
검색은 어떻게 동작하나요
2017년 6월 17일 초안 작성
본론
안녕, 제 이름은 존 입니다.
저는 구글에서 검색과 머신러닝 팀을 이끌고 있어요.
전 세계의 사람들이 일상적인 질문과 중요한 질문까지도 검색을 하는 것은 매우 놀라운 일이라고 생각해요. 그래서 우리는 최선의 답변을 제공하기 위해 어깨가 무겁습니다.
안녕, 제 이름은 악샤야 이고 빙 검색 팀에 근무하고 있어요.
인공 지능과 머신 러닝에 대해 많이들 얘기합니다. 하지만 우리는 사회에 영향을 끼치는, 사용자들이 어떻게 검색하는지에 대해 고민해요.
간단한 질문을 해보죠.
“화성까지 가는데 얼마나 걸리나요?”
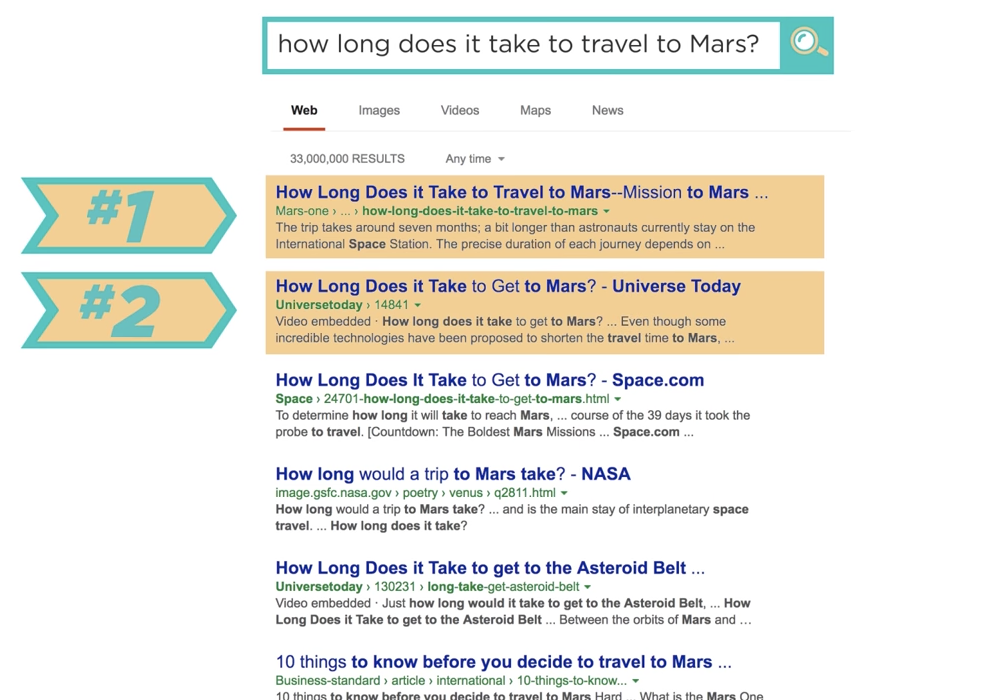
이 결과들은 어디에서 왔고, 왜 다른 것 보다 상위에 있을까요?
좋아요, 검색 엔진이 어떻게 여러분의 요청을 결과로 만들어내는지 살펴봅시다.
우선 검색 엔진은 사실 검색할때마다 실시간으로 월드 와이드 웹에서 가져오는게 아니에요. 왜냐면, 인터넷에는 수십억개의 사이트가 있고 매 분 마다 수백개가 생겨나기 때문이죠. 그래서 여러분이 원하는걸 모든 사이트에서 샅샅이 뒤져야 한다면, 영원히 걸릴거에요.
그래서 검색을 빠르게 하기 위해 검색 엔진은 지속적으로 웹을 스캔하여 나중에 검색에 도움이 될 수 있도록 정보를 기록합니다. 즉, “화성 여행”을 검색할 때 이미 검색 엔진은 실시간 답변에 필요한 정보를 갖고 있는 거죠.
작동 방식은 다음과 같아요.

