
CNN을 이용한 한국어 문장 분류
2018년 3월 24일 문장 편집
2016년 12월 16일 초안 작성
- 서론
- 본론
- 전처리(NLP Preprocessing)
- 데이터
- 모델
- 구현
- Embedding Layer
- Convolution and Max-Pooling Layers
- Dropout Layer
- Scores and Predictions
- Loss and Accuracy
- Visualizing the Network
- Instantiating the CNN and Minimizing the Loss
- Summaries
- Initializing the Variables
- Defining a Single Training Step
- Training Loop
- Visualizing Results in Tensorboard
- Extensions and Exercises
- 코드
- References
서론
CNN 알고리즘은 주로 이미지의 특징을 추출하여 유사점을 찾는 이미지 판단에 사용된다. 합성곱convolution이 핵심으로 매트릭스에 적용하는 슬라이딩 윈도우 함수를 생각하면 이해하기 쉽다.1

왼쪽 매트릭스가 흑백 이미지를 표현한다면 각 엔트리는 1 픽셀의 0 검정, 1 흰색으로 간주할 수 있고 슬라이딩 윈도우는 3x3 필터를 사용하여 매트릭스의 엘리먼트 와이즈 곱셈하여 합산한다. 그 결과 전체 매트릭스에 필터를 슬라이딩한 각 엘리먼트 전체 합성곱을 얻는다.

이를 겹겹이 쌓아올려 신경망을 구성하는데 위와 같이 이미지의 필터링된 합성곱(CONV), 활성화 함수(ReLU), 맥스 풀링(POOL) 과정을 반복하여 피쳐 벡터를 형성하고 학습된 이미지와 비교하여 유사도를 판별한다. Andrej Karpathy가 순수 JS로 구현한 CIFAR-10 시각화 데모는 각각의 출력이 어떻게 형성되는지 이해하는데 많은 도움이 된다.
이미지 뿐만 아니라 NLP에도 CNN 알고리즘을 적용하려는 노력이 있었고, 의미 있는 결과를 낸 논문들이 다수 출판됐다.
