()");
free(p);
return NULL;
}
int main(int argc, char *argv[]) {
int listenfd = 0, connfd = 0;
struct sockaddr_in serv_addr;
struct ifreq ifr;
// build server's internet addr and initialize
memset(&serv_addr, '0', sizeof(serv_addr));
serv_addr.sin_family = AF_INET; // an internet addr
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY); // accept any interfaces
serv_addr.sin_port = htons(DEFAULT_PORT); // the port we will listen on
// create the socket, bind, listen
if ((listenfd = socket(AF_INET, SOCK_STREAM, 0)) < 0)
error("Error: socket()");
if (bind(listenfd, (struct sockaddr *) &serv_addr, sizeof(serv_addr)) < 0)
error("Error: bind() Not enough privilleges(<1024) or already in use");
if (listen(listenfd, BACKLOG) < 0)
error("Error: listen()");
ifr.ifr_addr.sa_family = AF_INET; // an internet addr
strncpy(ifr.ifr_name, "eth0", IFNAMSIZ-1); // IP address attached to "eth0"
ioctl(listenfd, SIOCGIFADDR, &ifr); // get ifnet address
// print <IP>:<Port>
printf("Listening on %s:%d\n",
inet_ntoa(((struct sockaddr_in *)&ifr.ifr_addr)->sin_addr),
DEFAULT_PORT);
while (1) {
connfd = accept(listenfd, (struct sockaddr *) NULL, NULL);
// memory allocation for `thread_param_t` struct
params = malloc(sizeof(thread_param_t));
params->client_sock = connfd;
// 1 client, 1 thread
pthread_create(&thread_id, NULL, handle_client, (void *) params);
pthread_detach(thread_id);
}
}
Java에 비해 코드는 훨씬 더 길지만 동작 방식에는 큰 차이가 없다. 마찬가지로 서버가 먼저 close()를 시도하는 점도 동일하다. 즉, 서버측이 Active Close가 되고 TIME_WAIT 상태에 빠지게된다.
서버 방식
서버의 동작은 socket() - bind() - listen() - accept() 과정을 거쳐 클라이언트와 연결되며 위 코드에는 그 과정이 상세히 잘 나와 있다.
accept() 이후 서버는 listen() 중인 소켓과 별도로 accept() 소켓을 추가로 생성해 클라이언트를 할당한다. 서버가 클라이언트를 관리하는 방식은 크게 4가지로 구분할 수 있다.3
- 요청 당 프로세스 할당,
fork()로 자식 프로세스를 만들어 클라이언트를 담당한다. 전통적인 blocking I/O 방식이다. - 요청 당 쓰레드 할당. 위 예제에서 사용한 방식으로
pthread_create()를 통해 쓰레드를 생성, 클라이언트를 담당한다. 마찬가지로 blocking I/O 방식이다. - 쓰레드풀을 구성해 각각의 쓰레드가 여러 커넥션을 asynchronous I/O 방식으로 담당한다.
- 쓰레드풀을 구성해 각각의 쓰레드가 여러 커넥션을
select(),poll(), nonblocking I/O 같은 이벤트 기반 방식으로 담당한다.
이 중 대용량 처리에 3, 4번이 우세하며 특히 4번이 대세이다. 하지만, 여기서 모두 언급하기엔 지나치게 방대하므로 추후 별도로 정리해보기로 한다. 자세한 사항은 C10K Problem을 참고하기 바란다.
여기선 가장 간편한 방식인 2번, 클라이언트를 각각의 쓰레드에 할당하고 close() 될때 쓰레드도 함께 종료되는 방식으로 구현했다.

htop을 이용해 쓰레드 옵션을 켜고(H 키), 트리 모드(t 키)에서 요청이 있을때마다 쓰레드가 하나씩 생성되는 모습을 직접 확인한 화면이다.
현재 2개의 요청을 처리 중이며, 물론 요청이 끝나면 쓰레드도 함께 종료된다. 만약 프로세스나 쓰레드를 할당하지 않았다면 요청이 끝날때까지 다른 요청은 받지 못하는 말 그대로 blocking 상태가 유지될 것이다.
종료 과정
샘플 서버를 구동하고 클라이언트에서 FIN/ACK이 잘 전달되는지 확인해본다. 아울러 서버의 Active Close 후 서버측에 남게되는 TIME_WAIT 상태를 직접 확인한다.
TCP/IP Illustrated 의 TCP 연결 종료 다이어그램은 아래와 같다.
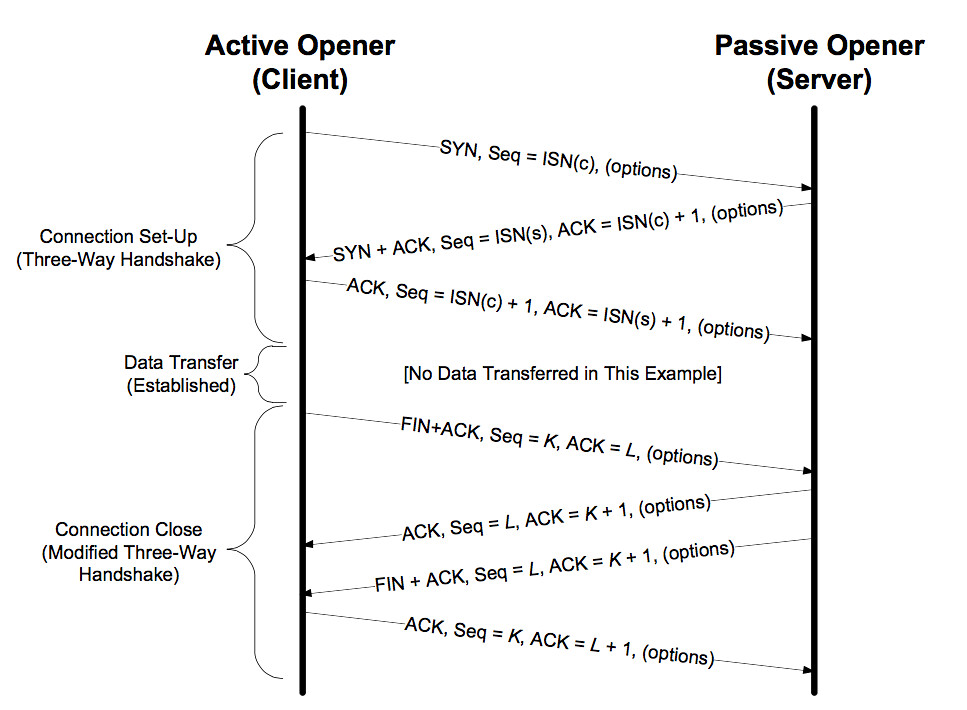
연결 종료의 4-way handshake 과정은 다음과 같다.
