
C++, Java 해시 테이블 구현
2022년 2월 25일 그림 수정
2018년 5월 12일 충돌 해결 추가
2018년 1월 30일 초안 작성
해시 테이블
해시 테이블은 해시 함수를 이용해 인덱스를 버킷 또는 슬롯의 배열로 계산하는 자료 구조로 둘 이상의 키에 동일한 인덱스 충돌collision이 발생할 경우 해결 방법에 따라 크게 두 가지 형태로 나뉜다.
Separate chaining(with linked lists)
Separate chaning은 충돌 발생시 링크드 리스트로 연결chaining하는 방식으로 간단한 알고리즘과 기본 자료 구조만 있으면 되고 간단한 해시 함수를 사용하므로 인기가 높다. 가장 널리 쓰이는 방식이며, 아래에서 살펴볼 대부분의 프로그래밍 언어에서도 이 방식으로 구현이 되어 있다.

Open addressing
Open addressing은 충돌 발생시 탐사probing를 통해 빈 공간을 찾아나서는 방식이며 탐사에는 일반적으로 Linear probing, Quadratic probing, Double hashing이 사용된다.

이 중 가장 단순한 Linear probing의 경우 충돌이 발생할때 마다 한 칸씩(고정폭으로 대개 1을 사용한다) 아래로 빈 공간을 찾아 탐색에 나선다. 그림 처럼 빈 공간이 많다면 금방 자리를 잡게 되지만 그렇지 않을 경우 아래로 계속 탐사를 진행하므로 효율성이 많이 떨어진다.