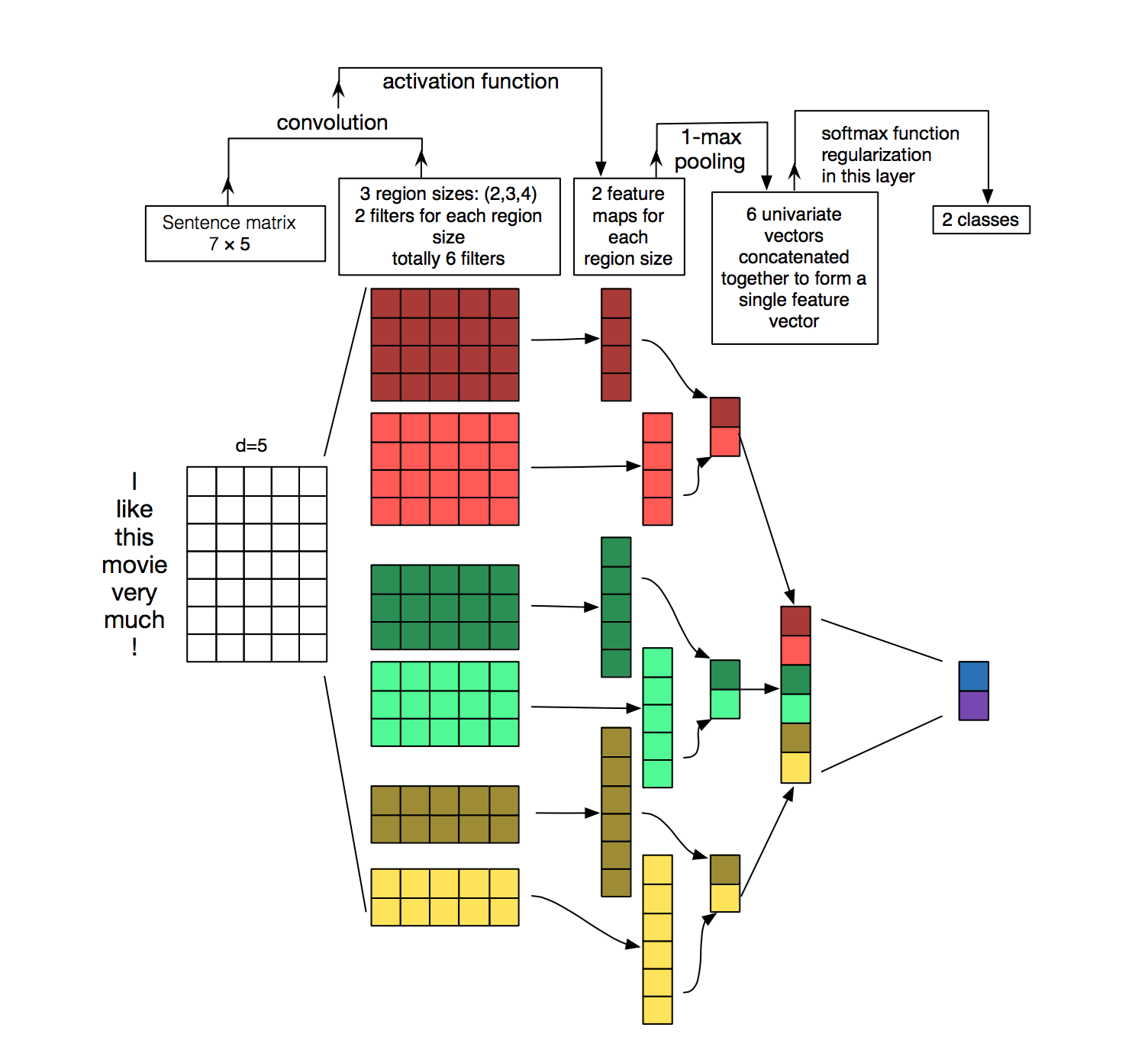
위 이미지는 A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification 논문에 등장한 문장 분류를 위한 합성곱 신경망(CNN) 아키텍처다. 초기에 단어를 벡터로 임베딩하는 과정이 진행되어야 함을 제외하면 이미지 분류와 크게 다르지 않다. 3개의 필터 사이즈 2,3,4를 각 두 개씩 총 6개를 문장 매트릭스에 합성곱을 수행하고 피쳐 맵을 생성한다. 이후 각 맵에 대해 맥스 풀링을 진행하여 각 피쳐 맵으로부터 가장 큰 수를 남긴다. 이들 6개 맵에서 단변량univariate 벡터가 생성되고, 이들 6개 피쳐는 두 번째 레이어를 위한 피쳐 벡터로 연결한다. 최종적으로 소프트맥스 레이어는 피쳐 값을 받아 문장을 분류한다. 여기서는 이진binary 분류를 가정했고 따라서 두 가지 가능한 출력 상태를 묘사했다.1
아울러 Yoon Kim이 문장 분류에 CNN을 적용한 논문을 발표했고 좋은 결과를 보였다. 이를 참고하여 구현한 문서가 IMPLEMENTING A CNN FOR TEXT CLASSIFICATION IN TENSORFLOW이며 여기서는 ‘원문’으로 표기하며 본 문서에 소개하는 대부분의 내용과 코드는 원문을 참조하여 작성했음을 미리 밝혀둔다.
본론
여타 논문과 달리 원문에서는 텐서플로우를 이용해 직접 실행 가능한 코드를 제공한다. 원본 코드는 깃헙에 있으며 이를 포크하여 몇몇 부분은 직접 개선했다. 특히 본 문서에서는 영어가 아닌 한국어 문장 분류를 위해 패치한 버전을 활용하도록 한다. 아울러 원문에는 긍정/부정의 이중 분류만 가능하도록 되어 있으나 마침 makinada라는 사용자가 다중 분류가 가능하도록 PR을 제공했고 본 문서를 작성하는 현 시점에 아직 업스트림에 머지 되진 않았으나 개선 버전에는 미리 적용하여 수정을 거쳐 실제 사용해 보기로 한다.