FIN+ACK, seq = K, ack = LACK, seq = L, ack = K + 1FIN+ACK, seq = L, ack = K + 1ACK, seq = K, ack = L + 1
서버 접속 후 tcpdump 로 패킷 상태를 덤프한 결과다.
$ tcpdump -nn -i eth0 host 10.15.86.214
13:32:31.626549 IP 10.41.147.237.5000 > 10.15.86.214.30202: Flags [F.], seq 27, ack 1, win 16, options [nop,nop,TS val 2599042792 ecr 2329783108], length 0
13:32:31.626877 IP 10.15.86.214.30202 > 10.41.147.237.5000: Flags [.], ack 27, win 6, options [nop,nop,TS val 2329783108 ecr 2599042792], length 0
13:32:31.626964 IP 10.15.86.214.30202 > 10.41.147.237.5000: Flags [F.], seq 1, ack 28, win 6, options [nop,nop,TS val 2329783108 ecr 2599042792], length 0
13:32:31.626975 IP 10.41.147.237.5000 > 10.15.86.214.30202: Flags [.], ack 2, win 16, options [nop,nop,TS val 2599042792 ecr 2329783108], length 0
포트 5000번이 서버다. 그리고 서버가 먼저 FIN을 보내며 Active Close를 시도했다. tcpdump 의 결과 Flags, 패킷 타입 플래그는 다음과 같다.
[S]- SYN (Start Connection)[.]- No Flag Set[P]- PSH (Push Data)[F]- FIN (Finish Connection)[R]- RST (Reset Connection)
[.]은 ACK를 뜻하며 [F.] 은 FIN+ACK 을 가리키는 싱글 패킷이다. 이에 따라 실제 덤프 결과를 분석해보면,
FIN+ACK, seq = 27, ack = 1ACK, seq = 1, ack = 27FIN+ACK, seq = 1, ack = 28ACK, seq = 28, ack = 2
verbose 모드가 아니었기 때문에 ACK의 seq는 보이지 않는다. 추가로 -vv 옵션을 부여하면 verbose 모드가 되며 확인할 수 있다.
그런데 CentOS 6의 결과 중 두 번째 ACK의 ack 값과 마지막 ACK의 seq 값이 TCP/IP Illustrated 에서 명시된 숫자와 하나씩 다르다. OS 별로 커널 버전 별로 조금씩 다르게 동작하기도 하는데 이 부분은 추후에 보다 정확한 확인이 필요하다.
이렇게 종료 handshake 과정이 정상적으로 끝나면 Active Close를 먼저 요청한 서버쪽에 TIME_WAIT이 남게된다.

처리한 쓰레드도 이미 종료된 상태로 할당된 프로세스도 보이지 않는다. 이미 커널로 소유권이 넘어 갔으며 프로세스를 종료해도 TIME_WAIT 상태는 사라지지 않는다. 오히려 소켓이 해당 포트를 점유하고 있는 상태로 60초 동안 재시작을 할 수 없게 된다.
재시작을 시도하면 bind() 단계에서 오류가 발생하며 시간이 지나 TIME_WAIT이 모두 사라진 후에야 가능하다.
$ ./server
ERROR: Address already in use
소켓 옵션
만일 즉시 재시작이 필요하다면 setsockopt()의 SO_REUSEADDR 옵션을 적용하면 bind() 단계에서 커널이 가져간 소유권을 다시 돌려받으며 즉시 재시작 가능하다.
setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, &yes, sizeof(yes));
틀린 정보
SO_REUSEADDR 와 tcp_tw_reuse 는 동일하게 적용되는 옵션이다.
// net/core/sock.c
case SO_REUSEADDR:
sk->sk_reuse = (valbool ? SK_CAN_REUSE : SK_NO_REUSE);
break;
커널 코드에서 SO_REUSEADDR은 socket 구조체 sk_reuse를 1로 설정하므로 tcp_tw_reuse를 설정하는 것과 동일한 역할을 한다. 그러나 여기에는 결정적인 차이가 있는데, 전자는 커널(서버)의 역할이고 후자는 glibc(클라이언트)의 역할로 서로 다르다는 점이다.
SO_REUSEADDR: 서버 소켓에 적용되는 옵션tcp_tw_reuse: 클라이언트 소켓에 적용되는 옵션
클라이언트 소켓에 SO_REUSEADDR을 부여한다고 TIME_WAIT을 재사용할 수 있는게 아니다. tcp_tw_reuse 커널 설정이 필요하다.
반대로 서버 소켓에서 bind()시 tcp_tw_reuse 설정을 했다고 바인딩 되지 않는다. SO_REUSEADDR 옵션을 부여해야 한다.
이후에 다시 자세히 설명하도록 한다.
쌍방
양쪽 모두 TIME_WAIT이 남는 재미난 현상도 발생할 수 있다. 양쪽 모두 동일 시점에 Active Close를 시도할 경우다.
$ tcpdump -nn -i eth0 host 10.51.31.141
14:37:45.682624 IP 10.51.31.141.1063 > 10.51.31.140.5000: Flags [S], seq 50755794, win 14600, options [mss 1460,sackOK,TS val 382514872 ecr 0,nop,wscale 10], length 0
...
14:37:45.683122 IP 10.51.31.141.1063 > 10.51.31.140.5000: Flags [F.], seq 1, ack 27, win 15, options [nop,nop,TS val 382514873 ecr 382506868], length 0
14:37:45.683125 IP 10.51.31.140.5000 > 10.51.31.141.1063: Flags [F.], seq 27, ack 1, win 15, options [nop,nop,TS val 382506868 ecr 382514873], length 0
14:37:45.683133 IP 10.51.31.140.5000 > 10.51.31.141.1063: Flags [.], ack 2, win 15, options [nop,nop,TS val 382506868 ecr 382514873], length 0
14:37:45.683160 IP 10.51.31.141.1063 > 10.51.31.140.5000: Flags [.], ack 28, win 15, options [nop,nop,TS val 382514873 ecr 382506868], length 0
여기엔 특이한 경우가 두 번이나 발생했는데, 먼저 최초 SYN 이후 패킷 전달이 잘 끝나고 어플리케이션 종료 시점에 양쪽 모두 거의 동일한 시간에 FIN+ACK을 전달하며 Active Close를 시도했다.
