

머신러닝 책
- 머신러닝 시스템 디자인 패턴 2021, 2021
- 머신러닝 시스템 설계 2023, 2023
- 밑바닥부터 시작하는 데이터 과학 2판 2019, 2020
- 트랜스포머를 활용한 자연어 처리 2022
- 카카오 아레나 데이터 경진대회 1등 노하우 2021
- 머신러닝, 딥러닝 문제해결 전략 2022
- 실전 예측 분석 모델링 2013, 2018
- XGBoost와 사이킷런을 활용한 그레이디언트 부스팅 2020, 2022
- 직장인을 위한 데이터 분석 실무 with 파이썬 2020
- 실전 예측 분석 모델링 2013, 2018
- 데이터 과학자와 데이터 엔지니어를 위한 인터뷰 문답집 2018, 2020
- Algorithms of the Intelligent Web 2009
- 마스터 알고리즘 2015, 2016
- 기계는 어떻게 생각하는가? 2018, 2019
- 단단한 머신러닝 2016, 2020
머신러닝 시스템 디자인 패턴 2021, 2021
★★★☆☆
머신러닝 나아가 딥러닝 시스템을 어떻게 구축하고 운영하면 좋을지 MLOps를 다루는 일본책이다. 실제 저자의 운용 경험이 녹아있어 실용적이고 일본책 답게 패턴, 안티패턴 등으로 나열한 체계적인 정리가 좋다.
fastapi, unicorn, gunicorn을 사용해 API 시스템을 구축한다.
- p53 uvicorn을 gunicorn에서 기동함으로써 ASGI의 비동기 처리와 WSGI의 멀티 프로세스를 조합할 수 있게 되어 있다.
- 함수에
async def를 사용한다. - docker compose를 활용한다.
- p255 구글에서는 스마트폰으로 데이터의 입력부터 전처리, 추론, 후처리까지 일련의 연산으로 변환해주는 mediapipe라는 라이브러리를 제공한다. 찾아보니 on-device ML을 위한 솔루션이다.
- p318 부하 테스트 tsenart/vegeta
머신러닝 시스템 설계 2023, 2023
★★★★☆
면접의 형식을 취하고 있으며 구체적인 구현 보다는 전반적인 개념과 큰 흐름을 설명하는 MLOps를 위한 책이다. ML 시스템의 다양한 구성을 소개한다.
밑바닥부터 시작하는 데이터 과학 2판 2019, 2020
★★★★☆
간단한 예제로 시작해 다양한 예제와 실행 가능한 깔끔한 코드로 결과를 보여주는 실용적인 접근이 매력적이다, 실용적인 데이터 과학을 공부하고 싶다면 이 책이 가장 적절할 것이다. 기본적인 머신러닝 알고리즘을 다루기 때문에 데이터 분석가에게 유용한 책이다.
트랜스포머를 활용한 자연어 처리 2022
★★★★☆
허깅페이스 팀에서 직접 만든 책으로 NLP 다양한 분야에 대한 트랜스포머 활용법을 소개한다. 실용서다 보니 몇 년만 지나도 내용이 다 바뀐다는 문제가 있지만 가볍게 기본을 익히는 용도로 훌륭하다.
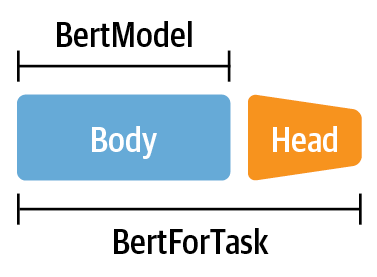
- Multilingual NER, BertForTask, Zeroshot Transfer
카카오 아레나 데이터 경진대회 1등 노하우 2021
★★★☆☆
- p79. 문장 tokenize는 sentencepiece 사용
- p128. 선택된 유사글은 실시간 랭킹 최적화(MAB)의 탐색(Exploration) 과정을 통해 CTR을 측정하고, CTR이 높은 글을 선택하는 활용(Exploitations) 과정을 통해 사용자가 볼만한 글을 추천합니다.
- p161. 성능 평가 지표로 NDCG, MAP 이용. Entropy Diversity는 예측 결과에 얼마나 다양한 데이터가 존재하는지를 뜻하는 성능 평가 지표로 사용한다.
