

CNN, RNN
CNN
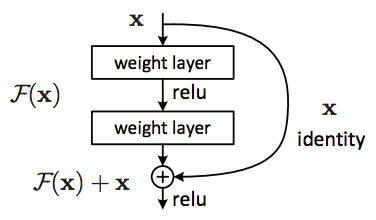
Deep Residual Network
통계학에서 residual 잔차은 표본 sample에서의 오차를 말한다. 오차는 모수의 개념이므로 표본에서는 통계량의 개념을 갖는 다른 용어로 부르는데, 반면 ResNet에서 residual은 extra의 의미에 더 가깝다.
Network depth is of crucial importance in neural network architectures, but deeper networks are more difficult to train. The residual learning framework eases the training of these networks, and enables them to be substantially deeper. 1
residual이 학습을 쉽게 하여 더 깊은 네트워크 구성이 가능하게 한다. 비슷한 파라미터로 더 깊은 구성이 가능하다.
Fine-tuning Deep Learning Models
이미지 CNN, 여기서는 VGG의 경우 pre-trained 모델을 fine-tuning 하는 기법에 대해 설명한다.
one would fine-tune existing networks that are trained on a large dataset like the ImageNet (1.2M labeled images) by continue training it (i.e. running back-propagation) on the smaller dataset we have. Provided that our dataset is not drastically different in context to the original dataset (e.g. ImageNet), the pre-trained model will already have learned features that are relevant to our own classification problem. 2
ImageNet 처럼 큰 데이터셋으로 학습된 모델에 우리가 가진 작은 데이터셋으로 학습을 계속해 pre-trained 모델을 fine-tuning 할 수 있다. 우리 데이터셋의 특징이 원래 데이터셋과(ImageNet)과 크게 다르지 않다면 pre-trained 모델은 우리의 분류 문제와 관련된 특징을 이미 학습했을 것이다.
Fine-tuning Techniques
- pre-trained 네트워크에서 ImageNet은 1000개 카테고리인데, 만약 우리가 10가지 카테고리라면 마지막 softmax를 10으로 변경한다.
- Use a smaller learning rate. 랜덤 초기화와 달리 pre-trained 가중치는 이미 좋을 것이므로 너무 빨리 왜곡하지 않도록 initial learning rate를 1/10 수준으로 낮추는 것이 일반적이다.
- freeze the weights of the first few layers. 처음 몇 레이어의 가중치 고정. 왜냐면 처음 몇 레이어는 curve, edge 같은 우리에게 여전히 도움되는 일반적인 정보를 학습하기 때문이다. 따라서 후속 레이어 학습에 보다 집중한다.

(딥러닝 부트캠프 with 케라스, 2017)

(딥러닝 부트캠프 with 케라스, 2017)
output layer를 제외한 모델을 feature extraction으로 활용해 SVM, XGBoost등을 적용할 수 있다.
RNN







- Vanilla mode of processing without RNN, from fixed-sized input to fixed-sized output (e.g. image classification).
- Sequence output (e.g. image captioning takes an image and outputs a sentence of words). 비디오 캡션, 아티스트 기반으로 음악 플레이리스트 생성, 파라미터를 기반으로 한 멜로디 생성, 사진 속에서 보행자 위치 찾기
- Sequence input (e.g. sentiment analysis where a given sentence is classified as expressing positive or negative sentiment). 날씨 예측, 음악 샘플 장르 구분, 영화 후기에 대한 감성 분석, 영화 시청 이력을 바탕으로 보고 싶어할 영화 확률 예측(데이터마이닝 에서는 collaborative filtering 구현)
- Sequence input and sequence output (e.g. Machine Translation: an RNN reads a sentence in English and then outputs a sentence in French).
- Synced sequence input and output (e.g. video classification where we wish to label each frame of the video). NER 태깅
Last Modified: 2021/06/08 13:03:45