
CLOSE_WAIT 문제 해결
2015년 5월 23일 초안 작성
서론
서버 부하 테스트 과정 중 일정 시간이 경과하면 점점 더 느려지면서 행업 상태에 빠지는 경우가 생겼다. 부하가 높으면 느려지는건 당연한 일이지만 문제는 테스트가 끝나도 행업 상태에서 복구되지 않았다는 점이다. 이는 담당자가 매 번 상태를 확인하고 복구해야 함을 뜻하며 서비스에는 도입할 수 없을 정도로 치명적이다. 분명히 특정한 원인이 있을 것이며 그에 따른 적절한 해결책이 존재할 것이다.
현상
먼저 행업 직전, 8080으로 서비스 중인 포트 상황은 아래와 같다.
$ lsof -i:8080
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 27836 hanadmin 1712r IPv4 844147418 0t0 TCP 10.41.249.26:webcache->10.51.31.149:60494 (CLOSE_WAIT)
java 27836 hanadmin 1720r IPv4 844143466 0t0 TCP 10.41.249.26:webcache->10.51.31.149:60133 (CLOSE_WAIT)
java 27836 hanadmin 1749u IPv4 844151483 0t0 TCP 10.41.249.26:webcache->10.51.31.152:50739 (CLOSE_WAIT)
java 27836 hanadmin 1754w IPv4 844155954 0t0 TCP 10.41.249.26:webcache->10.51.31.149:61397 (ESTABLISHED)
java 27836 hanadmin 1755u IPv4 844151485 0t0 TCP 10.41.249.26:webcache->10.51.31.150:36813 (CLOSE_WAIT)
java 27836 hanadmin 1764u IPv4 844145322 0t0 TCP 10.41.249.26:webcache->10.51.31.149:60331 (CLOSE_WAIT)
java 27836 hanadmin 1772u IPv4 844146275 0t0 TCP 10.41.249.26:webcache->10.51.31.152:50196 (CLOSE_WAIT)
...ESTABLISHED 한 개를 제외한 나머지 모두가 CLOSE_WAIT 상태이다. 이 상태에서 꾸준히 증가하다 해당 서버의 경우 4,023개째에서 행업된다.
$ netstat -tonp
tcp 1 0 10.41.249.26:8080 10.51.31.150:16011 CLOSE_WAIT 27836/java keepalive (7196.98/0/0)
tcp 1 0 10.41.249.26:8080 10.51.31.149:40471 CLOSE_WAIT 27836/java keepalive (7197.80/0/0)
tcp 1 0 10.41.249.26:8080 10.51.31.150:16287 CLOSE_WAIT 27836/java keepalive (7197.62/0/0)
tcp 1 0 10.41.249.26:8080 10.51.31.149:40484 CLOSE_WAIT 27836/java keepalive (7197.83/0/0)
tcp 1 0 10.41.249.26:8080 10.51.31.151:30980 CLOSE_WAIT 27836/java keepalive (7197.09/0/0)
tcp 1 0 10.41.249.26:8080 10.51.31.152:30272 CLOSE_WAIT 27836/java keepalive (7197.76/0/0)
tcp 1 0 10.41.249.26:8080 10.51.31.152:30147 CLOSE_WAIT 27836/java keepalive (7197.46/0/0)
...netstat 상태도 마찬가지인데 -o 옵션으로 networking timer를 살펴 봐도 거의 2시간이 설정되어 있어 의미가 없고 이 상태에서 종료되지 않고 점점 증가한다.
참고: netstat을 sudo로 실행하면 프로세스 명이 구체적으로 표시된다.
TCP 상태
먼저 네트워크 서적의 바이블격인 TCP/IP Illustrated 에 등장하는 TCP 커넥션 다이어그램은 아래와 같다.
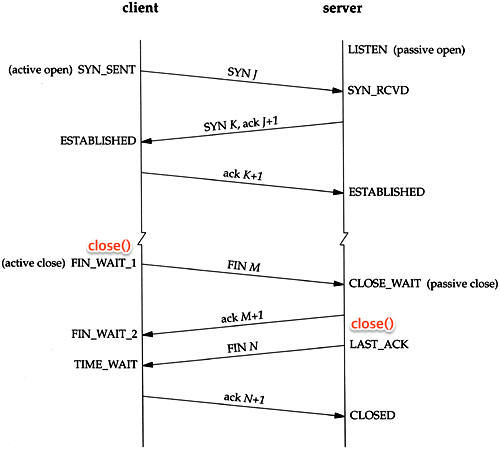
이 중 ESTABLISHED 이후 종료 과정에서 어플리케이션의 close() 호출 부분을 추가로 표시해봤다. Active Close 쪽이 먼저 close()를 수행하고 FIN을 보내면 Passive Close 쪽은 ACK을 보낸 후 어플리케이션의 close()를 수행한다. 보다 상세한 과정은 아래와 같다.