전처리(NLP Preprocessing)
먼저 입력값은 형태소 분석기를 통해 전처리된 어휘를 사용 한다. 원본 코드는 클린징 처리만 하여 그대로 사용하는데, 영어를 기준으로 구현되어 있어 한글의 경우 이 코드가 모든 한글을 날려버리므로 사용할 수 없다. 또한 한글은 조사등의 복잡한 언어 구조상 NLP 전처리 작업이 효율적이기 때문에 미리 처리하도록 한다. 한글로 작성된 아래 논문2에도 NLP 전처리를 미리 진행하는 형태로 모식도가 설계되어 있음을 확인할 수 있다.
NLP 전처리를 위해서는 한글 형태소 분석기가 필수적인데 여기서는 카카오 내부에서 사용중인 사내 형태소 분석기인 DHA를 사용했다. 우수한 형태소 분석기이지만 아쉽게도 사내 솔루션이며 외부에 공개되지 않는다. 대신 KoNLPy등의 오픈소스 형태소 분석기를 활용하면 유사한 결과를 얻을 수 있을 것이다.
데이터
한국어로 미리 형태소 분석 결과 100 문장을 학습 데이터로 제공했다. 평가 데이터는 10개 문장을 제공하여 10% 비율로 구성했다. 당연히 실제로 서비스를 하려면 이보다 훨씬 더 많은 데이터가 필요하며, 여기서는 간단한 진행 과정을 소개하기 위한 용도로 매우 적은 데이터만 사용하도록 한다. 앞서 서울대 논문을 보면 대용량 분류를 위해 62만개의 문장을 학습했다고 하며, 결과가 더욱 정확하고 정교해지려면 학습 데이터는 당연히 많을수록 좋다.
