
해석 가능한 머신러닝
2019년 9월 8일 초안 작성
본론
해석 가능성Interpretable은 매우 중요하다. 통계학에서도 이를 위한 기술 통계학Descriptive Statistics은 매우 주목받는 분야이기도 하다. 작년부터 문서를 준비해왔으나 계속 정리하지 못하다 뒤늦게 정리하여 출판한다.
Decision Tree
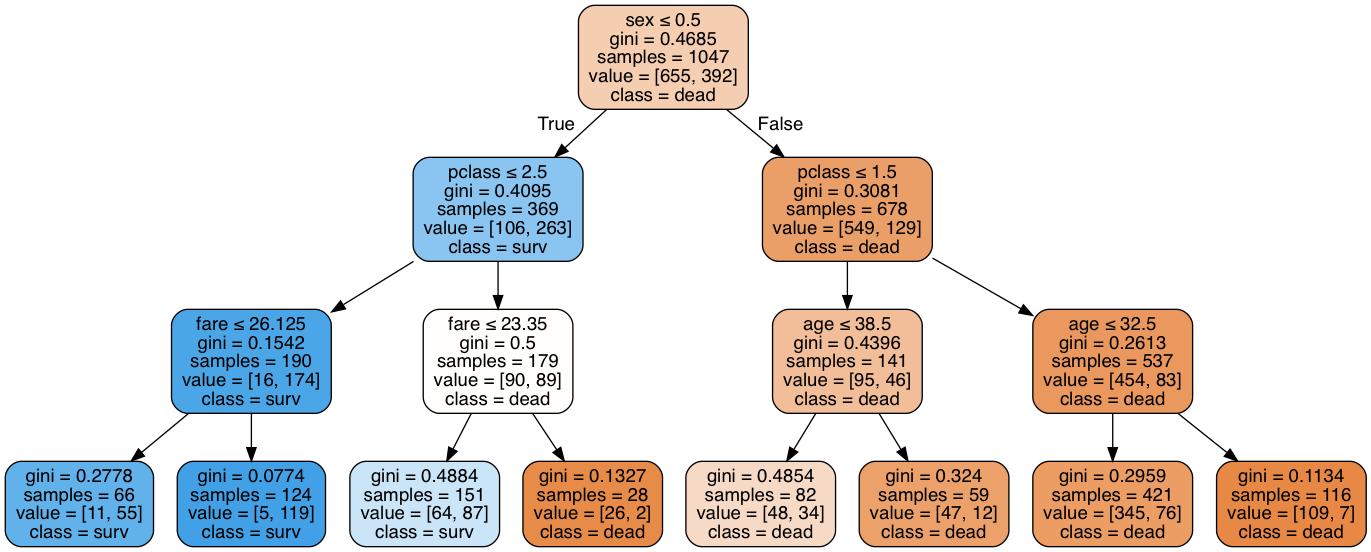
scikit-learn은 기본적인 시각화를 지원한다. 아래는 타이타닉 데이타 분석 결과로 왼쪽이 scikit-learn의 기본 시각화, 오른쪽은 dtreeviz로 해석한 결과이다.

How to visualize decision trees를 소개하는 발표 영상(YouTube)
타이타닉의 경우 Decision Tree는 80.9%, Random Forests는 81.6% 성능을 보인다. 타이타닉 자체의 데이터 변별력이 부족하므로 큰 의미는 없으나 전처리를 통해 92%까지 높일 수 있다. 아래는 Boston Housing Dataset을 이용한 Regression이며, 마찬가지로 해석하기 쉽게 잘 보여준다.

dtreeviz 설치
여전히 svg를 보여주기 위한 설치 문제가 있다.1
$ conda create --name dtreeviz python=3.7
$ conda activate dtreeviz
$ pip install dtreeviz
$ brew uninstall graphviz
$ brew reinstall pango librsvg --build-from-source
$ brew reinstall cairo --build-from-source
$ brew install graphviz --build-from-source
It may takes up to 10 mins. conda 환경 또한 완전히 새롭게 만들어주지 않으면 기존 환경에서는 자꾸만 segmentation fault가 발생했다.
Random Forest
Decision Tree와 달리 배깅을 통한 Random Forest는 각각의 피처를 통한 시각화가 쉽지 않다. 부스팅도 마찬가지이며, 이 경우 feature importance로 해석을 시도한다. scikit-learn의 경우 feature importance 표현에 bias를 가지므로 주의가 필요하다. rfpimp 프로젝트는 신뢰성 높은 결과를 보여주며, 최근(Jul 2019) scikit-learn은 permutation importance 구현을 머지했다.


