
trlX 프레임워크 리뷰
2023년 4월 3일 작성
개요
https://github.com/CarperAI/trlx
- trlX는 hugging face에서 만든 trl(Transformer Reinforcement Learning)의 확장이다.
- trlX는 Carper AI에서 만들고 있으며 Eleuther AI의 spun-off 조직이다.
- trlX는 reward function 또는 reward-labled dataset을 사용해 RL을 통해 LLM을 fine-tuning하는 데 중점을 두도록 설계된 distributed training framework다. 최대 20B까지는 hf의 Accelerate를 지원하며, 20B 이상은 efficient parallelism techniques to scale effectively한 NeMo 학습을 지원한다.
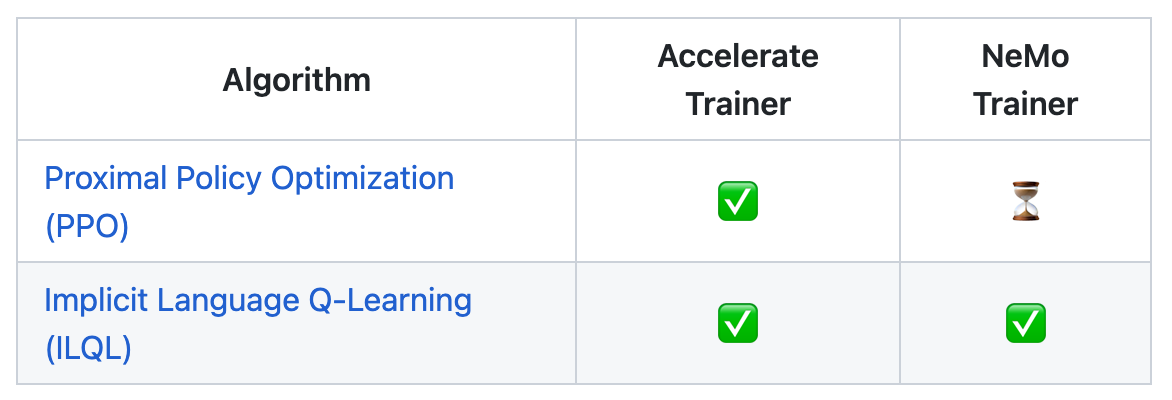
현재 다음 2가지 RL 알고리즘이 구현되어 있으며, 우리가 활용하고자 하는 PPO의 NeMo 지원은 아직 개발 진행 중이다.
아키텍처
구조를 따라가며 직접 그려본 결과, 다음과 같다.
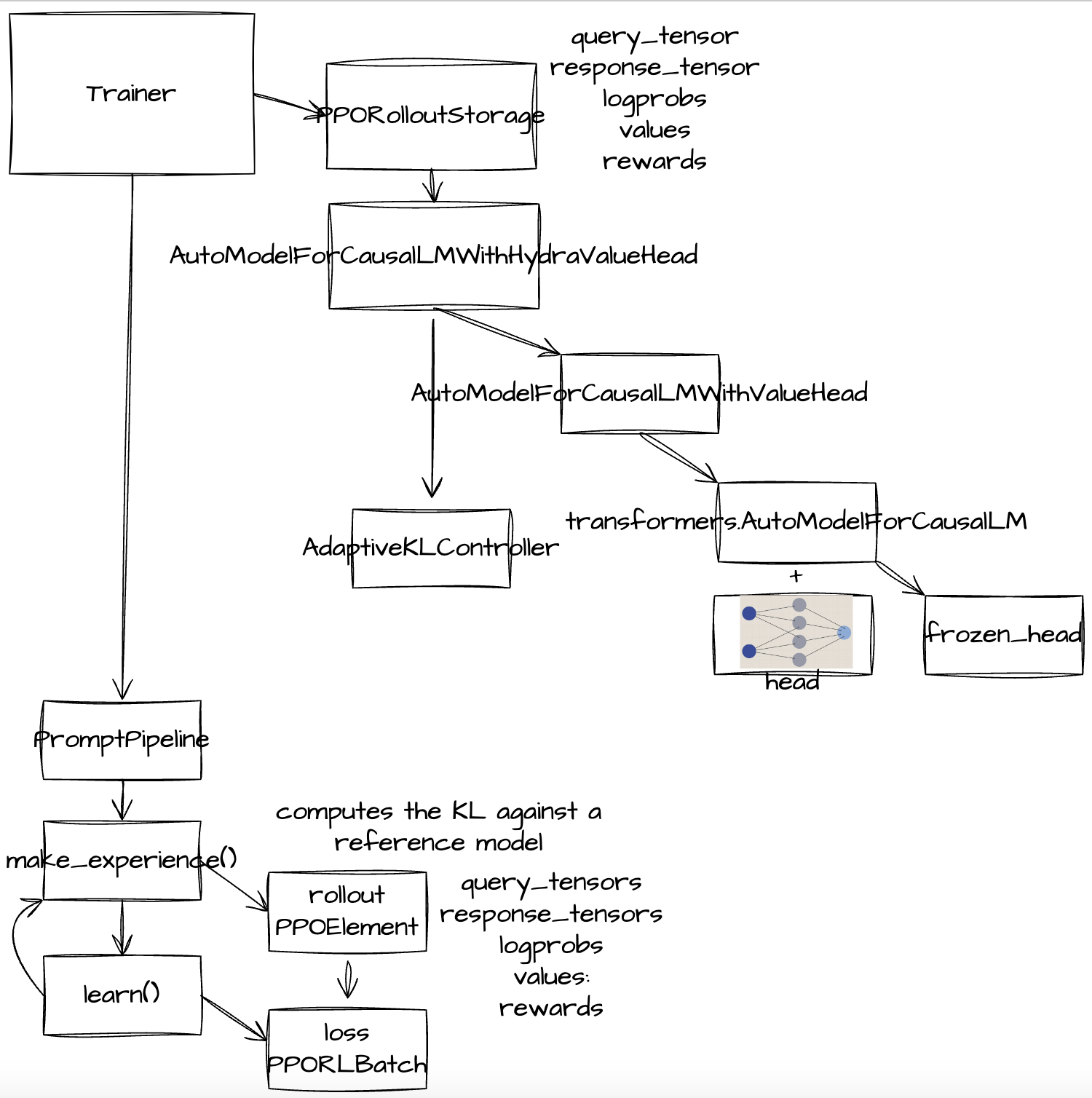
모델
AutoModelForCausalLMWithHydraValueHead(
(base_model): GPT2LMHeadModel(
(transformer): GPT2Model(
(wte): Embedding(50257, 768)
(wpe): Embedding(1024, 768)
(drop): Dropout(p=0.1, inplace=False)
(h): ModuleList(
(0-11): 12 x GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2Attention(
(c_attn): Conv1D()
(c_proj): Conv1D()
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D()
(c_proj): Conv1D()
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=768, out_features=50257, bias=False)
)
(v_head): Sequential(
(0): Linear(in_features=768, out_features=1536, bias=True)