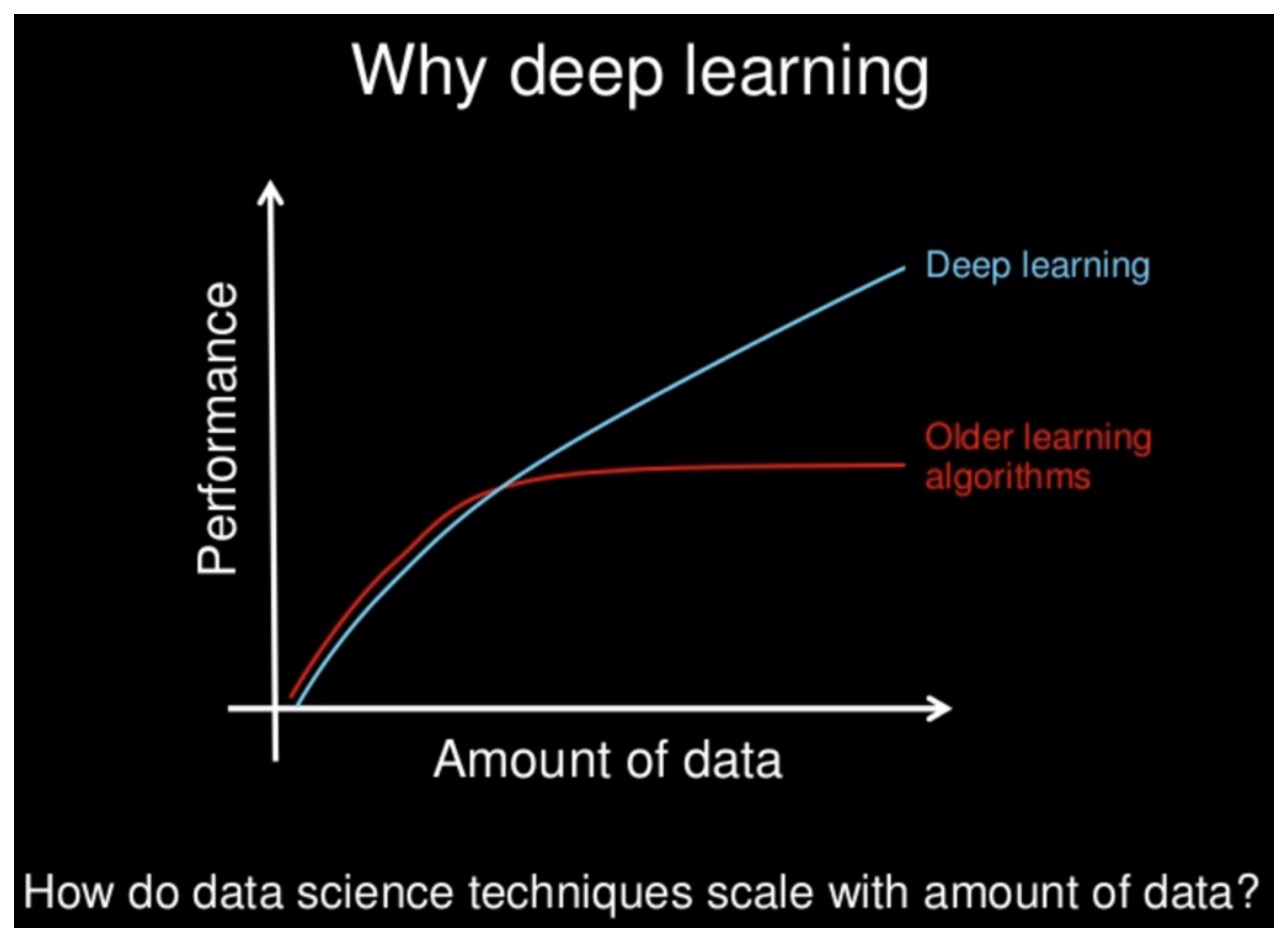 딥러닝에서 학습 데이터는 많을수록 좋다고 설명하는 앤드류 응의 슬라이드
딥러닝에서 학습 데이터는 많을수록 좋다고 설명하는 앤드류 응의 슬라이드
또한 원문의 알고리즘은 단어 사전에 없을 경우 동일한 벡터값으로 표현되기 때문에 정확도가 떨어진다. 따라서 정확도를 높이기 위해서는 모든 문장의 단어를 커버할 수 있을 정도로 충분히 학습하는게 좋다.
문장 데이터는 어휘로 구분하여 색인하고 0에서 전체 어휘 사이즈 만큼 맵핑한다. 각 문장은 정수 벡터가 된다.
모델
구현하려는 신경망을 구성하면 아래와 같다.3
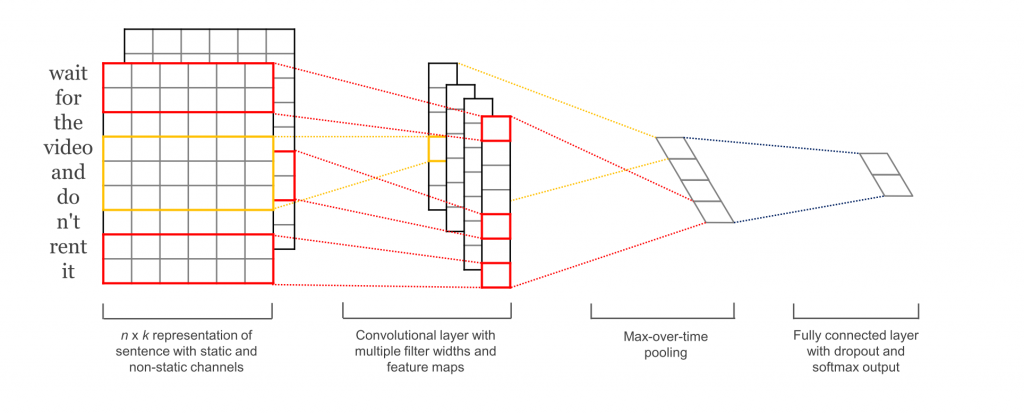
첫 번째 레이어는 단어를 저차원 벡터로 임베드한다. 그 다음 레이어는 여러 사이즈의 필터를 이용해, 임베드된 단어 벡터에 대해 합성곱 변환을 수행한다. 그 다음 합성곱 레이어의 결과를 긴 피쳐 벡터로 맥스 풀링하고, 드롭아웃 정규화를 추가하고, 소프트맥스 레이어의 결과로 분류를 수행한다.