- p244.
dedup_recs = [x[0] for x in dedup_recs_sorted] dedup_recs = list(map(lambda x:x[0], dedup_recs_sorted))
머신러닝, 딥러닝 문제해결 전략 2022
★★★☆☆
제목에 캐글이 포함되어 있진 않지만 사실상 매우 친절한 캐글 가이드북이다. 머신러닝의 기본적인 내용을 친절하게 다루고 있다. 그러나 입문서로 기초적인 내용만 다루고 있어 아쉽게도 따로 정리할 만한 내용은 없었다.
실전 예측 분석 모델링 2013, 2018
2020년에 이어 다시 읽었다. 코드가 많은 것은 좋지만 오래된 책 답게 R로 구성되어 있는 점이 다소 아쉽다. 그리고 번역에 오류가 너무 많은 점은 더욱 아쉽다.
- p401. SVN은 1960년대 중반 vapnik이 개발했고, 1960년대 후반으로 가면 이 모델은 당시 사용할 수 있는 머신러닝 기법 중 가장 유연하고 효과적인 방법 중 하나로 진화하며, vapnik(2010)은 이를 포괄적으로(범용적으로?) 사용하는 방안을 내놓는다.
- p438. 분류 트리의 다른 방법으로는 C4.5 모델이 있다(Quinlan, 1993b) 정보 이론에 따라 분기 기준을 만든다(Wallace, 2005; Cover and Thomas 2006)
- p642. R에서 caret패키지가 매우 유용한데 Python에는 이와 비슷한 pycaret이 있다.
-
XGBoost와 사이킷런을 활용한 그레이디언트 부스팅 2020, 2022
★★★☆☆
Linear Regression으로 시작해서 Decision Tree, RF, GB로 이어지는 과정을 차례로 설명한다. 노트북 방식으로 따라해볼 수 있게 되어 있다. - p123. 모든 트리가 동일한 실수를 저지르면 랜덤 포레스트도 실수를 한다. 데이터를 섞기 전에 이런 경우가 나타나기도 한다. 그래서 트리의 실수로부터 배워서 초반의 단점을 개선할 수 있는 앙상블 방법이 도움이 될 수 있다. 부스팅은 트리가 저지른 실수에서 배우도록 설계되었다.
- p230. F1 점수는 precision과 recall의 harmonic mean이다. p와 r의 분모가 다르기 때문에 이를 동일하게 만들기 위해 hm을 사용한다. p, r이 모두 중요할 때 F1 점수를 사용하는 것이 좋다. 0~1사이의 값을 갖는다.
- p346. 이미지나 텍스트 같이 구조적이지 않은 데이터를 다룬다면 신경망이 더 알맞을 것. 하지만 테이블 형태의 데이터를 사용하는 대부분의 머신러닝 작업에서는 XGBoost가 더 도움이 될 것.
직장인을 위한 데이터 분석 실무 with 파이썬 2020
풍부한 사례와 시각화가 좋다. 특별히 색다른 내용은 없다. 다른 분석 책과 달리 크롤링에 많은 지면을 할애하고, 시각화를 진행하는데 까지 소개한다. 좀 더 현실에 가깝게 집필하려고 했던 흔적이 보인다.
실전 예측 분석 모델링 2013, 2018
★★★☆☆
좋은 책이지만 번역에 문제가 있다. 우리말 비문이 너무 많아 요즘 기계 번역으로 번역한 수준에도 미치지 못한다.
- p242. 포레스트가 커질수록 모델을 훈련하고 구축하는 데 많은 계산 부하가 생긴다. 성능이 저하될 때까지 트리를 추가한다.
- p246. 부스팅 모델은 원래는 분류 문제에서 만들어진 것으로, 이후 회귀쪽으로도 확장됐다.
- 1990년대 초기에 부스팅 알고리즘이 탄생했다. 효과적으로 구현할 수 있는 방안을 찾기 위해 오랜 시간 고생했으며 1999년 에이다부스트 알고리즘을 만들어 냈다.
데이터 과학자와 데이터 엔지니어를 위한 인터뷰 문답집 2018, 2020
★★★★★
좋은 책이지만 지나치게 어렵다. 이 책을 제대로 이해할 사람이 얼마나 될까 싶다. 인터뷰 문제도 상당히 어렵다. 내부 동작 원리까지 거의 꿰는 수준을 요구한다. 좋은 내용임에도 불구하고 중국책이라는 한계와 함께 많이 팔리지 않은듯 하여 안타깝다.
Algorithms of the Intelligent Web 2009
『Algorithms of the Intelligent Web』 챕터 1의 전체 노트 중 몇 가지만 따로 정리한다.