(1): ReLU()
(2): Linear(in_features=1536, out_features=1, bias=True)
)
(frozen_head): GPTModelBranch(
(decoder_blocks): ModuleList(
(0-1): 2 x GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2Attention(
(c_attn): Conv1D()
(c_proj): Conv1D()
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D()
(c_proj): Conv1D()
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(final_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(lm_head): Linear(in_features=768, out_features=50257, bias=False)
)
)
알고리즘
Adaptive KL Controller
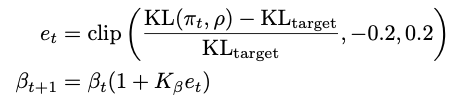 (KL penalty β)
(KL penalty β)
Adaptive KL Controller as described in Ziegler et al. “Fine-Tuning Language Models from Human Preferences” 논문 및 오픈AI 샘플 코드에 구현체가 있음 https://github.com/openai/lm-human-preferences/blob/master/lm_human_preferences/train_policy.py
class AdaptiveKLController:
def __init__(self, init_kl_coef, hparams):
self.value = init_kl_coef
self.hparams = hparams
def update(self, current, n_steps):
target = self.hparams.target
proportional_error = np.clip(current / target - 1, -0.2, 0.2)
mult = 1 + proportional_error * n_steps / self.hparams.horizon
self.value *= mult
trlX에도 완전히 동일하게 구현되어 있다.