인터넷은 하이퍼링크로 서로 연결된 페이지의 웹(거미줄)이에요. 검색 엔진은 이 웹 페이지에서 정보를 수집하는 “스파이더(거미)”라고 불리우는 프로그램을 꾸준히 실행하죠. 하이퍼링크를 찾으면 연결된 모든 페이지를 방문할때까지 따라갑니다.
스파이더가 페이지를 방문할때 마다 ‘색인’이라 불리우는 특수한 데이타베이스에 정보를 추가합니다. 나중에 검색에 필요하죠.
자, 이제 검색 엔진이 어떻게 결과를 가져오는지 알아보기 위해 이전으로 되돌아가 보죠.
“화성까지 가는데 얼마나 걸리나요?”라고 질문하면 검색 엔진은 각 단어가 포함된 결과를 색인에서 즉시 뽑아서 페이지 목록을 구성합니다. 하지만 이렇게 검색어가 포함된 결과는 수백만 페이지에 달하므로 검색 엔진은 최적의 결과를 결정해야 해요.

이건 매우 까다로운 부분이에요.
왜냐면, 검색 엔진은 여러분이 무엇을 찾고 있는지 추측해야 하거든요.
각 검색 엔진 마다 여러분이 원하는걸 생각해 페이지의 랭킹을 정하는 자체 알고리즘이 있어요. 검색어가 제목에 있는지, 모든 단어가 나란히 표시되는지, 어떤 페이지를 원하고 원하지 않는지 잘 결정하기 위해 여러가지 계산을 할거에요.

구글은 얼마나 많은 웹 페이지가 링크하는지로 가장 적합한 결과를 판별하는 매우 유명한 알고리즘을 발명했어요. 만약, 많은 웹 사이트가 이 웹 페이지가 흥미롭다고 가리킨다면 그게 아마 여러분이 찾고 있는 것일 거라는 아이디어죠.

이 알고리즘은 “페이지 랭크”라고 불러요. 웹 페이지를 랭크해서 때문만이 아니라 구글 창업자 중 한명인 발명가 래리 페이지의 이름을 따서 붙여졌기 때문이죠.

방문자가 많을수록 웹 사이트는 돈을 벌 수 있기 때문에 스패머들은 상위에 노출되기 위한 검색 알고리즘을 찾아내려고 꾸준히 시도해요. 검색 엔진은 가짜나 신뢰할 수 없는 사이트가 상위에 노출되지 않도록 알고리즘을 정기적으로 업데이트 해요. 궁극적으로는 주소를 보고 믿을만 한지 신뢰할 수 있는 출처인지 주의를 기울이는건 여러분에게 달려 있어요.
검색 프로그램은 경쟁사에 비해 더 좋은, 더 빠른 결과를 돌려주기 위해 알고리즘을 개선하고 끊임없이 진화합니다. 오늘날의 검색 엔진은 검색 범위를 좁히기 위해 명시적으로 제공하지 않은 정보도 사용해요. 한 예로 만약 “강아지 공원”을 검색 했다면, 많은 검색 엔진들은 위치 정보를 입력하지 않더라도 근처의 공원을 표시해줄거에요.
요즘 검색 엔진들은 페이지의 단어들 뿐만 아니라 최적의 결과를 찾기 위해 실제로 의미하는 바가 무엇인지에 대해서도 이해합니다. 예를 들어 “빠른 피처”라고 검색 한다면 여러분이 운동 선수를 찾는다는걸 알겠지만 “라지 피처”를 검색 한다면 부엌을 위한 옵션을 찾아낼거에요.

단어를 더 잘 이해하기 위해, 우리는 인공 지능의 일종인 머신 러닝이란걸 사용합니다. 검색 알고리즘이 개별 문자나 단어를 찾기만 하는게 아니라 단어의 의미를 이해할 수 있도록 하죠.
인터넷은 기하급수적으로 증가하고 있지만, 검색 엔진을 만드는 팀이 일을 제대로 해낸다면 여러분이 원하는 정보는 불과 몇 번의 입력만으로도 찾아낼 수 있게 될 거에요.
결론
영어를 번역할때 특유의 번역체는 오히려 한글로 읽었을때 더욱 이해하기 힘들게 하는 경우가 많은데요. 그래서 한글 문장을 자연스럽게 구성하기 위해 많은 노력을 기울였고, 중간 중간에 동영상의 스크린샷을 삽입하여 이해를 도왔습니다. 아울러 유튜브에 있는 영상에는 한글 자막을 작성하여 컨트리뷰션 했습니다.
이 글이 검색 엔진을 이해하는데 많은 분들에게 도움이 되길 바랍니다.