- 먼저
close()를 실행한 클라이언트가FIN을 보내고FIN_WAIT1상태로 대기한다. - 서버는
CLOSE_WAIT으로 바꾸고 응답ACK를 전달한다. 그와 동시에 해당 포트에 연결되어 있는 어플리케이션에게close()를 요청한다. ACK를 받은 클라이언트는 상태를FIN_WAIT2로 변경한다.close()요청을 받은 서버 어플리케이션은 종료 프로세스를 진행하고FIN을 클라이언트에 보내LAST_ACK상태로 바꾼다.FIN을 받은 클라이언트는ACK를 서버에 다시 전송하고TIME_WAIT으로 상태를 바꾼다.TIME_WAIT에서 일정 시간이 지나면CLOSED된다.ACK를 받은 서버도 포트를CLOSED로 닫는다.
한 가지 주의할 점은 클라이언트와 서버의 지칭인데, 반드시 서버만 CLOSE_WAIT 상태를 갖는 것은 아니다. 왜냐면 서버가 먼저 종료하겠다고 FIN을 보낼 수 있기 때문에 이 경우 서버측이 FIN_WAIT1이 될 수 있다.
따라서 표현을 클라이언트와 서버가 아닌 Active Close(또는 Initiator, 기존 클라이언트)와 Passive Close(또는 Receiver, 기존 서버) 정도로 구분하는게 올바르다.
CLOSE_WAIT 재현
CLOSE_WAIT을 아래와 같이 Java 코드로 재현 했다.1 아래 예제에서도 서버가 먼저 FIN을 보내 클라이언트가 CLOSE_WAIT 상태에 빠지는 것을 보여준다.
// Server.java (sends some data and exits)
package com.company;
import java.io.IOException;
import java.io.OutputStream;
import java.net.ServerSocket;
import java.net.Socket;
public class Server {
public static void main(String[] args) {
try {
Socket socket = new ServerSocket(12345).accept();
OutputStream out = socket.getOutputStream();
out.write("Hello World\n".getBytes());
out.flush();
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
// Client.java (will sleep in CLOSE_WAIT)
package com.company;
import java.io.InputStream;
import java.net.InetAddress;
import java.net.Socket;
public class Client {
public static void main(String[] args) throws Exception {
Socket socket = new Socket(InetAddress.getByName("localhost"), 12345);
InputStream in = socket.getInputStream();
int c;
while ((c = in.read()) != -1) {
System.out.write(c);
}
System.out.flush();
// should now be in CLOSE_WAIT
Thread.sleep(Integer.MAX_VALUE);
}
}각각 양쪽의 서버/클라이언트를 실행하면 클라이언트가 CLOSE_WAIT 상태에 빠지는 것을 확인할 수 있다. 아울러 클라이언트가 행업되어 있는 동안에는 이 상태가 사라지지 않는다.
아래는 상기 예제를 맥에서 실행하고 netstat 를 실행한 모습이다. 참고로 맥(BSD 계열)과 리눅스의 netstat 옵션은 많이 다르다.
$ netstat -p tcp -a -n | grep CLOSE_WAIT | grep 12345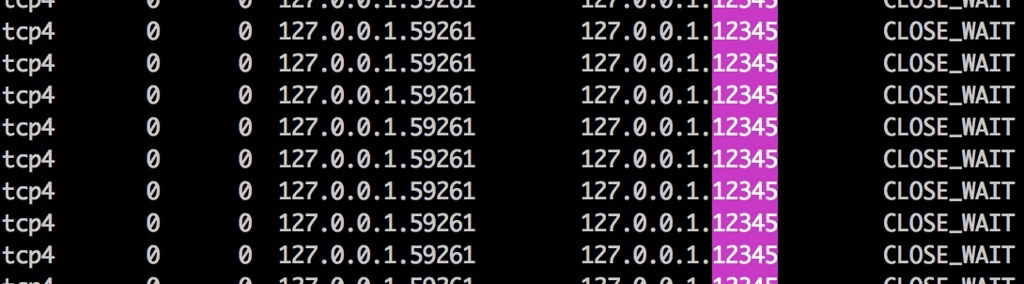
10분이 지나도 CLOSE_WAIT 상태가 계속 변하지 않음을 확인한 모습이다.