이 글에서 참고한 김윤님의 논문에는 word2vec 벡터를 사용했으나 여기서는 학습 목적으로 모델을 보다 단순화 하기로 한다. 참고로 서울대 논문에 따르면 word2vec은 성능 향상에 큰 도움이 되지 않았다고 한다.4
구현
최근까지의 여러 논문을 살펴 보면 개념과 원리는 상세하게 소개하지만 어떻게 구현했는지는 언급하지 않는다. 사용한 프레임워크는 물론 코드도 제공하지 않기 때문에 동일한 환경을 구성하여 실험하기에는 어려움이 많다. 그런데 원문에서는 텐서플로우를 이용해 논문의 모델을 실제로 구현하는 방법을 소개하여 매우 유용하다. 실제 원문의 내용 대부분은 구현을 비롯한 코드 소개에 할애하고 있고 본 문서에서도 구현에 대해 보다 상세히 정리하여 소개하도록 한다. 본 문서는 원문의 많은 부분을 인용하였으므로 별도 인용 문구를 표시하진 않으나 대부분의 내용은 거의 유사함을 다시 한 번 일러둔다.
Embedding Layer
첫 번째 레이어는 단어 색인을 저차원 벡터 표현으로 맵핑하는 임베디드 레이어로, 필수적인 룩업 테이블이다. 앞서 김윤님의 논문3에는 word2vec을 사용했으나 여기서는 단순 룩업 테이블을 사용한다.
Convolution and Max-Pooling Layers
이 부분이 가장 중요한 맥스 풀링, 합성곱 레이어를 만드는 부분이다. 각각 크기가 다른 필터를 사용하여 반복적으로 합성곱 텐서를 생성하고 이를 하나의 큰 피쳐 벡터로 병합한다.
pooled_outputs = []
for i, filter_size in enumerate(filter_sizes):
with tf.name_scope("conv-maxpool-%s" % filter_size):
# Convolution Layer
filter_shape = [filter_size, embedding_size, 1, num_filters]
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[num_filters]), name="b")
conv = tf.nn.conv2d(
self.embedded_chars_expanded,
W,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")
# Apply nonlinearity
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
# Max-pooling over the outputs
pooled = tf.nn.max_pool(
h,
ksize=[1, sequence_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool")
pooled_outputs.append(pooled)
# Combine all the pooled features
num_filters_total = num_filters * len(filter_sizes)
self.h_pool = tf.concat(3, pooled_outputs)
self.h_pool_flat = tf.reshape(self.h_pool, [-1, num_filters_total])
여기서, W는 필터 행렬이고, h는 합성곱 출력에 비선형성(ReLU)을 적용한 결과다. 각 필터는 전체 임베딩을 슬라이드 한다. VALID 패딩은 엣지 패딩 없이 문장을 슬라이드 하여 [1, sequence_length - filter_size + 1, 1, 1] 크기로 좁은narrow 합성곱을 수행함을 의미한다. 각 필터 사이즈의 맥스 풀링 출력은 [batch_size, 1, 1, num_filters]가 되며 이것이 최종 피쳐에 대응하는 마지막 피쳐 벡터다. 모든 풀링 벡터는 [batch_size, num_filters_total] 모양을 갖는 하나의 긴 피쳐 벡터로 결합된다. tf.reshape에 -1을 사용하여 텐서플로우가 차원을 평평하게 만들도록 한다.
설명이 다소 어렵지만 가능하면 출력 형태shape를 시각화하고 이해하면 도움이 된다. 이미지 CNN에 대한 시각화 자료는 대체로 많은 편이고 특히 Andrej Karpathy가 순수 JS로 구현한 CIFAR-10 시각화 데모는 각각의 출력을 이해하는데 큰 도움이 된다.
Dropout Layer
드롭아웃은 합성곱 신경망의 오버피팅을 방지하는 가장 유명하면서도 흥미로운 방법이다. 드롭아웃 레이어는 뉴런의 일부를 확률적으로 ‘비활성화’한다. 이는 뉴런의 상호 적응을 방지하고 피쳐를 개별적으로 학습하도록 강제하여 사람이 그림을 맞출때 일부를 손으로 가린채 특징을 학습하여 맞추도록 하는 방식과 유사하게 동작한다. 여기서는 드롭아웃을 학습 중에는 0.5, 평가 중에는 당연히 1로 비활성화 한다.