보통 이런 경우 한쪽에서만 ACK를 보내고 송신한 쪽이 TIME_WAIT 상태로 끝나게 되는데 공교롭게도 ACK 또한 양쪽 모두 동시에 전달을 시도했다.
매우 특이한 경우지만 드물게 발생할 수 있는 경우다. 그리고 이런 경우 양쪽 모두 TIME_WAIT 상태에 빠지게 된다.
// Server
$ ss -tanop | grep 1063
TIME-WAIT 0 0 10.51.31.140:5000 10.51.31.141:1063 timer:(timewait,45sec,0)
// Client
$ ss -taonp | grep 1063
TIME-WAIT 0 0 10.51.31.141:1063 10.51.31.140:5000 timer:(timewait,42sec,0)
자원 할당
그렇다면 다수의 TIME_WAIT은 과연 시스템 성능 저하를 가져올까.
Each socket in TIME_WAIT consumes some memory in the kernel, usually somewhat less than an ESTABLISHED socket yet still significant. A sufficiently large number could exhaust kernel memory, or at least degrade performance because that memory could be used for other purposes.4
Because application protocols do not take TIME-WAIT TCB distribution into account, heavily loaded servers can have thousands of connections in TIME-WAIT that consume memory and can slow active connections. In BSD-based TCP implementations, TCBs are kept in mbufs, the memory allocation unit of the networking subsystem[9]. There are a finite number of mbufs available in the system, and mbufs consumed by TCBs cannot be used for other purposes such as moving data. Some systems on high speed networks can run out of mbufs due to TIME-WAIT buildup under high connection load. A SPARCStation 20/71 under SunOS 4.1.3 on a 640 Mb/s Myrinet[10] cannot support more than 60 connections/sec because of this limit.5
스택오버플로우의 답변4이나 그렇다는 논문5이 있는데 특히 메모리 점유 문제를 심각하게 얘기한다. 여기서 주의해야 할 점은 TIME_WAIT으로 인한 성능 저하 논문은 1997년에 출판됐다는 점이다. 지금은 2015년이다. 벌써 18년전 이야기다. 그 당시 서버 메모리는 512MB였고 지금 테스트를 진행하는 서버의 메모리는 64G다. 100배가 넘는다. 그런데 아직도 TIME_WAIT 때문에 메모리 점유가 심각하다고 말한다면 뭔가 이상하다.
struct tcp_timewait_sock는 고작 168바이트에 불과하다.2
struct tcp_timewait_sock {
struct inet_timewait_sock tw_sk;
u32 tw_rcv_nxt;
u32 tw_snd_nxt;
u32 tw_rcv_wnd;
u32 tw_ts_offset;
u32 tw_ts_recent;
long tw_ts_recent_stamp;
};
만약 4만개의 TIME_WAIT 상태 인바운드 커넥션이 있다면 10MB 안쪽의 메모리를 차지한다. 아웃바운드 커넥션도 고작 2.5MB가 더 필요할 뿐이다.2 요즘 서버 사양에서 TIME_WAIT 상태가 차지하는 메모리 용량은 아주 미미하다.
현재 서버의 소켓 상태는 아래 명령어로 확인할 수 있다.
$ cat /proc/net/sockstat
sockets: used 76
TCP: inuse 17 orphan 0 tw 0 alloc 17 mem 1
...
그렇다면 TIME_WAIT 상태가 증가하면 어떤 일이 발생할까. 실제 부하 테스트를 통해 이를 확인해보기로 한다.
여러대의 클라이언트를 동원해 연속된 요청으로 9만개 가까운 TIME_WAIT 상태를 만들어 냈다.
$ ss -ant | awk '{print $1}' | grep -v '[a-z]' | sort | uniq -c
1 ESTAB
15 LISTEN
89262 TIME-WAIT
틀린 정보
서버의 소켓 수는 할당 가능한 로컬 포트 만큼인 최대 65,535개이고 net.ipv4.ip_local_port_range 설정으로 변경할 수 있다.
서버는 로컬 포트를 사용하지 않는다.
만일 많은 사람들이 오해하고 있는 것 처럼, 서버가 로컬 포트를 사용하고 로컬 포트는 단 하나의 소켓에만 바인딩된다고 가정한다면,
- 지금 처럼 9만개 가까운
TIME_WAIT을 만들어 낼 수 없다. 로컬 포트는 (2^16)-1 = 65,535개가 최대다. - OS 몰래 비밀 포트를 여는 백도어가 존재하는게 아니라면
tcpdump에 보이지 않을리 없다. 최초 바인딩된 포트만 사용해 패킷을 주고 받는걸 확인할 수 있다.
서버가 할당하는 것은 포트가 아닌 소켓이며 서버의 포트는 최초 bind()시 하나만 사용한다. 로컬 포트를 할당하는 것은 클라이언트이며, 클라이언트가 connect()시 로컬 포트를 임의로(ephemeral port) 바인딩하면서 서버의 소켓과 연결된다.
소켓은 <protocol>, <src addr>, <src port>, <dest addr>, <dest port> 이 5개 값이 유니크하게 구성된다. 따라서 서버 포트가 추가되거나 클라이언트의 IP가 추가될 경우 그 만큼의 새로운 쌍을 생성할 수 있어 TIME_WAIT가 많이 남아 있어도 별 문제가 없다.
소켓의 수는 설정된 리눅스 파일 디스크립터만큼 생성할 수 있다. 아래 설정으로 서버가 이론적으로는 26만개가 넘는 클라이언트도 받을 수 있다는 얘기다.
$ sysctl fs.file-max
fs.file-max = 262144
서버가 또 다른 서버에 클라이언트로 접속하지만 않는다면 자신의 로컬 포트는 사용할 일이 없으며, 리눅스의 로컬 포트 범위는 3만개 정도로 설정되어 있다. 마찬가지로 이론적으로는 3만개의 서버에 동시 접속이 가능하다.
$ sysctl net.ipv4.ip_local_port_range
net.ipv4.ip_local_port_range = 32768 61000
만일 서버 투 서버로 1:1 대용량 접속이 발생할 경우 한 대의 클라이언트에서 가능한 최대 요청 수는 500 RPS(Requests Per Second) 정도다. 500 * 60 (TIME_WAIT 시간) = 3만개 이기 때문이다. 이 수치를 넘어서지 않는다면 아무런 커널 설정도 변경할 필요가 없으며, 부하 테스트 등 특수한 용도여야 이 수치를 넘어설 수 있을 것이다.