- Inference does not happen instantaneously. 추론은 순식간에 되지 않는다. 모든 데이타셋/알고리즘이 응답 시간 제한내에서 실행될 것이라고 가정하면 안된다.
- Size matters!
- Different algorithms have different scaling characteristics. Some algorithms are scalable, and others aren’t. 수십억 개의 뉴스 중에서 유사한 제목의 뉴스 그룹을 찾는다고 가정해보자. Not all clustering algorithms can run in parallel. 경우에 따라서는 데이타 자체를 분할해야 할 수 있다.
- Everything is not a nail! 모든 문제에 통용되는 만능 알고리즘은 없다. 이 책의 저자는 Pedro Domingos의 2012년 ACM 논문을 참고 했고, 그는 『Master Algorithms』 이라는 만능 알고리즘이 존재할 것이라는 책을 쓰긴 했지만.
- Human intuition is problematic. 직관하기 어려운 고차원에서 다변량 가우스 분포multivariate Gaussian distribution의 대부분은 평균 근처에 있지 않고 바깥shell에 있다. 낮은 차원에서 간단한 분류자를 만드는 것은 쉽지만 차원 수를 늘리면 어떤 일이 일어나는지 이해하기 어렵다.
- “garbage in, garbage out.”
- Learn many different models. 넷플릭스 프라이즈의 우승자는 100개 이상의 학습기를 앙상블로 구축했다고 한다.
(Algorithms of the Intelligent Web, 2016) - Chapter 2부터 다시 읽어야 한다, 2017년 12월
마스터 알고리즘 2015, 2016
머신러닝 다섯 종족
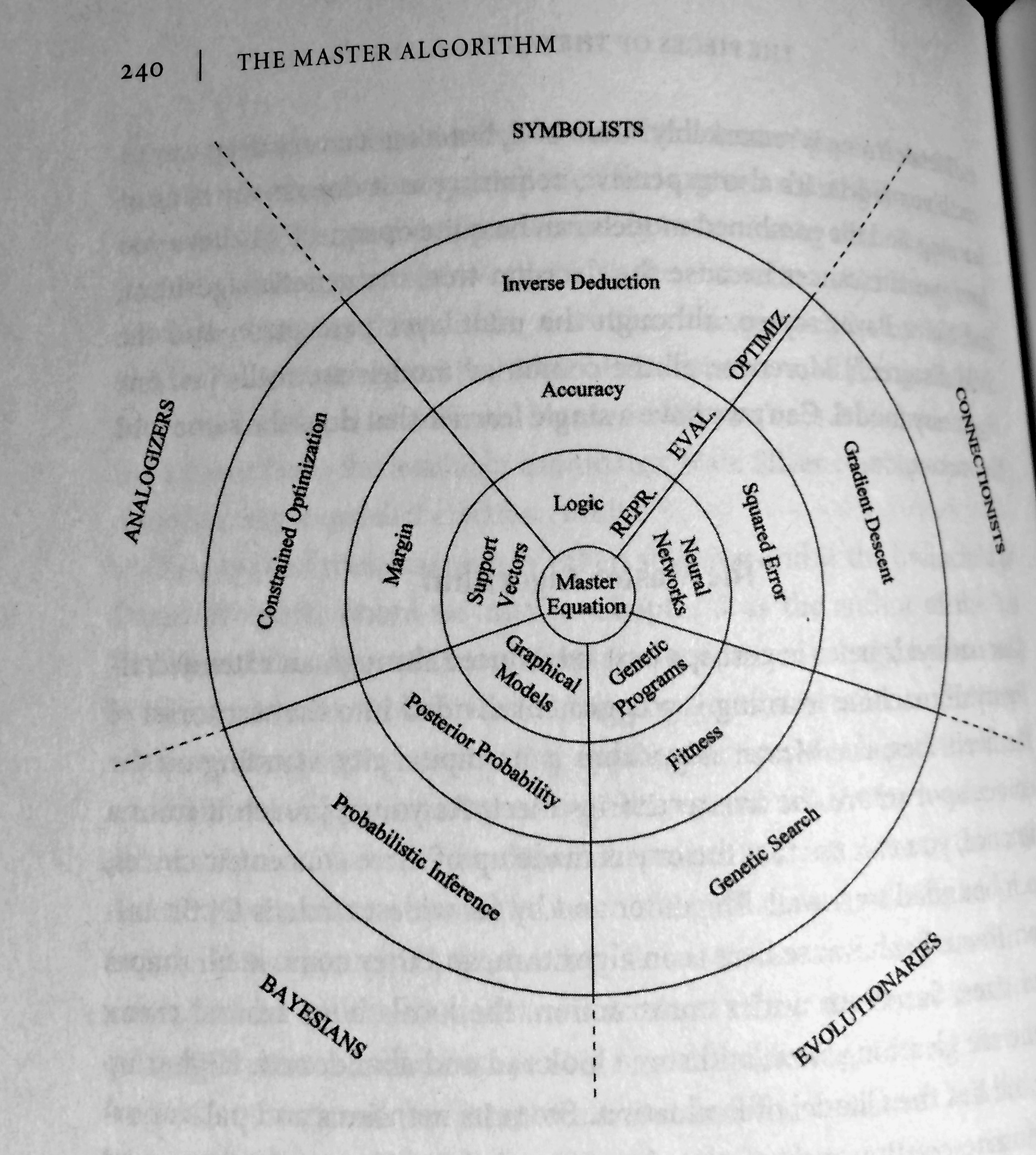

왼쪽 Sebastian Raschka의 정리와 오른쪽은 내가 직접 책에서 촬영했다.