Scores and Predictions
맥스 풀링(드롭아웃이 적용된 상태에서)으로 피쳐 벡터를 사용하여 행렬 곱셈을 수행하고 가장 높은 점수로 분류를 선택하는 예측을 수행한다. 원 점수를 정규화 확률로 변환하는 소프트맥스를 적용하지만 최종 예측 결과는 변하지 않는다.
with tf.name_scope("output"):
W = tf.Variable(tf.truncated_normal([num_filters_total, num_classes], stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[num_classes]), name="b")
self.scores = tf.nn.xw_plus_b(self.h_drop, W, b, name="scores")
self.predictions = tf.argmax(self.scores, 1, name="predictions")
Loss and Accuracy
점수를 이용해 손실 함수를 정의한다. 손실은 망에서 발생하는 오류를 나타내는 척도이며 이를 최소화 하는게 우리의 목표다. 분류 문제에 대한 표준 손실 함수는 cross-entropy loss를 사용한다.
# Calculate mean cross-entropy loss
with tf.name_scope("loss"):
losses = tf.nn.softmax_cross_entropy_with_logits(self.scores, self.input_y)
self.loss = tf.reduce_mean(losses)
Visualizing the Network
딥러닝은 레이어가 매우 복잡해질 수 있기 때문에 시각화가 중요하다. 텐서플로우에는 텐서보드라는 훌륭한 시각화 도구가 포함되어 있고 이를 이용해 시각화 할 수 있다. 자주 활용하여 각각의 레이어 입출력을 명확히 이해하는게 중요하다.
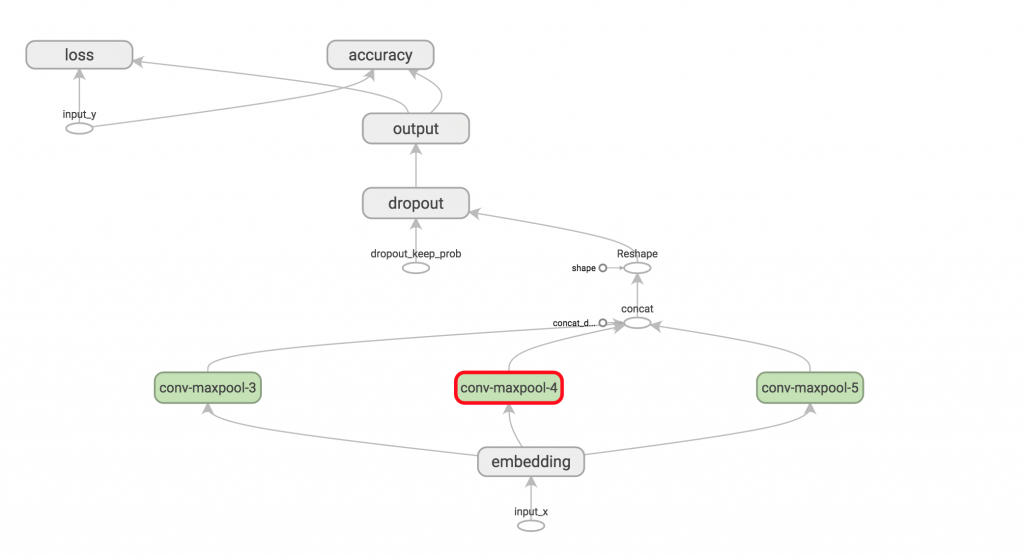
Instantiating the CNN and Minimizing the Loss
TextCNN 모델을 인스턴스화한 다음 망의 손실 함수를 최적화하는 방법을 정의한다. 텐서플로우에는 여러가지 옵티마이저가 내장되어 있는데 여기서는 아담 옵티마이저를 사용한다.