재사용
그러나 이 수치를 넘어선다면 클라이언트의 로컬 포트가 고갈 될 것이며 TIME_WAIT 상태를 재사용 해야 한다. 아래 3가지 경우로 분류할 수 있다.
- 서버에
TIME_WAIT상태가 남아 있으며, 클라이언트의 로컬 포트가 고갈된 경우 - 클라이언트에
TIME_WAIT상태가 남아 있으며, 클라이언트의 로컬 포트가 고갈된 경우 - 클라이언트에
TIME_WAIT상태가 남아 있으며, 클라이언트의 로컬 포트가 고갈되고, 서버의 다른 포트에 접속할 경우
1번의 경우 클라이언트 입장에서는 서버에 남아 있는 TIME_WAIT 상태를 알 수 없다. 따라서 클라이언트는 계속해서 임의의 포트(ephemeral port)에 SYN 패킷을 내보낸다. 임의의 포트는 순차 증가하는 형태이므로 FIFO 기준을 따르게 된다. 서버에는 TIME_WAIT 상태로 남아 있지만 동일 소켓이 SYN을 수신하면 재사용하게 된다. 양쪽 모두 별도 설정은 필요 없다.
// net/ipv4/tcp_minisocks.c
/*
* RFC 1122:
* "When a connection is [...] on TIME-WAIT state [...]
* [a TCP] MAY accept a new SYN from the remote TCP to
* reopen the connection directly.
*/
2번은 오류가 발생하며 더 이상 접속할 수 없다.
$ telnet 10.41.118.88 5000
Trying 10.41.118.88...
telnet: connect to address 10.41.118.88: Cannot assign requested address
telnet: Unable to connect to remote host: Cannot assign requested address
소켓은 <protocol>, <src addr>, <src port>, <dest addr>, <dest port> 5개 값으로 구성되며 로컬 포트가 고갈되면 더 이상 유니크한 값을 만들어 낼 수 없다. 클라이언트의 net.ipv4.tcp_tw_reuse 옵션을 설정하여 기존 클라이언트에 TIME_WAIT 상태로 남아 있던 소켓을 재사용해야 한다.
$ echo 1 > /proc/sys/net/ipv4/tcp_tw_reuse
$ sysctl net.ipv4.tcp_tw_reuse
net.ipv4.tcp_tw_reuse = 1
3번은 문제가 없다. 앞서 언급했듯 소켓은 5개 유니크 값이며 맨 마지막이 <dest port> 이다. 이 말은 포트가 다를 경우 다시 그만큼의 새로운 소켓 쌍을 만들어낼 수 있음을 뜻한다. 재사용이 필요 없다.
$ ss -tonpa | grep 1033
TIME-WAIT 0 0 10.51.31.141:1033 10.51.31.140:5000 timer:(timewait,52sec,0)
ESTAB 0 0 10.51.31.141:1033 10.51.31.140:22 users:(("telnet",29636,3))
위 상태는 실제 클라이언트 환경에서 동일한 로컬 포트에 하나는 TIME_WAIT, 하나는 ESTABLISHED 상태인 모습이다. 상대방 포트는 다르기 때문에 이렇게 동일한 로컬 포트를 함께 쓰는게 가능하다. 같은 원리로 서버도 하나의 포트에 여러개의 소켓이 할당된다.
바인드
그렇다면 리눅스 커널에서 로컬 포트가 어떤 알고리즘으로 바인드(bind()) 되는지 좀 더 자세히 살펴보도록 한다. 클라이언트가 패킷을 전송할때 아직 할당된 로컬 포트가 없다면 아래와 같이 오토 바인드를 진행한다.
// net/ipv4/af_inet.c
int inet_sendmsg(struct socket *sock, struct msghdr *msg, size_t size)
{
...
/* We may need to bind the socket. */
if (!inet_sk(sk)->inet_num && !sk->sk_prot->no_autobind &&
inet_autobind(sk))
return -EAGAIN;
return sk->sk_prot->sendmsg(sk, msg, size);
}
inet_autobind()는 가능한 포트를 소켓 구조체 멤버 함수인 get_port()를 통해 찾는다.
// net/ipv4/af_inet.c
static int inet_autobind(struct sock *sk)
{
struct inet_sock *inet;
/* We may need to bind the socket. */
lock_sock(sk);
inet = inet_sk(sk);
if (!inet->inet_num) {
if (sk->sk_prot->get_port(sk, 0)) {
release_sock(sk);
return -EAGAIN;
}
inet->inet_sport = htons(inet->inet_num);
}
release_sock(sk);
return 0;
}
get_port()는 inet_csk_get_port()로 선언되어 있는데 이 함수에는 두 번째 인자가 0일때 선택 가능한 로컬 포트를 자동으로 찾아내는 알고리즘이 구현되어 있다.
// net/ipv4/inet_connection_sock.c
/* Obtain a reference to a local port for the given sock,
* if snum is zero it means select any available local port.
*/
int inet_csk_get_port(struct sock *sk, unsigned short snum)
{
struct inet_hashinfo *hashinfo = sk->sk_prot->h.hashinfo;
...
local_bh_disable();
if (!snum) {
int remaining, rover, low, high;
again:
inet_get_local_port_range(net, &low, &high);
remaining = (high - low) + 1;
smallest_rover = rover = prandom_u32() % remaining + low;
smallest_size = -1;
do {
if (inet_is_local_reserved_port(net, rover))
goto next_nolock;
head = &hashinfo->bhash[inet_bhashfn(net, rover,
hashinfo->bhash_size)];
...
next_nolock:
if (++rover > high)
rover = low;
} while (--remaining > 0);
이 코드를 보면 먼저 inet_get_local_port_range() 함수에서 net.ipv4.ip_local_port_range로 선언된 가능한 포트 범위를 읽어들이고 이 중 랜덤으로 첫번째 값을 고른다. 그리고 해시 테이블의 정보와 비교하여 사용 가능한 상태인지 +1 씩 증가하면서 확인한다. 마지막 값에 도달한 다음에는 다시 가장 낮은 값으로 돌아가 반복한다. 이 과정을 통해 사용 가능한 포트를 찾아낸다.
// net/ipv4/inet_connection_sock.c
if (net_eq(ib_net(tb), net) && tb->port == rover) {
if (((tb->fastreuse > 0 &&
sk->sk_reuse &&
sk->sk_state != TCP_LISTEN) ||
(tb->fastreuseport > 0 &&
sk->sk_reuseport &&
uid_eq(tb->fastuid, uid))) &&
(tb->num_owners < smallest_size || smallest_size == -1)) {
smallest_size = tb->num_owners;
smallest_rover = rover;
if (atomic_read(&hashinfo->bsockets) > (high - low) + 1 &&
!inet_csk(sk)->icsk_af_ops->bind_conflict(sk, tb, false)) {
snum = smallest_rover;
goto tb_found;
}
}
...