초기에는 성능이 좋지만 데이터가 슬롯의 80% 이상 차게 되면 급격히 성능이 떨어지며, 체이닝과 달리 전체 슬롯의 갯수 이상은 저장할 수 없다.
해시 함수
해시 테이블의 성능은 얼마나 인덱스 충돌을 최소화 하느냐에 달려있다. 최악의 경우 O(n)에 수행되며, 따라서 해시 함수를 잘 설계하여 충돌을 최소화 하는 것이 무엇보다 중요하다. Java의 경우 소수인 31의 곱셈합으로 구현되어 있다.
hashCode = 31*hashCode + (e==null ? 0 : e.hashCode());
조슈아 블록은 여러 해시 함수의 성능을 조사했고 K&R 책에서 P(31)을 찾아냈으며(RISC 머신에서 가장 저렴한 계산 비용이 들었다고 한다) 비슷한 성능을 지닌 P(33)과 고민끝에 소수인 31을 택했다고 한다. 성능과 충돌의 적절한 합의점이며, 실제로 31은 메르센 소수로 수학적으로 나쁘지 않은 선택이기도 하다.
최근 구글 브레인은 해시 함수를 딥러닝 모델로 적용해 충돌을 최소화하는 논문을 내놓아 해시 테이블 자료 구조의 미래를 기대하게 했다.
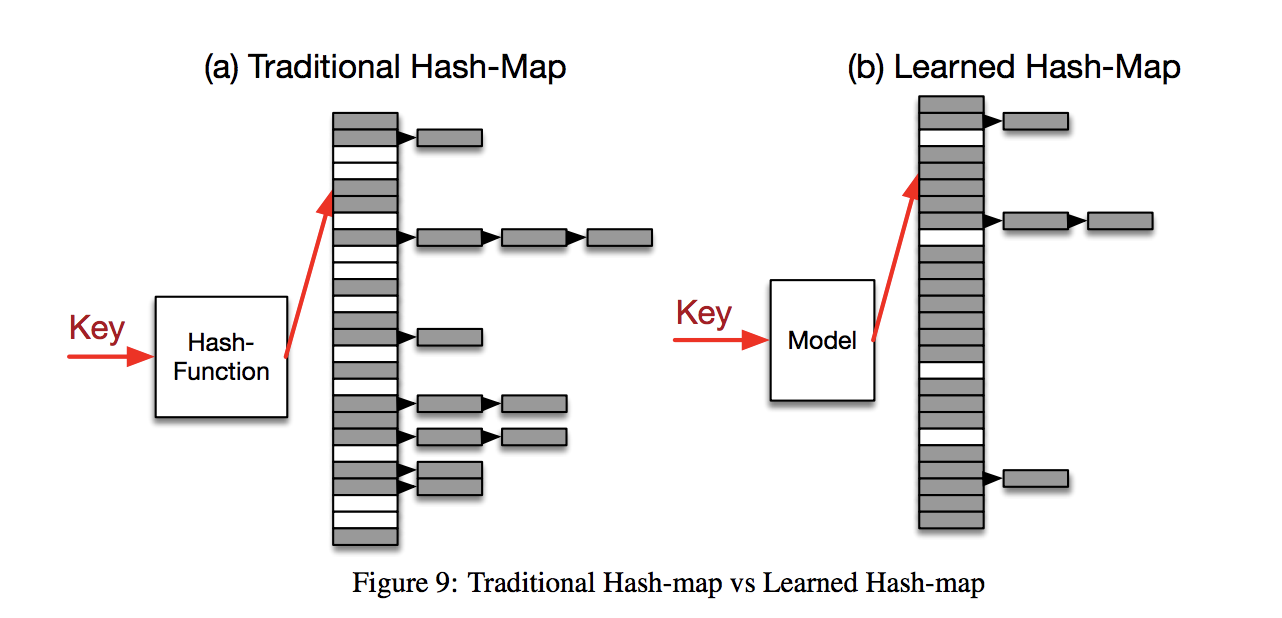
언어별 구현
그렇다면 각 프로그래밍 언어에서는 해시 테이블을 어떻게 구현하고 있는지 살펴보자.
C++
C++은 STL 컨테이너로 std::map을 제공한다. 그러나 특이하게도 트리 형태로, 좀 더 정확히는 red-black tree를 사용하는 self balancing tree 알고리즘을 사용한다. 이 말은 해시 테이블을 사용하지 않고 내부적으로 정렬된 상태로 삽입된다는 얘긴데, 이는 역사적인 이유 때문이기도 하다. 뒤에서 살펴보겠지만 Java 또한 역사적인 이유로 컬렉션 명이 변경된 전례가 있다.
C++11에 뒤늦게 해시 테이블 구현이 추가되었다. hash_map이라는 이름이 이미 다양한 라이브러리에서 사용 중이라 std::unordered_map이라는 이름으로 추가되었다. 하지만 default 처럼 보이지 않는 긴 명칭을 갖고 있다 보니 C++에서는 여전히 해시 테이블 기반이 아닌 트리 기반의 std::map이 주로 쓰이는 특이한 상황에 놓여 있다.
thread-safe 하지 않으며, C++ STL 컨테이너는 별도의 thread-safe 한 자료 구조를 제공하지 않는다. mutex를 통한 reader/writer lock을 직접 구현해 사용해야 한다.
Java
Java는 HashMap에서 해시 테이블을 구현하고 있다. (Java 7 이하 기준이며 8 이상에서는 트리와 함께 사용하는 하이브리드 방식을 택하고 있다.) 그러나 초기에 이미 HashTable이 존재했었고, C++ STL 컨테이너와 명칭과 용도가 동일한 Vector 또한 존재했다. 멀티 코어가 흔하지 않던 시절에 자바 플랫폼 초기에는 과도한 synchronized를 적용하는 경향이 있었는데(Effective Java, 2008) 이로 인해 이후에 HashTable은 HashMap으로, Vector는 ArrayList로 대체되었다. 하위 호환성을 중요시 여기는 언어의 부득이한 결정 사항이기도 하며, 같은 이유로 StringBuffer 또한 StringBuilder로 대체되기도 했다.
thread-safe가 필요한 경우에는 구식이 된 HashTable이 아닌, 필요한 부분에만 synchronized를 적용해 성능을 최적화 한 ConcurrentHashMap을 사용해야 한다.
Go
Go는 C++, Java와 마찬가지로 해시 테이블을 구현한 map을 built-in으로 지원하며 이유는 FAQ에 잘 명시되어 있다.
Why are maps built in?
The same reason strings are: they are such a powerful and important data structure that providing one excellent implementation with syntactic support makes programming more pleasant. We believe that Go’s implementation of maps is strong enough that it will serve for the vast majority of uses.
map은 string 만큼이나 중요한 자료 구조이고 따라서 직접 견고한 형태로 만든 단일 구현이 훨씬 더 잇점이 높다고 판단했다. 다른 언어와 마찬가지로 성능을 위해 thread-safe 하지 않도록 구현하였는데, 이는 쉽지 않은 결정이었다고 한다. 초기에 자바가 모두 synchronized로 구현했다가 다시 자료형을 새로 만든 점도 영향을 끼쳤을듯 하다. 따라서 thread-safe가 필요한 경우 C++ 처럼 mutex를 통해 lock을 걸어 직접 처리해야 한다.
Python
파이썬의 내부 자료 구조인 dict는 해시 테이블로 구현되어 있다. 다른 언어와는 달리 파이썬은 모든 자료 구조가 thread-safe 하고 대부분의 명령이 atomic 하다. 이는 CPython GIL의 영향인데 덕분에 파이썬은 번거로운 동시성 관리에서 해방되었지만, 반면에 한 쓰레드만 실행이 되는 기이한 구조가 되었다.
)
파이썬에서 성능을 최적화 하기 위해서는 GIL로 인해 멀티 쓰레드가 아닌 멀티 프로세스의 관점으로 접근해야 한다.
C
C에는 기본으로 제공하는 해시 테이블 자료 구조가 없다. 이는 현대 프로그래밍에서 특별한 이유가 없는 한 더 이상 C로 신규 개발을 해서는 안되는 중요한 이유 중 하나이기도 하다. C의 표준 위원회는 C의 기본 정신spirit과 전통을 유지하는 방향으로 결정을 내리고 있으며, 본질적으로 C 언어가 밑바탕이 되는 철학을 유지하고 있다.
그러나 써드 파티 해시 테이블 구현은 다양하게 존재하며, C에서는 이처럼 해시 테이블을 사용하기 위해 별도 구현을 참고하여 직접 구현해 사용해야 한다.
결론
해시 테이블은 하루가 다르게 빠르게 발전하는 컴퓨터 과학 분야에서 벌써 70년에 가까운 역사를 자랑하면서도 여전히 사랑 받고 있는 매우 유용한 자료 구조다. C를 제외한 모든 언어에서 map(C++은 트리 기반이며, 해시 테이블은 unordered_map)의 근간이 되며, 중요한 위치를 차지하고 있다. 앞으로 딥러닝 모델로 해시 함수의 성능 향상이 기대되는바, 해시 테이블의 미래가 더욱 기대된다.