rewards
logprobs = logprobs_of_labels(logits[:, :-1, :], all_tokens[:, 1:])
ref_logprobs = logprobs_of_labels(ref_logits[:, :-1, :], all_tokens[:, 1:])
log_ratio = (logprobs - ref_logprobs) * attention_mask[:, :-1] # 어텐션 마스크가 1인 토큰(패딩이 아닌)에 대해서 계산
rewards = kl_ctl.value * -log_ratio
all_scores = torch.tensor(
reward_fn(
samples=all_str_samples,
prompts=all_str_prompts,
outputs=all_str_outputs,
),
dtype=torch.float,
device=device,
)
scores = torch.tensor(all_scores[0])
rewards = kl_penalty[sample_idx]
# 맨 마지막에 score를 합산
rewards[-1] += scores[sample_idx]
get_advantages_and_returns
Function that computes advantages and returns from rewards and values. Calculated as in the original PPO paper: https://arxiv.org/abs/1707.06347 Note that rewards may include a KL divergence loss term.
Advantages looks like this:
Adv1 = R1 + γ * λ * R2 + γ^2 * λ^2 * R3 + ...
- V1 + γ * (1 - λ) V2 + γ^2 * λ * (1 - λ) V3 + ...
Returns looks like this:
Ret1 = R1 + γ * λ * R2 + γ^2 * λ^2 * R3 + ...
+ γ * (1 - λ) V2 + γ^2 * λ * (1 - λ) V3 + ...
returns는 advantages + values
for t in reversed(range(response_length)):
nextvalues = values[:, t + 1] if t < response_length - 1 else 0.0
delta = rewards[:, t] + self.gamma * nextvalues - values[:, t]
lastgaelam = delta + self.gamma * self.lam * lastgaelam
advantages_reversed.append(lastgaelam)
advantages = torch.stack(advantages_reversed[::-1], dim=1)
returns = advantages + values
loss
최종적으로 loss는 다음과 같이 계산한다. policy gradient loss와 value function loss의 합으로 구성된다.
# Value function loss
# returns는 advantages + old_values
vf_loss1 = (values - returns) ** 2
vf_loss2 = (values_clipped - returns) ** 2
vf_loss = 0.5 * torch.sum(torch.max(vf_loss1, vf_loss2) * mask) / n
vf_clipfrac = torch.sum((vf_loss2 > vf_loss1).float() * mask) / n
# Policy gradient loss
log_ratio = (logprobs - old_logprobs) * mask
ratio = torch.exp(log_ratio)
# Unbiased KL-div estimates (`k3`). Ref: http://joschu.net/blog/kl-approx.html
with torch.no_grad():
approx_kl = torch.mean((ratio - 1) - log_ratio)
# advantages에 rewards가 계산되어 있음
pg_loss1 = -advantages * ratio
pg_loss2 = -advantages * torch.clamp(
ratio,
1.0 - trainer.config.method.cliprange,
1.0 + trainer.config.method.cliprange,
)
pg_loss = torch.sum(torch.max(pg_loss1, pg_loss2) * mask) / n
pg_clipfrac = torch.sum((pg_loss2 > pg_loss1).float() * mask) / n
# Total loss
# trainer.config.method.vf_coef default valus is 1.
loss = pg_loss + trainer.config.method.vf_coef * vf_loss
학습 방식
기본값으로 num_layers_unfrozen이 2로 설정되어 있고, 이 마지막 2개 레이어(총 12개 레이어)를 학습하는 방식으로 되어 있다. 매우 미세하게 값을 조정하며, 원본 값은 frozen_head에 계속 유지한다.
