
LLM Quantization
Knowledge Distillation
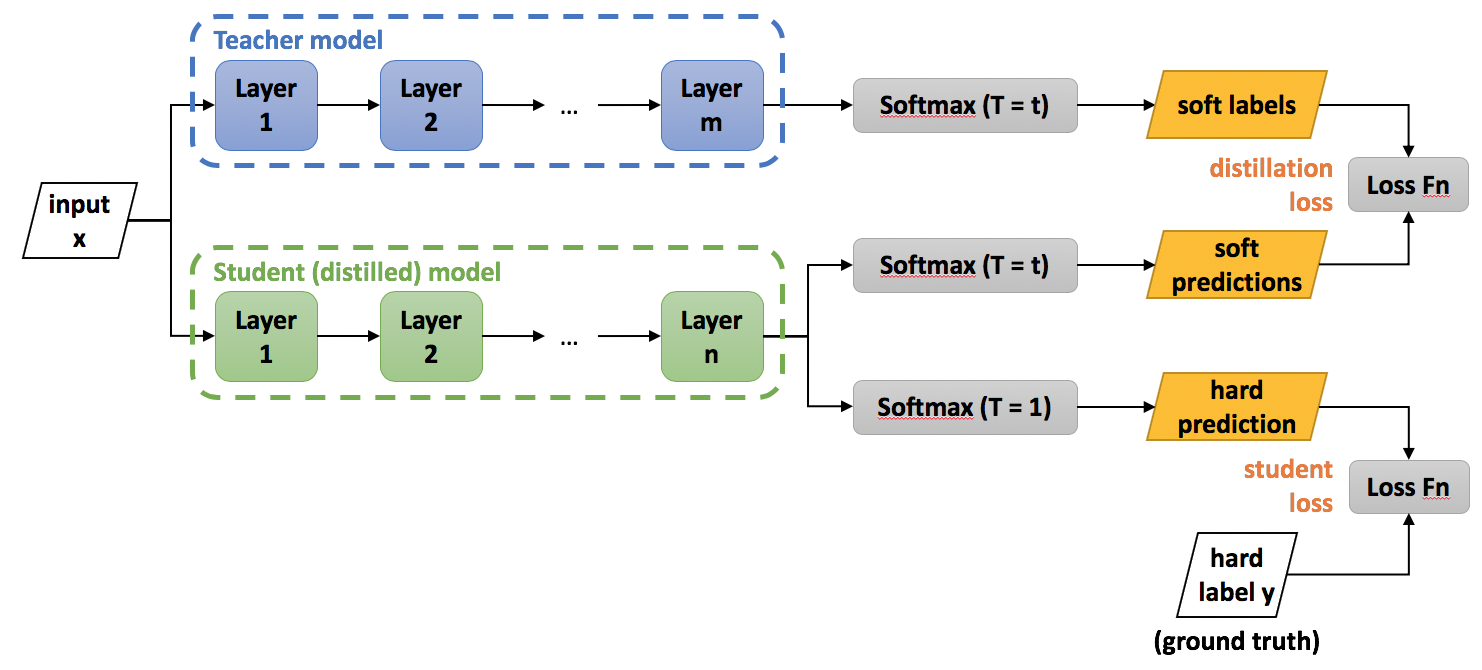
Teacher 모델의 지식을 작은 Student 모델에 distill. knowledge distillation은 2015년 힌튼2
Quantization

비교적 Sparse 공간이었다면 Dense하게 만들어도 성능 저하를 줄일 수 있다.
FastChat의 model compress 정리:
B = 2 ** (num_bits - 1) - 1 # 127
# 127에 max를 나눔
scale = B / torch.max(data.abs(), dim=group_dim + 1, keepdim=True)[0]
# max 값이 127이 됨
data = data * scale
# -127 ~ 127 사이로 값 강제 보정
data = data.clamp_(-B, B).round_().to(torch.int8)
decompress는 간단히 다음과 같다.
data = data / scale
전체를 max 기준으로 보정하면 잘리는 값들이 너무 많으므로 llama-7b의 경우 4096 임베딩을 16, 256으로 쪼개서 보정한다. 하지만 sparse하다는 가정은 outliers 때문에 모델의 성능에 영향을 끼친다. 따라서 outliers를 별도로 matmul하는 방식(bitsandbytes)으로 성능저하를 줄일 수 있다. FastChat은 20% 가량 속도 저하가 있다.
with init_empty_weights():
...
accelerate의 함수로 모델 가중치를 메모리에 할당하지 않고 모델 초기화
bitsandbytes
transformers에서 load_8bit=True로 가장 편하게 사용할 수 있다.
Llama-2-7b-chat-hf 모델 속도:
| dtype | tokens | speed | speed(s/token) |
|---|---|---|---|
| int8(bitsandbytes) | 488 | 67s | 0.1372s/token |
| float32 | 531 | 12.5s | 0.0235s/token |
| float16 | 531 | 13.6s | 0.0256s/token |
| bfloat16 | 481 | 12.3s | 0.0256s/token |
Llama-2-70b-chat-hf 모델 속도:
| dtype | tokens | speed | speed(s/token) |
|---|---|---|---|
| int8(bitsandbytes) | 531 | 192s | 0.3609s/token |
| float32 | 602 | 126s | 0.2093s/token |
따라서 모델이 클수록 좀 더 빠르게 동작해 효과가 크다.
