

Support Vector Machine
특징
- 서포트 벡터 머신은 두 그룹의 주변 데이터 포인트(서포트 벡터) 사이의 가운데를 따라 경계선을 그림으로써 데이터 포인트를 두 그룹으로 분류한다.
- SVM은 이상값에 대해 견고함을 얻기 위해 특정 개수 이하의 학습 데이터 포인트가 경계를 넘어 틀린 영역으로 넘어가도록 허용하는 완충 지대buffer zone를 이용한다. 이에 더해 곡선 형태의 경계를 효율적으로 도출하고자 커널 트릭을 이용한다.
(수학 없이 배우는 데이터 과학과 알고리즘, 2017)
linear
SVM은 large margin classification이다.
scikit-learn: C
모든 샘플이 올바르게 분류되어 있다면 이를 hard margin classification이라고 한다. 그러나 outlier가 있을 경우 large margin과 margin violation 사이에 적절한 균형을 잡아야 한다. 이를 soft margin classification이라 한다. scikit-learn에서는 C 하이퍼파라미터를 사용해 이 균형을 조절할 수 있다. (핸즈온 머신러닝, 2017)
C를 줄이면 margin violation이 커진다. SVM이 overfitting이라면 C를 감소시켜 모델을 regularization 할 수 있다.
scikit-learn에서 SVM의 서포트 벡터는 model.support_vectors_로 찾을 수 있다.
non-linear
『Introduction to Machine Learning with Python』의 hyperplane을 이용한 SVM 분류 참고.
polynomial kernel