그러나 sk->sk_reuse. 즉, net.ipv4.tcp_tw_reuse가 선언되어 있고 타임스탬프가 더 크고, TIME_WAIT인 경우 혹시 현재 상태가 TCP_LISTEN만 아니라면 바로 재사용한다. 따라서 반복하지 않고 바로 다음 포트를 사용하게 된다.
물론 반복한다고 성능저하가 발생하진 않는다. 2008년 크리스마스 이브(…)에 Evgeniy Polyakov가 빈 포트를 찾기 위해 전체 바인드 해시 테이블을 뒤지는 문제(traverse the whole bind hash table to find out empty bucket)에 대한 패치6를 제출했고 2009년 1월에 받아들여졌기7 때문이다.
그 전에는 바인딩 포트 수가 많아지면 오토 바인드가 점점 더 느려지는 성능 문제가 있었다. 특히 로컬 포트가 모두 고갈될 경우 성능 문제가 발생할 수 있었다.

우연찮게도 이 문제는 다른 테스트 도중 오래된 서버(RHEL 4)에서 직접 재현할 수 있었다.
위 1번의 경우였고,
- 서버에
TIME_WAIT상태가 남아 있으며, 클라이언트의 로컬 포트가 고갈된 경우
원래는 서버/클라이언트 양쪽 모두 아무런 설정 없이 문제가 없어야 되는 상황이다. 그런데 부하 테스트 중 Cannot assign requested address 오류가 발생했다.
$ telnet 10.41.118.88 80
Trying 10.41.118.88...
telnet: connect to address 10.41.118.88: Cannot assign requested address
telnet: Unable to connect to remote host: Cannot assign requested address
포트 고갈로 발생하던 2번과 동일한 오류이며 시스템 전체가 과부하 상태에 빠졌다. 부하가 매우 높을때만 간헐적으로 발생하는 걸로 봐서 위에서 언급한 ‘빈 포트를 찾기 위해 전체 바인드 해시 테이블을 뒤지는 문제’ 비용이 높기 때문으로 보였다. 이미 로컬 포트를 다 사용한 상태에서 매 번 스캔에 리소스를 허비하는 것이다.
이 경우 해결책은 2번과 마찬가지로 클라이언트에서 net.ipv4.tcp_tw_reuse를 명시적으로 선언하면 간단히 해결된다. 커널이 비어 있는 포트를 매 번 스캔할 필요 없이 항상 다음 포트를 빠르게 재사용한다.
$ echo 1 > /proc/sys/net/ipv4/tcp_tw_reuse
$ sysctl net.ipv4.tcp_tw_reuse
net.ipv4.tcp_tw_reuse = 1
타임스탬프
앞서 TIME_WAIT에 대해 설명할때 일정 시간 남아 있어서 패킷의 오동작을 막아야 한다고 언급했는데 어떻게 재사용이 가능한지 궁금할 것이다.
비밀은 net.ipv4.tcp_timestamps에 있다.8 RFC 1323 에서 고성능 익스텐션으로 제안된 옵션 중 하나이며 여기에는 두 개의 4 바이트 타임스탬프 필드가 있다. net.ipv4.tcp_tw_reuse를 활성화하면, 새로운 타임스탬프가 기존 커넥션의 가장 최근 타임스탬프보다도 큰 경우 TIME_WAIT 상태인 커넥션을 재사용하게 된다. tcp_tw_reuse가 비활성화 상태라면 매 번 비어 있는 포트를 스캔하게 되지만, 활성화 상태라면 바로 다음 포트를 사용 또는 재사용 하는 것이다.
그렇다면 처음에 TIME_WAIT이 짧을때 두 가지 문제가 발생할 수 있다고 언급했는데 이 문제에 대해서는 과연 안전한가.
첫 번째 문제는 쉽다.
동일한 SEQ라도 이미 지난 타임스탬프 이므로 확인 후 그냥 버리면 된다.
두 번째 문제도 타임스탬프로 해결된다.
서버가 ACK을 받지 못한 상태에서 새로운 커넥션이 SYN을 보내면 타임스탬프를 비교해 무시한다. 그러는 사이 서버의 FIN이 재전송된다. 그러면 SYN_SENT 상태에 있던 클라이언트는 RST를 보낸다. 이제 서버가 LAST_ACK 상태를 빠져나온다. 그러는 사이 ACK을 받지 못한 클라이언트는 1초 후 다시 SYN을 전송한다. 이제 서버도 SYN+ACK을 보낸다. 이제 둘은 정상적으로 ESTABLISHED 된다.2
타임스탬프가 없었을때는 오류를 내며 새로운 연결이 종료됐지만 이제 정상적으로 연결됐다. 단지 약간의 딜레이만 발생했을 뿐이다.

재사용을 위해서는 net.ipv4.tcp_timestamps 타임스탬프 옵션이 서버/클라이언트 양쪽 모두 반드시 켜져 있어야 한다. 리눅스 커널의 기본 값이며 굳이 끌 필요가 전혀 없다. 어느 한쪽이라도 꺼져 있으면 더 이상 타임스탬프가 부여되지 않는다. 옛날에는 CPU 자원을 절약하기 위해 끄기도 했지만 이제는 그런 시대가 아니다.
아래는 클라이언트가 타임스탬프를 부여했으나 일부러 tcp_timestamps를 꺼둔 서버에서 패킷이 어떻게 오고 가는지 재현한 모습이다. 서버가 nop로 응답했고 그 다음 패킷부터는 타임스탬프가 부여되지 않음을 확인할 수 있다.
14:02:48.704077 IP 10.51.31.141.1027 > 10.51.31.140.5000: Flags [S], seq 2561683863, win 14600, options [mss 1460,sackOK,TS val 380417893 ecr 0,nop,wscale 10], length 0
14:02:48.704120 IP 10.51.31.140.5000 > 10.51.31.141.1027: Flags [S.], seq 1524418616, ack 2561683864, win 14600, options [mss 1460,nop,nop,sackOK,nop,wscale 10], length 0
14:02:48.704233 IP 10.51.31.141.1027 > 10.51.31.140.5000: Flags [.], ack 1, win 15, length 0
14:02:48.704505 IP 10.51.31.140.5000 > 10.51.31.141.1027: Flags [P.], seq 1:27, ack 1, win 15, length 26
재활용
TIME_WAIT을 가장 효율적으로 재활용 하는 방법으로 net.ipv4.tcp_tw_recycle 옵션이 있다. 그러나 NAT 환경에서 문제가 있다.2 서버가 로드 밸런스 뒤에 위치하는 서비스 환경에선 장비간 타임스탬프가 일치하지 않아 역전 현상이 발생할 경우 패킷 드롭이 발생할 수 있으므로 사용해선 안된다. 패킷은 마이크로세컨드 단위로 매우 빠르게 동작하고 장비간 시간을 마이크로 단위로 정확히 맞추기는 사실상 불가능에 가깝기 때문에 사용하기 힘들다.