global_step = tf.Variable(0, name="global_step", trainable=False)
optimizer = tf.train.AdamOptimizer(1e-4)
grads_and_vars = optimizer.compute_gradients(cnn.loss)
train_op = optimizer.apply_gradients(grads_and_vars, global_step=global_step)
Summaries
텐서플로우에는 다양한 학습 및 평가 과정을 추적하고 시각화 하는 써머리Summaries 개념이 있다. 예를 들어 시간 경과에 따른 손실 및 정확도의 변화를 추적하고 싶을때 레이어 활성화 히스토그램 같은 더 복잡한 부분도 추적할 수 있다. 써머리는 시리얼라이즈드 오브젝트이며 써머리라이터SummaryWriter를 사용해 디스크에 기록한다.
# Output directory for models and summaries
timestamp = str(int(time.time()))
out_dir = os.path.abspath(os.path.join(os.path.curdir, "runs", timestamp))
print("Writing to {}\n".format(out_dir))
# Summaries for loss and accuracy
loss_summary = tf.scalar_summary("loss", cnn.loss)
acc_summary = tf.scalar_summary("accuracy", cnn.accuracy)
# Train Summaries
train_summary_op = tf.merge_summary([loss_summary, acc_summary])
train_summary_dir = os.path.join(out_dir, "summaries", "train")
train_summary_writer = tf.train.SummaryWriter(train_summary_dir, sess.graph_def)
# Dev summaries
dev_summary_op = tf.merge_summary([loss_summary, acc_summary])
dev_summary_dir = os.path.join(out_dir, "summaries", "dev")
dev_summary_writer = tf.train.SummaryWriter(dev_summary_dir, sess.graph_def)
Initializing the Variables
모델을 학습하기 전에 그래프에서 변수를 초기화 해야 한다. initialize_all_variables 함수를 사용했으며 정의한 변수를 모두 초기화 하는 편리한 함수다. 현재는 deprecated 된 상태이므로 이에 대한 간단한 패치를 제출해서 머지됐다. 물론 변수의 초기화 프로그램을 수동으로 호출 할 수도 있는데, 이는 미리 훈련 된 값으로 임베딩을 초기화하려는 경우에 유용하다.
Defining a Single Training Step
이제 데이터 배치 모델을 평가하고 모델 파라미터를 업데이트하는 학습 단계를 정의한다.
def train_step(x_batch, y_batch):
"""
A single training step
"""
feed_dict = {
cnn.input_x: x_batch,
cnn.input_y: y_batch,
cnn.dropout_keep_prob: FLAGS.dropout_keep_prob
}
_, step, summaries, loss, accuracy = sess.run(
[train_op, global_step, train_summary_op, cnn.loss, cnn.accuracy],
feed_dict)
time_str = datetime.datetime.now().isoformat()
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy))
train_summary_writer.add_summary(summaries, step)
평가 단계도 학습 단계와 유사하게 정의할 수 있다. 학습의 유효성을 검증하기 위해 평가 셋트의 손실 및 정확도 평가를 위한 유사한 기능을 작성하며, 차이점은 별도 학습 과정이 필요 없으며 드롭아웃을 비활성화 한다는 점 뿐이다.
Training Loop
마지막으로 트레이닝 루프를 작성한다. 데이터 배치를 반복하고 주기적으로 모델을 평가하고 체크포인팅 한다. 기본 값은 100회당 한 차례 모델을 평가하도록 설정되어 있으며, 파라미터로 조정할 수 있다.
Visualizing Results in Tensorboard
앞서 출력 디렉토리에 써머리를 저장하였는데, 텐서보드에 이 위치를 지정하여 그래프와 요약 정보를 시각화 할 수 있다. 앞서 여러차례 언급했듯 시각화는 매우 중요하다.
tensorboard --logdir /PATH_TO_CODE/runs/1449760558/summaries/
예제를 통한 학습 결과의 시각화는 아래와 같다. 한국어 학습 데이터는 규모가 작으므로 여기서는 참고를 위해 원문의 학습 그래프를 소개하도록 한다.