polynomial features를 추가하는 것은 간단하고(SVM 뿐만 아니라) 모든 머신러닝 알고리즘에서 잘 작동합니다. 하지만 낮은 차수의 다항식은 매우 복잡한 데이터셋을 잘 표현하지 못하고 높은 차수의 다항식은 굉장히 많은 특성을 추가하므로 모델을 느리게 만듭니다.
다행히도 SVM을 사용할 땐 kernel trick이라는 기적에 가까운 수학적 기교를 사용할 수 있습니다. (핸즈온 머신러닝, 2017)
gaussian rbf kernel
similarity features를 추가하는 방식
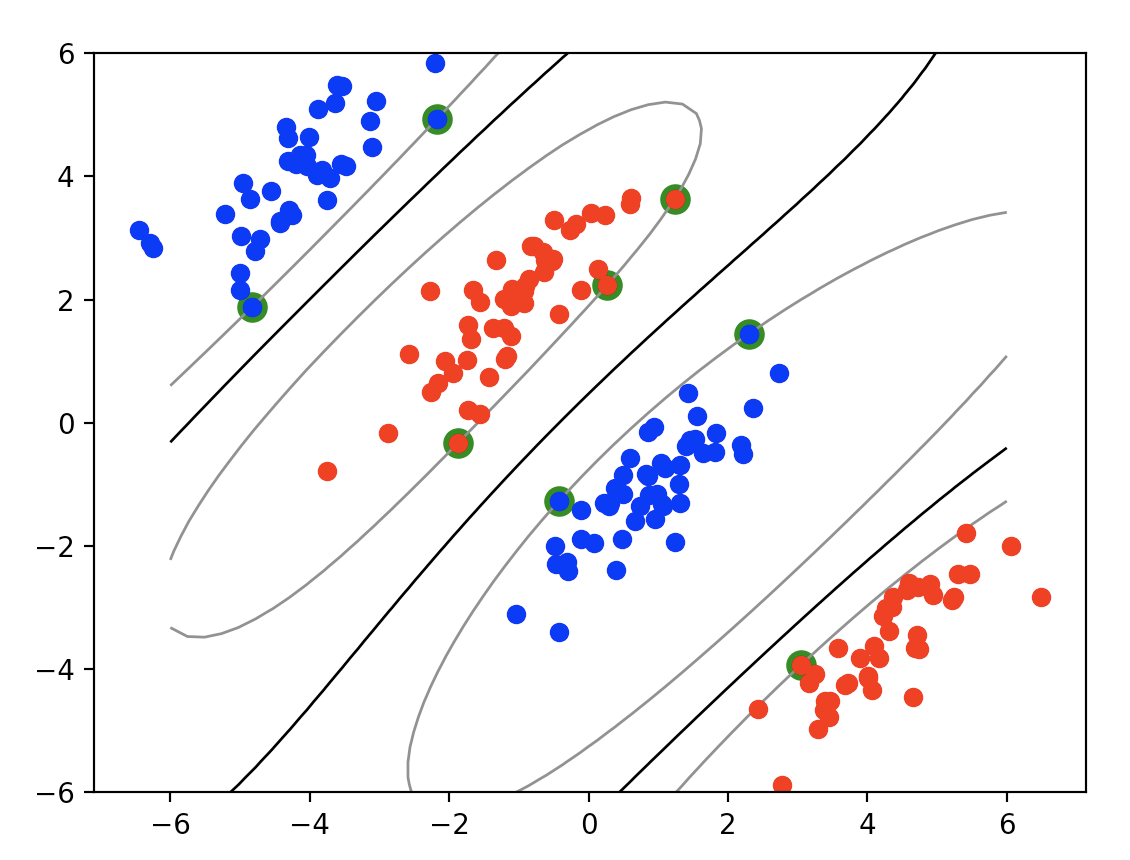
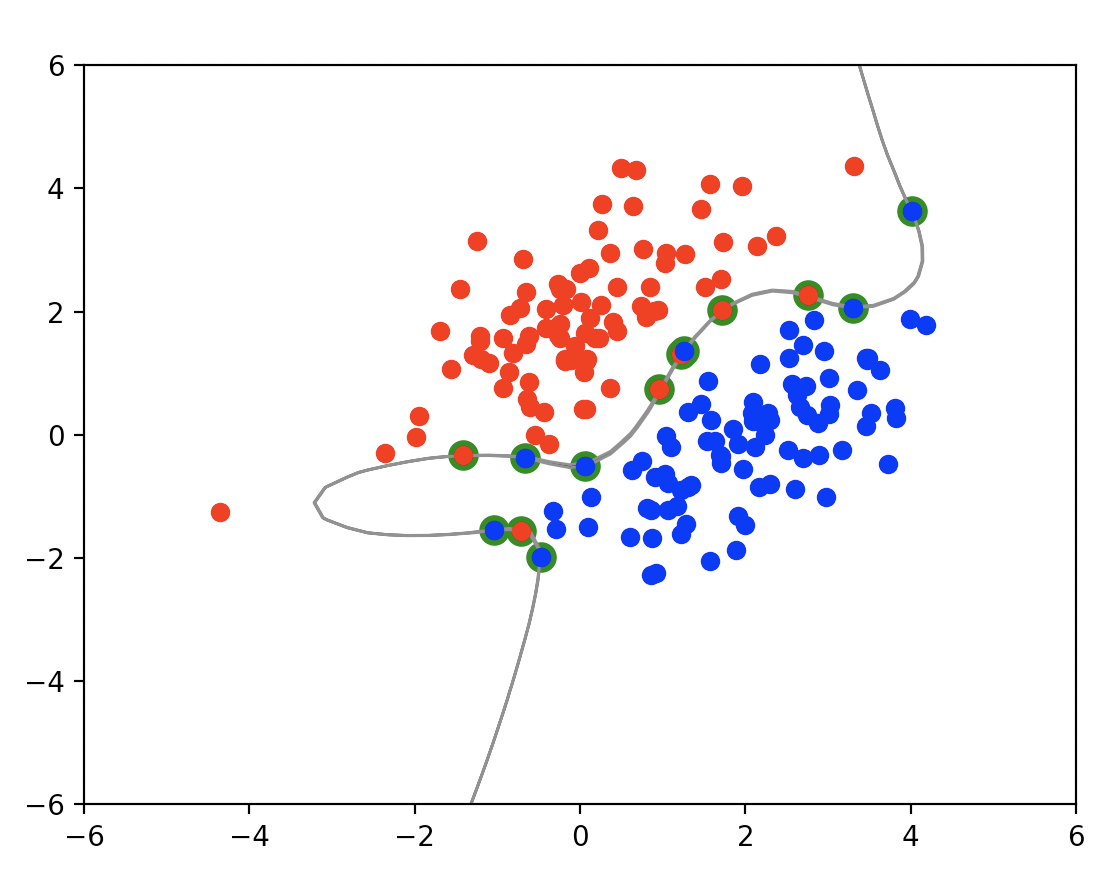
가우시안 커널Gaussian; Radial Basis Function Kernel을 적용한 SVM 분류 도식화(Numpy로만 구현)으로 위 그래프를 표현했다.
기타
선형 커널을 가장 먼저 시도해봐야 한다. LinearSVC가 SVC(kernel="linear")보다 훨씬 빠르다. 특히 학습셋이 크거나 피처가 많을때 그렇다. 학습셋이 너무 크지 않다면 gaussian rbf 커널을 시도해보면 좋다.
LinearSVC 구현은 liblinear를 기반으로 하며, SVC는 libsvm 라이브러리를 기반으로 한다. LinearSVC는 large margin classification이며, SVC는 kernel trick을 사용한다.
SVM을 만든 Vladimir N. Vapnik은 78세인 2014년 페이스북 AI 리서치 합류했다.
Last Modified: 2021/06/08 13:03:45