합리주의자 The rationalist는 첫 행동을 개시하기 전에 모든 것을 계획한다. 경험주의자 The empiricist는 여러가지 시도를 해보고 결과가 어떻게 나오는지 확인한다. david hume은 가장 위대한 경험주의자이며 역사상 가장 위대한 18세기 철학자다. p.114
퍼셉트론의 역사에 나타난 역설적인 사건들 중에서 가장 슬픈 일은 프랭크 로젠블랫이 1969년 체사피크 만에서 보트 사고를 당해 자기 창조물의 둘째 장(민스키가 아니라 자신이 옳았다는)을 보지 못하고 죽은 사건일 것이다. p.194
구글의 연구 부서장인 피터 노빅이 언젠가 나에게 나이브 베이즈 분류기는 구글에서 가장 널리 쓰이는 머신러닝이고 구글이 하는 일의 구석구석에 머신러닝이 적용된다고 말했다. p.252
SVM은 퍼셉트론의 일반형으로도 볼 수 있는데, 유형을 나누는 초평면의 경계는 특별한 유사성 측정(벡터 사이의 내적dot product. numpy도 .dot 사용)을 사용할 때 얻는 것이기 때문이다. 하지만 SVM은 다층 퍼셉트론과 비교하여 중요한 장점이 있었다. 가중치에는 국부 최적값이 많지 않고 단일한 최적값이 있으므로the weights have a single optimum instead of many local ones 신뢰성 있게 가중치를 찾기가 훨씬 더 쉽다. 이런 장점이 있으면서도 SVM의 비용은 다름 아닌 다층 퍼셉트론의 비용과 같았다. 서포트 벡터들은 실제적으로 하나의 은닉층처럼 작동하고 벡터들의 가중 평균은 출력 층처럼 작동한다. p.317
나이브 베이즈 분류기가 단 하나의 단어만 알아보는 문서에 대하여 그 단어가 학습 데이터에서는 우연히 스포츠에 관한 문서에만 있었다면, 나이브 베이즈 분류기는 그 단어를 포함한 문서를 모두 스포츠에 관한 문서로 착각하기 시작한다. 하지만 마진 최대화 방식 덕택에 SVM은 차원이 매우 높을 때조차도 과적합 문제에서 벗어날 수 있다. p.318
기계는 어떻게 생각하는가? 2018, 2019
넷플릭스 프라이즈와 인공 지능

벨코의 기본 모델은 사용자 전체를 대상으로 놓고 보면 그럴 듯 했지만 훌륭하다고는 할 수 없었다. 이는 단일 모델이 모든 사람에게 적용될 수 없다는 사실을 보여준다. 미국 공군은 1950년대에 발생한 수많은 항공기 사고를 조사하면서 이와 동일한 현상을 발견했다. 1920년대부터 항공기 조종석은 미국인 남성의 평균 체형에 맞추어 제작했다. 이 문제를 연구했던 길버트 대니얼스Gilbert Daniels 중위는 미국인 남성 대부분의 체형이 평균에 가깝지 않다는 것을 발견했다. 토드 로즈Todd Rose는 『평균의 종말』이라는 책에서 이러한 상황을 다음과 같이 설명했다.