Decision Tree의 feature importance(왼쪽)는 sex > pclass > fare 순을 보인다. 그러나, Random Forest의 Feature importance via average gini/variance drop(sklearn) 방식(오른쪽)은 fare > sex > age 순으로 전혀 다른 결과를 보인다.


rfpimp 패키지의 permutation importance(왼쪽)는 Decision Tree와 거의 유사한 결과를 보이며, Eli5 결과(오른쪽) 또한 Decision Tree와 거의 유사하다.

shap.summary_plot(explainer.shap_values(X_test), X_test)
SHAP의 결과도 유사하다.2

학습 데이터의 상관 관계 히트맵(plot_corr_heatmap())만 별도로 추출할 수 있다. 여기서 pclass와 fare는 상관 관계가 매우 높게 나온다. 비용에 따른 객실 등급을 생각해본다면 납득이 되는 결과다.
Interpretable ML
책
아래 두 권을 추천한다. 원고를 공개하여 진행 중이다.
- The Mechanics of Machine Learning
dtreeviz의 Terence Parr와 fast.ai의 Jeremy Howard가 함께 쓰고 있는 책 - Interpretable Machine Learning
Making Black Box Models Explainable을 주제로 Christoph Molnar가 쓰고 있는 책. 이 글의 제목 또한 이 책과 동일하다.
변성윤님의 블로그에 좋은 링크가 많다.
LIME, SHAP, ELI5
LIME, SHAP, ELI5를 통해 시각화에 보다 집중한 자료를 소개한다.
- Introduction to Model Interpretability PyData NYC 2018
- Explainable AI: ELI5,LIME and SHAP Kaggle Kernel
- SHAP Decision Plots
얼마전 SHAP Decision Plots가 추가되었고, 시각화에 매우 큰 도움이 된다.
LIME
LIME은 UCI News를 Random Forest로 분류하고 시각화 할때 유용하게 활용한 바 있다.

SHAP
특히 SHAP은 이 중 가장 활발한 연구가 진행되고 있으며, 논문 1저자이자 연구를 주도하는 Scott Lundberg는 지금도 꾸준히 개선 하고 있다. KernelExplainer로 모델에 관계 없이 해석할 수 있으며, 트리 앙상블을 고속으로 해석하는 TreeExplainer 또한 별도로 제공한다.
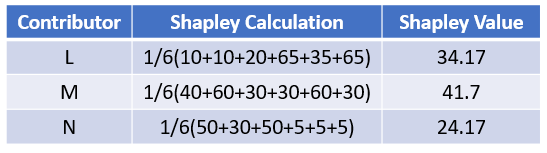
Shapley Value는 게임 이론에서 협력cooperative을 통해 얻어진 이득을 각 플레이어에게 공정하게 분배하는 개념이며, 이 개념을 소개한 수학자 이자 2012년 노벨 경제학상 수상자인 Lloyd Shapley의 이름을 따 명명했다.4
\[\phi_i(N)=\frac1{|N|!}\sum_R\left(v(P^R_i\cup\{i\})-v(P^R_i)\right)\;,\]- N: Number of player(feature)
- \(P_{i}^{R}\): Set of player with order
- \(v(P^R_i)\): Contribution of set of player with order
- \(v(P^R_i\cup\{i\})\): Contribution of set of player with order and player i

타이타닉 탑승객의 생존 확률, 모든 조건이 부정적으로 생존 확률은 0% 이다.

shap.decision_plot(explainer.expected_value[c], shap_values[c], X_test.iloc[i], feature_display_range=slice(-1, -6, -1))
Decision Plot의 feature 순서는 feature_order="importance"를 따른다.
SHAPley Values를 추출한 후 이와 같이 React로 만든 js 라이브러리를 이용해 시각화 한다. 주피터 전용으로 구현되어 있으나 수정을 통해 js 라이브러리를 떼내어 활용할 수 있으며, 2019년 3월에 열린 카카오 사내 해커톤에서 이를 이용해 타이타닉 생존 예측 시각화를 별도 웹 서비스로 구현한 바 있다.

예측 모델은 PyTorch로 Multi-Layer Perceptron을 구현했다. 노트북에 보이는 데모는 타이타닉의 주인공 Jack Dawson(Leonardo Dicaprio)의 사망 확률을 해석한 것으로, 빨간색은 사망에 영향을 준 요인(features)을 시각화 한 그래프이다. 빨간색이 파란색 보다 훨씬 더 길고, 따라서 Jack은 92% 확률로 사망하게 된다.
References
파이썬 데이터 구조를 시각화하는 lolviz도 있다.