그러나, 성능은 월등하다.
// net/ipv4/tcp_minisocks.c
if (recycle_ok) {
tw->tw_timeout = rto;
} else {
tw->tw_timeout = TCP_TIMEWAIT_LEN;
if (state == TCP_TIME_WAIT)
timeo = TCP_TIMEWAIT_LEN;
}
tcp_tw_recycle 이 활성화 되어 있으면 TIME_WAIT 상태를 TCP_TIMEWAIT_LEN 즉, 60초가 아닌 rto 즉, retransmission timeout 값으로 적용한다.
...
const int rto = (icsk->icsk_rto << 2) - (icsk->icsk_rto >> 1);
...
newicsk->icsk_rto = TCP_TIMEOUT_INIT;
...
#define TCP_TIMEOUT_INIT ((unsigned)(1*HZ)) /* RFC6298 2.1 initial RTO value */
rto 값이 얼마로 설정되었는지 쭈욱 따라가서 쉬프트 연산자를 계산해보면 1*(2^2) - 1/(2^1) 이므로 3.5초가 된다. tcp_tw_recycle 를 활성화 하는 것만으로 기존 60초에서 획기적으로 줄어드는 셈이다.
그러나 앞서 언급했듯 장비간 타임스탬프를 마이크로 세컨드 단위로 일치시키긴 힘드므로 NAT 환경등에선 사용할 수 없고 반드시 서버/클라이언트가 1:1로 직접 연결된 경우에만 사용해야 한다.
타임아웃
틀린 정보
net.ipv4.tcp_fin_timeout 을 설정하면 TIME_WAIT 타임아웃을 변경할 수 있다.
커널 헤더에 TIME_WAIT은 TCP_TIMEWAIT_LEN 이라는 상수로 60초 하드 코딩 되어 있으며 변경할 수 없다.
// include/net/tcp.h
#define TCP_TIMEWAIT_LEN (60*HZ) /* how long to wait to destroy TIME-WAIT
* state, about 60 seconds */
#define TCP_FIN_TIMEOUT TCP_TIMEWAIT_LEN
/* BSD style FIN_WAIT2 deadlock breaker.
* It used to be 3min, new value is 60sec,
* to combine FIN-WAIT-2 timeout with
* TIME-WAIT timer.
*/
커널 코드 주석에서 보듯 예전에는 FIN_WAIT2와 TIME_WAIT을 합쳐 3분으로 관리했으나 옛날(deprecated) 이야기이며, 지금은 각각 60초로 관리한다. 이 중 sysctl로 변경 가능한 값은 TCP_FIN_TIMEOUT 뿐이다. TCP_FIN_TIMEOUT은 FIN_WAIT2의 대기 시간이며 TIME_WAIT과는 무관하다.
FIN_WAIT2는 Active Close를 했는데 Passive Close 쪽에서 close()를 처리하지 못하고 CLOSE_WAIT 상태에 빠졌을때를 말한다. 즉, 상대방에 문제가 있는 상태로, 일정 시간 기다려 주는게 좋다.
TIME_WAIT의 대기 시간이 tcp_fin_timeout 설정에 영향을 받는다는 내용은 옛날 이야기이며 지금은 오히려 그 반대인 TCP_TIMEWAIT_LEN 상수값이 FIN_WAIT2의 대기시간에 영향을 끼친다. 아래 커널 코드에서 확인할 수 있다.
// include/net/tcp.h
static inline int tcp_fin_time(const struct sock *sk)
{
int fin_timeout = tcp_sk(sk)->linger2 ? : sysctl_tcp_fin_timeout;
const int rto = inet_csk(sk)->icsk_rto;
if (fin_timeout < (rto << 2) - (rto >> 1))
fin_timeout = (rto << 2) - (rto >> 1);
return fin_timeout;
}
// net/ipv4/tcp.c
if (sk->sk_state == TCP_FIN_WAIT2) {
struct tcp_sock *tp = tcp_sk(sk);
if (tp->linger2 < 0) {
tcp_set_state(sk, TCP_CLOSE);
tcp_send_active_reset(sk, GFP_ATOMIC);
NET_INC_STATS_BH(sock_net(sk),
LINUX_MIB_TCPABORTONLINGER);
} else {
const int tmo = tcp_fin_time(sk);
if (tmo > TCP_TIMEWAIT_LEN) {
inet_csk_reset_keepalive_timer(sk,
tmo - TCP_TIMEWAIT_LEN);
} else {
tcp_time_wait(sk, TCP_FIN_WAIT2, tmo);
goto out;
}
}
}
// net/ipv4/tcp_timer.c
if (sk->sk_state == TCP_FIN_WAIT2 && sock_flag(sk, SOCK_DEAD)) {
if (tp->linger2 >= 0) {
const int tmo = tcp_fin_time(sk) - TCP_TIMEWAIT_LEN;
if (tmo > 0) {
tcp_time_wait(sk, TCP_FIN_WAIT2, tmo);
goto out;
}
}
tcp_send_active_reset(sk, GFP_ATOMIC);
goto death;
}
먼저 tcp.h 코드를 보면 tcp_fin_timeout 설정은 링거 옵션에 영향을 받는다. 링거에 대해선 이후에 다시 설명한다.
그리고 tcp.c 코드에는 FIN_WAIT2 상태일때 대기 시간 설정 로직이 있다. tcp_fin_time()을 호출한 tcp_fin_timeout 값이 만약 TCP_TIMEWAIT_LEN 상수보다 크면 그 시간을 뺀만큼을 기다리게 되는데, 곧바로 timewait 타이머가 동작하는게 아니라 먼저 keepalive 상태는 그대로 두고 TCP_TIMEWAIT_LEN 값인 60초를 뺀만큼 타이머만 설정한다. 이 시간이 종료된 다음 tcp_timer.c 에선 timewait 상태로 변환하고 다시 타이머를 구동하는데 마찬가지로 TCP_TIMEWAIT_LEN 60초 뺀만큼 구동한다. 따라서 keepalive / timewait 두 번의 FIN_WAIT2 타이머가 동작한다.