============================================================
Parameter containing:
tensor([[-0.0418, -0.1882, 0.0989, ..., -0.1225, 0.0758, 0.0729],
[ 0.0500, -0.2824, -0.0453, ..., -0.1577, 0.0993, 0.0965],
[ 0.1774, -0.0596, -0.0796, ..., 0.0216, 0.0444, 0.0930],
...,
[ 0.0535, -0.0256, -0.2634, ..., -0.1661, 0.0180, -0.2355],
[-0.0589, 0.0045, 0.0908, ..., -0.0214, -0.0606, -0.1167],
[-0.1507, 0.0434, -0.0128, ..., -0.0773, -0.0020, -0.0625]],
device='cuda:0', requires_grad=True)
------------------------------------------------------------
Parameter containing:
tensor([[-0.0428, -0.1871, 0.0970, ..., -0.1240, 0.0756, 0.0716],
[ 0.0492, -0.2819, -0.0470, ..., -0.1572, 0.0993, 0.0957],
[ 0.1783, -0.0613, -0.0813, ..., 0.0190, 0.0401, 0.0943],
...,
[ 0.0526, -0.0215, -0.2645, ..., -0.1663, 0.0151, -0.2355],
[-0.0611, 0.0044, 0.0869, ..., -0.0195, -0.0615, -0.1160],
[-0.1521, 0.0433, -0.0122, ..., -0.0762, -0.0007, -0.0643]],
device='cuda:0')
============================================================
상단이 RLHF로 학습된 레이어, 하단은 원본. 매우 미세하게 값이 조정된 것을 확인할 수 있다.
trlX 메소드 중 forward_hydra()를 별도로 제공하는데, 10개까지는 기존 레이어를 사용하고 마지막 2개는 frozen_head를 사용하여 RLHF 이전의 원래의 값을 리턴하는 역할을 한다.
vocab size만큼의 logits를 구한 다음(forward() 이용), softmax 값으로 log probabilities를 구하고, 이 값의 차이(학습 된 모델 - 원본 모델)만큼의 log ratio를 구해 KL Controller의 값(단일 scalar)에 곱해서 kl_penalty를 구한다. 이 값은 rollout 단계에서 reward가 되며 크기는 token size와 같다.
query_tensor=prompt_tensors[sample_idx],
response_tensor=sample_outputs[sample_idx],
logprobs=all_logprobs[sample_idx],
values
상단이 RLHF로 학습된 레이어, 하단은 원본. 매우 미세하게 값이 조정된 것을 확인할 수 있다. all_values[sample_idx], rewards=rewards, 모든 샘플에 대해 이 값을 만들어 PPORLElement에 저장한다. values는 v_head(2 layers)를 통과한 scalar 값이며 token size와 같다. logprobs도 token size와 같다. rewards 의 맨 마지막에는 score(sentiment score)를 더해준다. token size = 최종 샘플링 문장 full sentence.
통계
policy/sqrt_kl:self.mean_kl = (log_ratio.exp() - 1 - log_ratio).mean()이 값은 kl_ctl_value를 업데이트할 때 사용된다.kl_ctl_value: Adaptive KL Controller 값. 배치 단위로 업데이트 되지만 PPO 논문에서는 한 배치에서 여러번 업데이트가 일어나고, 여기서도 같은 구조로 되어 있다.exp_scores/mean: rollout 단계에서 평가한 점수 평균reward/mean: 여기서는 evaluate 과정 중 reward_fn을 통해 받는 점수의 평균을 의미한다. 학습 단계의 rewards는 단순 reward_fn뿐만 아니라 kl_penalty를 모두 포함하므로 유의time/exp: rollout 소요 시간
실험
PPO 알고리즘을 이용한 IMDB sentimental analysis 진행
현재는 hf의 accelerate로 학습 진행. 345M 모델이며 device당 50GB 메모리 차지. 단일 노드에서 multi gpus 학습은 문제 없다.