조종사 4,063명의 신체 치수 10개 항목을 측정해 평균을 구했으나 조종사 중 모든 신체 치수가 이 10개 항목의 평균 범위에 들어가는 조종사는 한 명도 없었다. 어떤 조종사의 팔은 평균 보다 길지만 다리는 평균보다 짧았다. 어떤 조종사는 가슴둘레가 컸지만 엉덩이가 작았다. 놀랍게도 대니얼스는 10개의 치수 중 세 개(목둘레, 허벅지 둘레, 손목 둘레)만 선택한 경우조차 조종사의 3.5% 이하만 평균 범위에 들어간다는 사실을 발견했다. 대니얼스의 발견이 시사하는 바는 명확했다. 평균 체형의 조종사는 존재하지 않는다. 조종사의 평균 체형에 맞추어 설계한 조종석은 어떤 조종사의 체형에도 맞지 않는다.
이 발견을 토대로 대니얼스는 조종사가 자신의 체형에 맞게 조절할 수 있는 조종석을 제안했으며 공군을 이를 수용했다. 공군은 평균을 표준으로 삼는 방식을 포기함으로써 개인형 맞춤이라는 새로운 원칙을 제시했다. p.119
‘터미네이터 효과’를 잡아낼 수 있어야 했다. 터미네이터 효과란, 넷플릭스 사용자 중에는 SF와 액션 영화를 좋아하는 그룹이 있고, 어린이 영화를 좋아하는 그룹이 있고, 이 두 그룹 모두에 포함되는 사용자도 있고, 이 두 그룹에 포함되지 않는 사용자도 있는 상황을 설명하는 것이다. 터미네이터 효과를 해결하기 위해 참가자들은 대부분 행렬 인수 분해라는 방식을 사용했다. p.120
행렬 인수 분해 matirx factorization

행렬 인수 분해는 거대한 행렬이 중복된 정보를 많이 갖고 있다는 사실을 기반으로 한다.
‘쥬라기 공원’이 각 장르에 해당하는지를 나타내는 숫자에 스티븐 스필버그가 각 장르를 얼마나 좋아하는지 나타내는 숫자를 곱한 뒤, 이 숫자들을 모두 합산하여 스필버그가 ‘쥬라기 공원’을 얼마나 좋아하는지를 나타내는 점수를 구한다. p.122

지금 살펴본 방법이 행렬 인수 분해다. 이 알고리즘은 개인화된 추천 기능을 만들기 위해 살펴볼 만한 가장 중요한 알고리즘이며 꼭 습득해야 하는 핵심 개념이다. 이 알고리즘에 행렬 인수 분해라는 이름이 붙은 이유는, 영화와 사용자에 대한 정보를 나타내는 숫자가 담긴 두 개 이상의 행렬(인수)을 곱해 위위 이미지 처럼 거대한 평점 행렬과 같은 원시 데이터를 만들어 그 데이터로부터 근사치를 계산하는 방식이기 때문이다. p.123
대회가 열렸던 첫해부터 널리 쓰인 모델은 ML@UToronto 팀의 연구원들이 개발한 인공 신경망이었다. 이 신경망은 수학적으로 행렬 인수 분해와 매우 유사했지만 존재하지 않는 평점 처리를 다른 방식으로 했으며, 평점을 1.0과 5.0 사이의 실수 대신에 1, 2, 3, 4, 5라는 다섯 개의 불연속적인 범주로 취급했다. p.134
시간에 따른 평점 예측
넷플릭스 프라이즈가 열린 두 번째 해에 참여한 팀들은 사용자가 ‘언제’ 영화에 평점을 매겼는지도 주목하기 시작했다. p.135

넷플릭스 프라이즈의 데이터는 데이터 마이닝의 보물 창고 였다. 한 가지 사례를 더 들면, 빅카오스 팀은 영화 제목에 숫자가 포함되어 있는지 여부로 사용자의 호감을 예측할 수 있다는 것을 발견했다(효과는 미미했지만 이러한 현상이 분명히 존재했다). p.138
기타
- p407 세바스찬 스런은 스탠리를 만드는 작업을 통해서 고성과를 낸 팀에게 필요한 기준을 알게됐다. 프로젝트를 진행하는 동안 핵심 팀원들은 팀으로 일하는 것이 어떤 의미인지 모두 잘 이해했습니다. 팀원들과 점심을 먹는 것은 최신 소프트웨어를 작성하는 공적만큼이나 중요했죠. 개인적으로 가장 기억에 남는 일을 꼽으라면 PVC 파이프로 대전차 장애물을 만들던 날이에요. 파이프의 표면이 녹슨 철처럼 보이지 않자 가게에 가서 스프레이 페인트를 구입한 뒤 페인트와 흙을 섞어서 제2차 세계 대전에 나오는 대전차 장애물처럼 보이게 만들려고 몇 시간을 보냈습니다. 제가 이런 일을 하려고 스탠퍼드에 온 건 아니었습니다. 하지만 손을 더럽혀 가며 과학적 가치가 없는 평범한 일에 시간을 쓰는 것이 얼마나 즐거웠는지 몰라요.
