
K-Ranker 키워드 선택 알고리즘
2015년 5월 22일 1차 개정
2014년 11월 1일 초안 작성
알고리즘
최적의 운영 키워드 선택을 위해 다수의 데이타 중 가중치에 따라 하나씩 선택(선별)하는 알고리즘이 필요했고 위키피디어에 종류별로 잘 정리되어 있다.

그러나 정렬이 아닌 선택만 필요했고 Median of medians로 K번째 element를 파레토 법칙(Pareto principle)에 따라 20% border 언저리에서 선택하는 방안을 구상했으나 구현의 복잡성으로 인해 20 근처에서 max 값을 부여받는 수식을 만들고 max 값으로 선택하는 방식으로 변경했다.

1차 선별 데이타를 통해 커브 피팅(Curve fitting)을 진행했고 두 개 이상의 파티션으로 나누어 수식의 복잡도를 줄이고 2차 다항식으로 제한했다.
 상기와 같은 그래프 형태로 초기 80점에서 시작, x = 20 일때 max를 부여받으며 그 이후 포물선 형태로 점수를 떨어트린다. 앞서 언급한 바와 같이 무엇보다 수식의 복잡도를 줄이기 위해 2개 파티션으로 구분지었다. 그 결과 아래와 같은 수식을 만들었다.
상기와 같은 그래프 형태로 초기 80점에서 시작, x = 20 일때 max를 부여받으며 그 이후 포물선 형태로 점수를 떨어트린다. 앞서 언급한 바와 같이 무엇보다 수식의 복잡도를 줄이기 위해 2개 파티션으로 구분지었다. 그 결과 아래와 같은 수식을 만들었다.
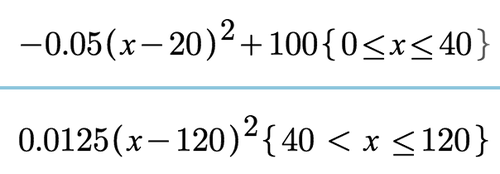
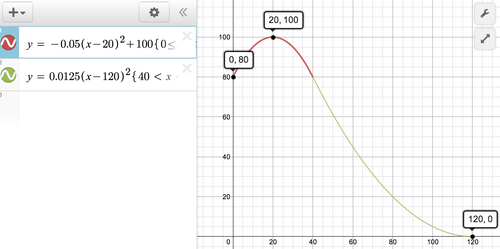
이 수식을 그래프로 그리면 아래와 같다.
도구
그래프를 그리는데는 desmos 서비스가 가장 훌륭했고 특히 미려하고 빠른 UX가 인상적이었다. 커브 피팅 수식을 만들어주진 못하지만 슬라이더로 실시간 그래프를 확인하면서 왠만큼 수식 정립이 가능했다.
맥에서 실행 가능한 어플리케이션 중 Plot2 는 커브 피팅 기능이 사라졌고 MATLAB은 유료다. gnuplot과 R은 당장 script로 접근하기가 번거로웠다. 마우스 클릭만으로 구현되는 desmos가 접근성이 가장 뛰어났다.
커브 피팅 수식을 만드는데는 단연 wolframalpha가 돋보였는데 4차 방정식까지 매우 복잡하게 만들어주지만 실제로 적용하진 않았다. 쿼리는 아래와 같다.
curve fitting { {0,80},{10,90},{15,98},{20,100},{25,98},{30,90},{40,80} }그외 Numbers도 간단한 방정식 기능을 지원하지만 쓸만한 물건은 못됐다. 애플포럼에 유사한 질문이 있었고 유용했으나 오래된 내용들이라 참고만 했다.
구현
실제 구현시에는 여러번의 피드백(IR에서 Relevance feedback을 받아 성능 개선에 활용하듯)을 반영해 그래프를 보다 최적화 했다. 실제로는 포물선을 반대로 하여 다르게 구성했다.
즉, 급격한 상승과 완만한 하강 곡선으로 그렸는데 이유는 실제 운영 키워드 선택시 너무 빨리 선택되지 않고 20분 근처(x = 20)에서 최고점을 받아 선택되고, 이후 천천히 하강하면서 계속 상위에 랭크되어 미처 선택되지 않고 놓치는 키워드가 없도록 하기 위함이다.

따라서 80점 이상에서 선택된다고 가정할 경우 약 18분 경 부터 선택되기 시작하고 20분에 최고점을 찍은 후 90분이 지날때까지도 80점 이상의 고득점으로 남게된다. 최고점 이후 거의 1시간 이상이 지나도 점수가 계속 높기 때문에 신규 키워드에 밀려 선택되지 않고 놓치게 되는 경우는 거의 없을 것이다.
참고
코드는 Java로 구현했다.