즉, 리눅스 커널의 TCP_TIMEWAIT_LEN의 상수값은 FIN_WAIT2의 대기 시간에 영향을 끼친다. TIME_WAIT은 항상 60초 이므로 만약 tcp_fin_timeout을 60 이상으로 설정한다면 위에서 언급한대로 keepalive 타이머가 먼저 동작한다. 만약 60보다 작은 값을 설정하면 그냥 그 시간 만큼 timewait 타이머만 동작한다. 기본값은 60이므로 원래는 60초만큼 FIN_WAIT2 / timewait 상태로 기다리게 된다.
그렇다면 tcp_fin_timeout을 90으로 설정하고 실제로 그렇게 동작하는지 확인해본다. 90인 경우 60초를 뺀 FIN_WAIT2 / keepalive 로 30초, FIN_WAIT2 / timewait 으로 30초를 기다릴 것이다. 서버는 정확히 45초 후에 ACK을 보내도록 설정해봤다. 그렇게 하면 45초 이후 TIME_WAIT 상태가 되어 다시 60초 간 유지될 것이다. 실제로 그렇게 동작하는지 확인해본다.
$ while true; do ss -tanop | grep 5000; sleep 1; done
FIN-WAIT-2 0 0 10.51.31.141:50094 10.51.31.140:5000 timer:(keepalive,29sec,0)
FIN-WAIT-2 0 0 10.51.31.141:50094 10.51.31.140:5000 timer:(keepalive,28sec,0)
...
FIN-WAIT-2 0 0 10.51.31.141:50094 10.51.31.140:5000 timer:(keepalive,2.067ms,0)
FIN-WAIT-2 0 0 10.51.31.141:50094 10.51.31.140:5000 timer:(keepalive,1.020ms,0)
FIN-WAIT-2 0 0 10.51.31.141:50094 10.51.31.140:5000 timer:(timewait,29sec,0)
FIN-WAIT-2 0 0 10.51.31.141:50094 10.51.31.140:5000 timer:(timewait,28sec,0)
...
FIN-WAIT-2 0 0 10.51.31.141:50094 10.51.31.140:5000 timer:(timewait,16sec,0)
FIN-WAIT-2 0 0 10.51.31.141:50094 10.51.31.140:5000 timer:(timewait,15sec,0)
TIME-WAIT 0 0 10.51.31.141:50094 10.51.31.140:5000 timer:(timewait,59sec,0)
TIME-WAIT 0 0 10.51.31.141:50094 10.51.31.140:5000 timer:(timewait,58sec,0)
...
TIME-WAIT 0 0 10.51.31.141:50097 10.51.31.140:5000 timer:(timewait,1.188ms,0)
TIME-WAIT 0 0 10.51.31.141:50097 10.51.31.140:5000 timer:(timewait,141ms,0)
정확하게 예상한대로 동작함을 확인할 수 있다.
FIN_WAIT2에서 ACK을 받지 못하면 소켓은 곧바로 종료된다. 따라서 리눅스 커널은 FIN_WAIT2를 TIME_WAIT처럼 활용하고 있다. TIME_WAIT은 패킷의 오동작을 막아주는 역할을 하는데 FIN_WAIT2 / timewait 상태는 tcp_tw_recycle 처리와 일부 잘못된 패킷 처리 로직이 상단에 추가된 형태로 사실상 TIME_WAIT과 동일한 역할을 한다.
// net/ipv4/tcp_minisocks.c
enum tcp_tw_status
tcp_timewait_state_process(struct inet_timewait_sock *tw, struct sk_buff *skb,
const struct tcphdr *th)
{
...
if (tw->tw_substate == TCP_FIN_WAIT2) {
/* Just repeat all the checks of tcp_rcv_state_process() */
/* Out of window, send ACK */
if (paws_reject ||
!tcp_in_window(TCP_SKB_CB(skb)->seq, TCP_SKB_CB(skb)->end_seq,
tcptw->tw_rcv_nxt,
tcptw->tw_rcv_nxt + tcptw->tw_rcv_wnd))
return tcp_timewait_check_oow_rate_limit(
tw, skb, LINUX_MIB_TCPACKSKIPPEDFINWAIT2);
if (th->rst)
goto kill;
...
// `FIN_WAIT2`인 경우 `TIME_WAIT`의 처리 함수에
// 상단에 몇 가지 패킷 처리가 추가 되어 동일하게 동작한다.
...
}
/*
* Now real TIME-WAIT state.
* 실제 `TIME_WAIT` 상태에 대한 처리
*/
그래서 net.ipv4.tcp_fin_timeout 값은 90 정도로. FIN_WAIT2의 keepalive / timewait 이 모두 일정시간 동작할 수 있도록 설정하는 값을 추천한다.
재시도
명칭이 비슷하여 혼동할 수 있으나 FIN_WAIT1은 FIN_WAIT2와 다른 상태다. FIN을 보내주길 하염없이 기다리기만 하는 FIN_WAIT2와 달리 FIN_WAIT1은 우리가 보낸 최초 FIN에 대해 아직 ACK 응답이 도달하지 않은 상태로, 일반적으로 상대방 OS에 문제가 있는 경우로 간주할 수 있다. 왜냐면 최초 ACK 응답은 OS가 리눅스라면 커널이, 윈도우라면 시스템이 바로 보내야 하는 패킷이기 때문이다.
또한 기다리기만 하는게 아니라 지속적으로 FIN을 재시도한다. 첫 패킷에는 2초, 그 다음 부터는 5초, 10초. 대기시간을 늘려가며, 따로 커널 설정을 변경하지 않은 서버에서 최대 8번까지 재시도 하는 것을 확인할 수 있었다.