- SFT: https://huggingface.co/robowaifudev/megatron-gpt2-345m 모델 사용. IMDB의 positive review를 1 epoch fine-tuning 진행
- RM:
lvwerra/distilbert-imdb의 점수로 평가 - PPO:
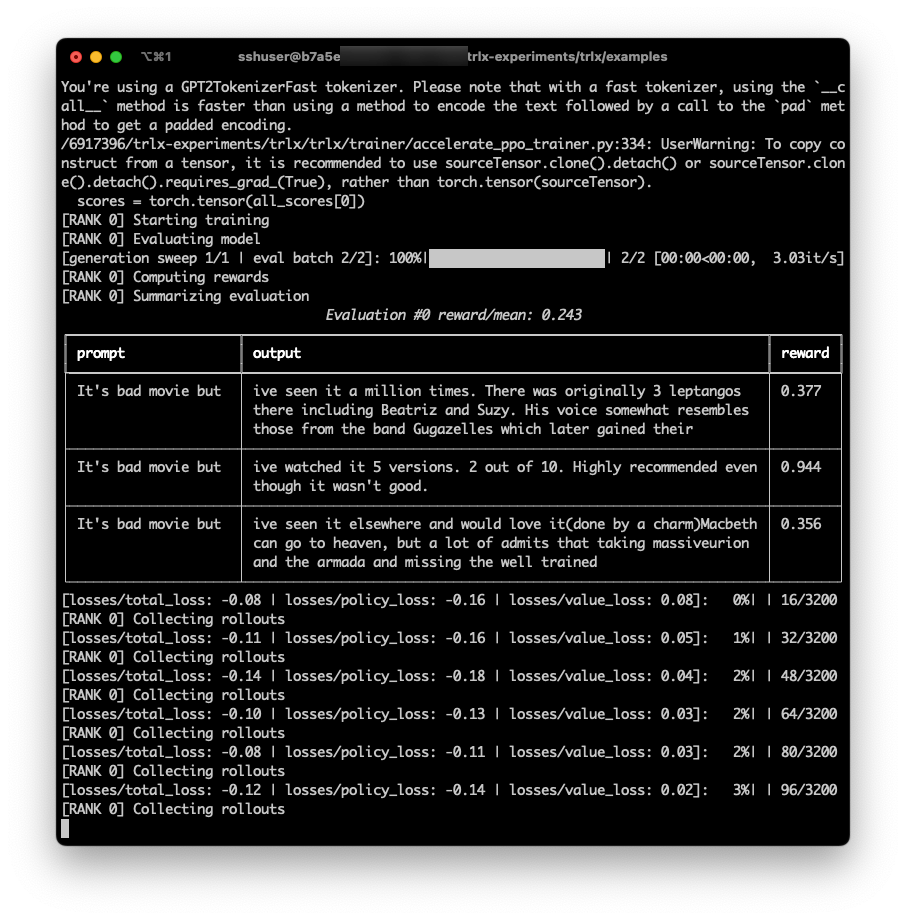
테스트:
$ curl -X PUT http://xxx:8888/ \
-H 'Content-Type: application/json' \
-d '{"prompt": "this movie was sucks!"}' | jq
[
{
"model": "megatron-gpt2-345m"
},
{
"GPT": "this movie was sucks! I'm not going to watch it again! I'm not going to watch",
"score": 0.005337238311767578
},
{
"SFT": "this movie was sucks! I mean, it was so bad that it was good. I mean,",
"score": 0.008551597595214844
},
{
"PPO": "this movie was sucks! I loved it, but I loved it so much, I watched it over",
"score": 0.8951831459999084
}
]
관련 논문
모두 오픈AI의 논문으로 시간순으로 배열하면 다음과 같다.
- Proximal Policy Optimization Algorithms
- Fine-Tuning Language Models from Human Preferences
- Learning to summarize from human feedback
- 마지막 논문 구현은 wandb에서 구현한 샘플이 있음. Implementing RLHF: Learning to Summarize with trlX 이 샘플을 기준으로 실험하는게 가장 좋아 보임.
적용을 위해 해결해야 하는 과제
7B 모델에 trlX를 이용해 PPO 모델을 구축하려면 다음과 같은 작업이 필요하다.
- SFT: tensor parallel = 2, pipeline parallel = 2인 NeMo 모델을 hf에서 읽어들일 수 있는 포맷으로 변환
- RM: Implementing RLHF: Learning to Summarize with trlX 문서를 보면 문장을 pair로 주고 선택/탈락 reward를 주는 방식으로 학습. InstructGPT 논문에는 6.7B 모델을 사용했다고 나옴.
- NeMo는 slurm 지원이 되는데 accelerate로 slurm 효율적인 활용 방안 검토 필요
trlX 로드맵
PPO NeMo 지원이 진행 중이므로 굳이 별도 개발 또는 contribution은 의미 없어 보인다. 그러나 초기에는 물론, 당분간은 hugging face로 실험하는게 바람직해보인다.