아울러 Passive Close 측이 CLOSE_WAIT 상태에 빠지면 Active Close 측은 FIN을 못 받는 상태이기 때문에 FIN_WAIT2에서 마찬가지로 대기하게 된다. 하지만 FIN_WAIT2는 CLOSE_WAIT과 달리 일정 시간이 경과하면 스스로 TIME_WAIT 상태가 된다. CentOS 6의 경우 net.ipv4.tcp_fin_timeout에 60초로 설정되어 있다.
$ netstat -ton
tcp 0 0 10.41.249.26:8080 10.51.31.149:40484 FIN_WAIT2 timewait (28.29/0/0)참고로 TIME_WAIT는 2*MSL(Maximum Segment Lifetime)으로 60초다.
CLOSE_WAIT 종료
커널 옵션으로 타임아웃 조절이 가능한 TIME_WAIT, FIN_WAIT과 달리 CLOSE_WAIT는 포트를 잡고 있는 프로세스의 종료 또는 네트워크 재시작 외에는 제거할 방법이 없다. 즉, 로컬 어플리케이션이 정상적으로 close()를 요청하는 것이 가장 좋은 방법이다.
You can’t (and shouldn’t). CLOSE_WAIT is a state defined by TCP for connections being closed waiting for the counterpart to acknowledge this.2
No, there is no timeout for CLOSE_WAIT. I think that’s what the off means in your output. To get out of CLOSE_WAIT, the application has to close the socket explicitly (or exit).3
Since there is no CLOSE_WAIT timeout, a connection can stay in this state forever (or at least until the program does eventually close the connection or the process exists or is killed).
If you cannot fix the application or have it fixed, the solution is to kill the process holding the connection open.4
저마다 강조하는 바를 살펴봐도 CLOSE_WAIT는 커널 옵션이나 설정으로 타임아웃을 줄 수 없으며 로컬 어플리케이션의 문제이기 때문에 정상적인 문제 해결이 필요하다는 지적을 하고 있다.
원인
그렇다면 해당 서버의 CLOSE_WAIT 상태 원인은 무엇일까. 자바로 만든 웹 서비스이므로 행업 상태인 해당 JVM의 Thread Dumps 를 분석했다.
$ jstack 27836
"http-apr-8080-exec-24" daemon prio=10 tid=0x00007f9240054800 nid=0x6cc1 waiting on condition [0x00007f9271964000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x0000000797283fc8> (a java.util.concurrent.FutureTask)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:186)
at java.util.concurrent.FutureTask.awaitDone(FutureTask.java:425)
at java.util.concurrent.FutureTask.get(FutureTask.java:187)
at java.util.concurrent.AbstractExecutorService.invokeAll(AbstractExecutorService.java:243)
at net.daum.crystal.core.execute.SearchManager.search(SearchManager.java:104)
at net.daum.crystal.core.execute.SearchManager.search(SearchManager.java:163)
...그 결과 대부분의 쓰레드가 검색 결과를 받아오지 못하고 대기중(WAITING)인 상태가 확인됐다. 그런데 재밌게도 이 검색 결과는 로컬에서 받아오는 것이다. 즉, 로컬은 행업 상태여서 검색 결과를 보내주지 못하는 상황이고 쓰레드는 검색 결과를 받기 위해 대기하는 상황이다.
원래 일정 시간이 경과하면 타임아웃으로 끊어야 하는데 행업 상태에 빠지다보니 이 조차도 처리되지 못하고 서로 기다리는 상황이었다.
즉, 보낼 수도 없고 받을 수도 없는 일종의 교착 상태(deadlock)가 원인으로 지목됐다. 아울러 이 상태는 성능 테스트가 끝나도 정상으로 복구되지 않았다.
이 부분을 좀 더 구체적으로 설명하면,
- 파일서버가 필요해 별도 웹 서버를 구성하지 않고 톰캣의
/ROOT를 이용 - static html 파일을 올려두고 톰캣에서 구동중인 웹앱의
HttpClient에서 로컬 자기 자신(동일한 톰캣)을 호출해 html을 받아가도록 구성 - 그러나, 부하를 높이니 점점 느려지다 html 조차 내려주지 못하는 행업 상태 발생
- 모든 소켓이
CLOSE_WAIT상태에 빠짐
결론
요청과 응답을 받는 과정에서 recursive 한 호출이 교착 상태의 원인이었으며 별도 서버를 구성하여 상호 의존성 없이 호출 가능하도록 구성했다. 동일 WAS가 아닌, 별도의 nginx를 구성하고 다른 프로세스에서 html 파일을 내려주도록 처리 했다.
테스트 결과 더 이상 문제가 발생하지 않음을 확인 했다.