EETQ
Llama-2-7b-chat-hf 모델 속도:
| dtype | tokens | speed | speed(s/token) |
|---|---|---|---|
| float32 | 531 | 12.14s | 0.0229s/token |
| bfloat16 | 481 | 11.86s | 0.0247s/token |
| eet_quantize | 508 | 12.62s | 0.0248s/token |
| eet_accelerator | 508 | 12.59s | 0.0248s/token |
- eet_quantize
from eetq.utils import eet_quantize eet_quantize(model) - eet_accelerator
from eetq.utils import eet_accelerator eet_accelerator(model, quantize=True, fused_attn=True, dev="cuda:0")
EETQ는 float16만 가능. 속도가 bfloat16과 비슷하며 quantization으로 인한 저하가 없다.
GPTQ
AutoGPTQ를 소스에서 설치. pip로는 CUDA extension이 설치되지 않았다는 오류 발생.
Llama-2-7b-chat-hf 모델 속도:
| dtype | tokens | speed | speed(s/token) |
|---|---|---|---|
| GPTQ | 523 | 12.25s | 0.0234/token |
| ExLlama | 523 | 13.16s | 0.0252/token |
| ExLlamaV2 | 523 | 13.32s | 0.0255/token |
from transformers import AutoModelForCausalLM, GPTQConfig
model_path = "Llama-2-7b-chat-hf-GPTQ"
gptq_config = GPTQConfig(use_exllama=True, bits=4)
model0 = AutoModelForCausalLM.from_pretrained(
model_path,
quantization_config=gptq_config,
use_safetensors=True,
torch_dtype=torch.float16,
device_map={'': device},
)
config.json에 quantization_config가 없을 경우 optimum을 이용해 quantization을 바로 진행하므로 주의. ExLlama는 GPU 76%, V2는 40%대 utilization으로 보다 효율적이다.
Llama 70B를 AutoGPTQ로 로딩 할 경우 아키텍처가 다르므로 inject_fused_attention=False 반드시 필요
model0 = AutoGPTQForCausalLM.from_quantized(
model_path,
device_map={'': device},
inject_fused_attention=False,
)
Llama-2-70b-chat-hf 모델 속도:
| dtype | tokens | speed | speed(s/token) |
|---|---|---|---|
| AutoModelForCausalLM | 523 | 35.77s | 0.0684/token |
| AutoGPTQForCausalLM | 523 | 32.11s | 0.0614/token |
AWQ
이 중에서 2x inference 속도로 개선했다는 autoawq4 적용. kernels가 빌드 속도 때문에 별도 프로젝트로 분리되어 있으며 빌드에 12분 걸린다. 둘 다 소스 설치를 해야 정상 동작했다.
# 동작 확인
$ python -c "import transformer_engine.pytorch as te"
$ python -c "from awq import AutoAWQForCausalLM"
$ python -m bitsandbytes
AWQ 모델 변환에 A100에서 12분 정도 소요.
quant_config = {"zero_point": True, "q_group_size": 128, "w_bit": 4, "version": "GEMV"}
Llama-2-7b-chat-hf 모델 속도:
| dtype | fused_layers | tokens | speed | speed(s/token) |
|---|---|---|---|---|
| GEMM | True | 503 | 5.06s | 0.0101s/token |
| GEMM | False | 574 | 14.53s | 0.0253s/token |
| GEMV | True | 503 | 4.07s | 0.0081s/token |
| GEMV | False | 574 | 13.16s | 0.0229s/token |
generate()시 max_new_tokens를 반드시 설정해야 한다. 모델은 AutoAWQForCausalLM로 로딩. 속도를 높이는건 fused_layers로 볼 수 있다.
import torch
from transformers import AwqConfig, AutoModelForCausalLM
quantization_config = AwqConfig(
bits=4,
fuse_max_seq_len=512,
do_fuse=True,
)
model = AutoModelForCausalLM.from_pretrained(
'Llama-2-7b-chat-hf-AWQ',
attn_implementation="eager",
quantization_config=quantization_config,
device_map={'': 1},
)
이렇게 로딩 했을 때 두 번째 generate()부터 tensor size가 맞지 않다는 에러가 발생한다. do_fuse=False일때는 문제가 없기 때문에 hf의 awq integration 문제로 보인다. GEMV모델은 tensor shape이 달라서 로딩조차 안된다.
Llama-2-70b-chat-hf 모델 속도:
| dtype | fused_layers | tokens | speed | speed(s/token) |
|---|---|---|---|---|
| GEMM | True | 523 | 29.14s | 0.0557s/token |
| GEMM | False | 523 | 36.44s | 0.0697s/token |
A100, H100 13B/GEMM 모델 속도:
| dtype | tokens | speed | speed(s/token) |
|---|---|---|---|
| NQ(Not Quantized) | 324 | 9.94s | 0.0307/token |
| A100 | 367 | 5.60s | 0.0153/token |
| H100 | 368 | 3.98s | 0.0108/token |
- H100 13B NQ: 51 tokens/s
- H100 13B GEMV 4bit, naive: 84 tokens/s
- H100 13B GEMV 4bit,
generate(): 88 tokens/s
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
model_path = '/models/m'
quant_path = '/models/m-AWQ-GEMV-4bit'
quant_config = {"zero_point": True, "q_group_size": 128, "w_bit": 4, "version": "GEMV"}
# Load model
model = AutoAWQForCausalLM.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
print(model)
# Quantize
model.quantize(tokenizer, quant_config=quant_config)
# Save quantized model
model.save_quantized(quant_path)
tokenizer.save_pretrained(quant_path)
Last Modified: 2024/02/13 18:12:04