기본 파라미터(128 차원 임베딩, 3,4,5 필터 사이즈, 드롭아웃 0.5, 필터 사이즈별 128개 필터)의 학습 결과(파란선이 학습 데이터, 빨간선은 평가 데이터)이며 아래와 같다.
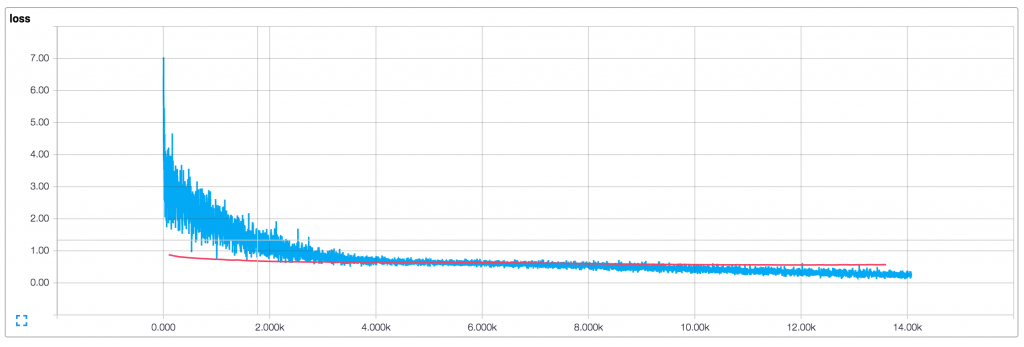
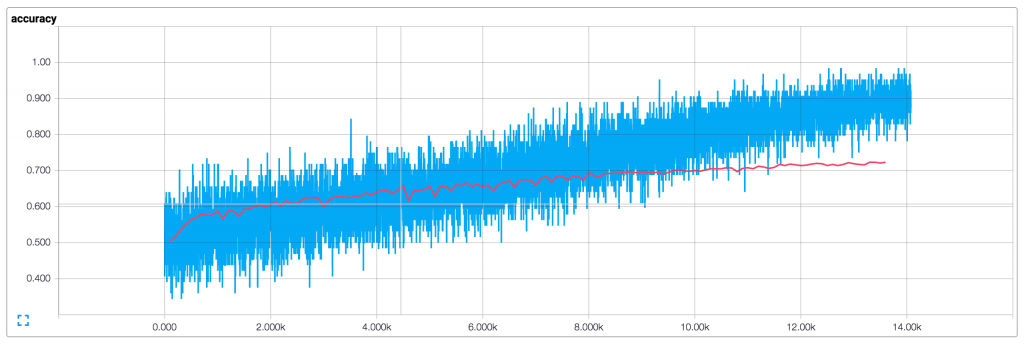
- 배치 사이즈가 작기 때문에 학습 결과가 부드럽지 않다. 더 큰 배치를 사용하거나 전체 학습 결과로 평가한다면 좀 더 부드러운 파란색 선을 얻을 수 있을 것이다.
- 평가 정확도가 학습 정확도보다 상당히 낮기 때문에 우리 망이 학습 데이터를 오버피팅 하는 것 처럼 보인다. 따라서 더 많은 데이터, 더 강력한 정규화 또는 더 적은 모델 파라미터가 필요하다. 예를 들어 마지막 레이어에 L2 패널티 가중치를 추가하여 실험했을때는 논문과 유사하게 76% 까지 정확도를 높일 수 있었다.
- 드롭아웃으로 인해 학습 데이터는 평가셋에 비해 훨씬 낮은 손실, 정확도로 시작된다.
Extensions and Exercises
이외에도 모델 성능을 개선할 수 있는 몇 가지 팁을 아래와 같이 정리할 수 있다.
- 사전 훈련된 word2vec 벡터를 사용하여 임베딩을 초기화한다.
- 오버피팅 방지를 위해 신경망에 L2 정규화를 추가하고 드롭아웃 비율을 실험한다. 참고로 코드에는 L2 정규화 옵션이 이미 포함되어 있으며 기본으로 비활성화 한 상태다.
- 가중치 업데이트 및 레이어 액션에 대한 히스토그램 써머리를 추가하고 텐서보드에서 시각화한다.
코드
전체 코드는 아래에서 확인할 수 있다.