- p408 <이노베이터>에서도 비슷한 결론을 내렸다. 컴퓨터 역사에서 중요한 진전은 차고에서 고독한 엔지니어 혼자 이뤄낸 경우는 없었다. 인공 지능과 기계 학습의 진전도 이와 마찬가지다.
목차
- 자율 주행차와 인공 지능
- 넷플릭스 프라이즈와 인공 지능
- 강화 학습과 심층 신경망
전반부는 딥마인드와 아타리 강화학습을 얘기한다.- 인공 신경망이 보는 세상
CNN으로 이미지를 인식 - 심층 신경망의 내부 구조
CNN 내부 구조를 딥드림으로 변형하는 예제
- 인공 신경망이 보는 세상
- 세상과 소통하는 인공 지능
- 음성 인식, LSTM
- 자연어 이해, QA 태스크 소개
- 게임과 인공 지능
단단한 머신러닝 2016, 2020
중국어 제목: 机器学习
이 책은 2016년 1월에 출판되었고, 초판 5,000부가 일주일 만에 모두 팔렸습니다. 이후 8개월 동안 9쇄를 거듭하며 72,000부가 팔렸다. 현재 50만부가 넘게 팔림.
- 연습문제 4.3 정보 엔트로피에 기반하여 분할 선택을 진행하는 의사결정 트리 알고리즘에 대한 코드를 작성하고, 표 4.3의 데이터를 사용해 의사결정 트리를 생성하라. p.115

(표 4.3인데 4.4로 잘못 표기되어 있음)
- 4.7 그림 4.2는 재귀 알고리즘이다. 만약 매우 큰 데이터를 만나게 되면 의사결정 트리의 층수가 매우 깊어져, 재귀 방법을 사용하면 스택이 넘치기 쉽다. FIFO 데이터 구조를 사용하고 파라미터 MaxDepth로 트리의 최대 깊이를 제어할 수 있게 만들면서, 그림 4.2와 같은 값을 가지지만 재귀적 의사결정 트리 생성 알고리즘을 사용하지 않는 알고리즘을 작성해보라. (반복 구조로 구현하라는 얘기같다.)

- 4.8 DFS 과정을 BFS 과정으로 수정하고, 파라미터 MaxNode로 트리의 최대 노드 수를 제어하는 의사결정 트리 알고리즘을 문제 4.7을 기반으로 수정하라. 문제 4.7의 알고리즘과 비교했을때 어떤 것이 메모리 관리에 쉬운지 분석하라.
- 5.1 선형 함수 \(f(x)=w^{T}x\)를 신경망 활성화 함수로 사용했을 때의 결함에 대해 설명하라.
- 6.4 선형 판별분석과 선형 커널 서포트 벡터 머신이 어떤 조건에서 같은지 논의하라.
- 6.6 SVM이 노이즈에 대해 민감한 이유를 설명하라.
- 6.9 커널 트릭을 로지스틱 회귀로 확장하여 사용하라. (커널 로지스틱 회귀를 만들어라)
- 6.10 SVM의 서포트 벡터의 숫자를 확연히 줄이면서 일반화 성능은 많이 떨어지지 않는 방법에 대해 설명하라.
- 8.4 GradientBoosting과 AdaBoost의 차이를 분석하고 설명하라.
- 8.5 배깅에 대한 코드를 작성하라.
- 8.6 배깅이 (일반적으로) 나이브 베이즈 분류기의 성능을 높일 수 없는 이유를 분석하고 설명하라.
- 8.7 랜덤 포레스트가 왜 의사결정 트리 배깅 앙상블의 훈련 속도보다 빠른지 설명하라.
- 14.5 CRF와 로그 회귀(Logistic Regression?)를 비교하고 차이점을 설명하라.
Last Modified: 2024/03/30 14:07:25