

머신러닝 분류기
Regression Analysis
선형 회귀와 로지스틱 회귀는 같은 기본 수식을 사용하지만 선형은 연속된 값 Y를 찾는 반면, 로지스틱은 분류 결과를 찾는다. 즉, 0 또는 1의 값을 도출한다.
그림으로 잘 설명한 선형/로지스틱 회귀, 이 사람의 그림으로 쉬운 설명에 감동해 책 『Grokking Algorithms』도 구매해서 읽음
로지스틱 회귀는 전통적으로 two-class classification에 제한적이다. 분류가 2 종류를 초과할 경우 LDALinear Discriminant Analysis 알고리즘이 주로 선호되는 linear classification technique이다.
k-Means Clustering

(통계학 도감, 2017)
scree plot
 (Wikipedia)
(Wikipedia)
적당한 군집 갯수를 결정하기 위해 스크리 플롯을 사용한다. 급격히 구부러지는 지점 kinks가 최적의 군집 갯수다. k-Means 또는 주성분 갯수를 구하기 위한 PCA에서도 사용한다.
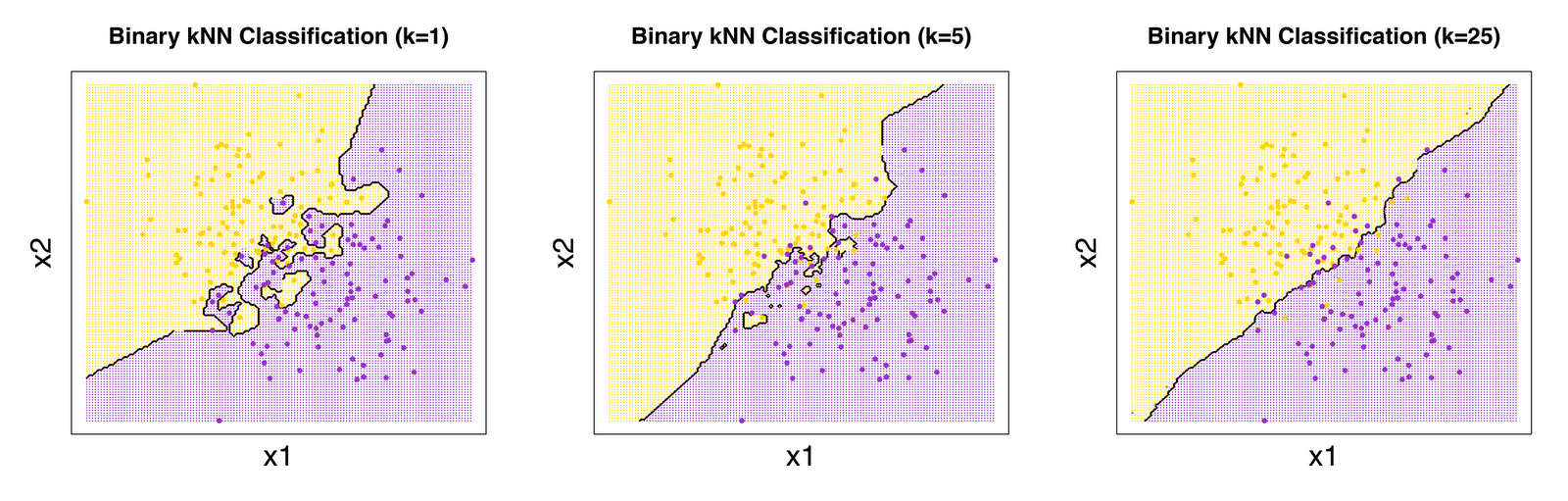
k-Nearest Neighbors(KNN)
k개의 최근접 이웃 사이에서 가장 많은 항목으로 분류. ‘가까움’은 유클리드 거리Euclidean distance 주로 사용. scikit-learn에서는 분류/회귀 모두 제공. 복잡한 벡터에서 k가 클수록 오버피팅이 줄어들어 부드러운 경계가 생긴다.
(Classification of Hand-written Digits)
Ridge, Lasso
Linear Regression
- L2 정규화 Ridge
- L1 정규화 Lassoleast absolute shrinkage and selection operator
Last Modified: 2021/06/08 13:03:45