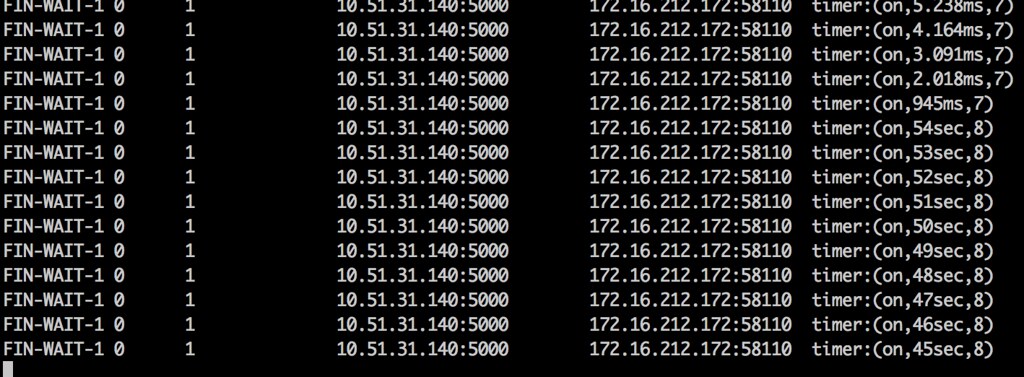
마지막 8번째가 55초 대기하는 것을 포함, 총 2분 정도 대기했으며 마지막까지 ACK을 수신하지 못할 경우 결국 소켓은 종료된다. 대기 시간이 길고, 재시도 횟수와 대기 시간을 조정할 수 있는 커널 설정 까진 미처 확인하지 못했지만 상대방 OS에 문제가 있는 상태인 만큼 새로운 연결 SYN에도 응답하지 않을 것이고, 해당 IP와는 더 이상 연결이 불가능해질 것이다.
링거
소켓에는 데이타가 아직 남아 있을때 종료 방식을 결정하는 링거 옵션이 있다. 아래 3가지 경우로 나뉜다.
struct linger {
int l_onoff; /* option on/off */
int l_linger; /* linger time */
};
l_onoff = 1,l_linger = 0: 즉시 종료하고 버퍼에 남아 있는 데이타는 버린다. 비정상 종료로RST를 보내고 즉시 연결을 끊는다.RST의 동작에 관해서는 아래에 다시 설명한다.l_onoff = 1,l_linger = non-zero: 명시된 시간(초)동안 정상적으로 진행하며 그 이후에는 비정상 종료 처리한다. 만일 버퍼에 전송되지 못한 메시지가 남아 있다면 명시된 시간 동안은 어플리케이션이close()를 진행하지 못하고 최종적으로RST를 보내기 위해sleep상태에서 대기하기 때문에 어플리케이션 지연 현상이 발생하므로 유의해야 한다. non-blocking 으로 동작하는 것도 가능은 하다.l_onoff = 0: 정상적인 4-way handshake 종료 과정을 진행하며 소켓의 기본값이다.
RST 는 비정상 종료시 보내는 패킷이다. 수신한 상대방은 Connection reset by peer 오류가 나게 된다.
양쪽 모두 바로 연결이 끊어지며, 양쪽 모두 TIME_WAIT 상태가 남지 않는다는 점에서 가장 빠르고 깔끔해 유용해보이지만 문제는 비정상 종료라는 점이다. RST는 더 이상 연락하지 말자는 일방적인 이별 통보로, 또다른 side effects를 야기할 수 있다. 또한 양쪽 모두에 TIME_WAIT을 남기지 않기 때문에 패킷의 오동작을 막아줄 장치가 없다.
어떠한 TIME_WAIT도 남아 있지 않아야 할 특수한 목적이 아니라면, 일반적으로는 링거 옵션을 사용하지 않아야 하고 RST 비정상 종료 패킷을 보내는 일이 없어야 한다.
결론
TCP/IP Illustrated를 쓴 리차드 스티븐스의 또 다른 책 Unix Network Programming에는 이런 구절2이 있다.
The
TIME_WAITstate is our friend and is there to help us (i.e., to let old duplicate segments expire in the network). Instead of trying to avoid the state, we should understand it.
TIME_WAIT은 우리를 도와주는 친구다. 네트워크에서 오래된 중복 세그먼트를 날려주는 훌륭한 역할을 한다. 자꾸 없애려고 노력하지 말고 이해해야 한다.
TIME_WAIT은 패킷의 오동작을 막아주는 우리의 친구같은 존재다.
수 많은 잘못된 정보들 사이에서 아래와 같은 올바른 정보를 반드시 기억해두길 바란다.
TIME_WAIT의 타임아웃은 60초로 하드 코딩되어 있다. 설정할 수 없다.- 다수의
TIME_WAIT이 서버 성능을 저하시킨다는 논문5은 1997년에 출판됐다. 지금은 2016년이다. 20년이 지났다. - 클라이언트가 서버 투 서버로 한 서버에 요청이 많을 경우
tcp_tw_reuse옵션을 설정해TIME_WAIT을 재사용하도록 한다. 서버는 해당 사항이 없다. - 오래된 서버인 경우 클라이언트가 서버 투 서버 통신을 많이 한다면 빈 포트 스캔으로 성능 저하가 발생하므로 마찬가지로
tcp_tw_reuse옵션을 설정한다. tcp_tw_reuse와SO_REUSEADDR는 서로 다른 소켓에 적용되는 옵션이다.- 서버/클라이언트 모두
tcp_timestamps가 기본값인 켜져 있어야 하며, 끄면 안되고 끌 필요도 없다. net.ipv4.tcp_fin_timeout은 90 정도로 설정한다.FIN_WAIT1은 상대방 OS에 문제가 있는 경우다.FIN_WAIT2는 상대방 어플리케이션에 문제가 있는 경우다.FIN_WAIT2는TIME_WAIT의 역할을 대행한다.- 특수한 경우가 아니면 링거 옵션은 사용하지 않는다.
- 서버가 클라이언트를
accept()할때 할당하는 것은 소켓이다. 포트가 아니다. - 소켓의 최대 갯수는 65,535개가 아니다. 소켓은 <protocol>, <src addr>, <src port>, <dest addr>, <dest port> 5개의 값으로 유니크하게 구성되며, 서버 포트 또는 클라이언트의 IP가 추가될 경우 그 만큼의 새로운 쌍을 생성할 수 있다.
TL;DR
- 서버는 아무것도 할 필요가 없다.
- 클라이언트9는
net.ipv4.tcp_tw_reuse를 1로 설정한다. - 서버와 클라이언트가 NAT 없이 1:1 로 직접 연결되어 있다면 압도적인 성능을 보이는
net.ipv4.tcp_tw_recycle을 적극 활용한다.
참고 문헌
-
http://vincent.bernat.im/en/blog/2014-tcp-time-wait-state-linux.html ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
http://www.quora.com/What-is-the-ideal-design-for-server-process-in-Linux-that-handles-concurrent-socket-I-O ↩
-
http://www.isi.edu/touch/pubs/infocomm99/infocomm99-web/ ↩ ↩2 ↩3
-
여기서 말하는 클라이언트란 일반적인 클라이언트가 아니라, 서버 투 서버로 대용량으로 접속하는 클라이언트를 말한다. ↩