

Perplexity
Perplexity
- 빌드:
$ make LLAMA_CUBLAS=1 - Convert:
$ python convert.py /models/42dot_LLM-SFT-1.3B-gguf/ --vocab-type bpe$ python convert-hf-to-gguf.py /models/gemma-7b/
- 모두
float16으로 실험
42dot_LLM-PLM-1.3B
$ CUDA_VISIBLE_DEVICES=2 ./perplexity -m /models/42dot_LLM-PLM-1.3B/ggml-model-f16.gguf -f wiki.test.raw
added_token.json과 vocab.json을 맞추고 --vocab-type bpe로 변환했다. 지정하지 않을 경우 Core dumped 오류가 발생하므로 주의
- wiki.test.raw #569 ETA 10.37 min
- Final estimate: PPL = 12.7406 +/- 0.09403
- #142 Perplexity: tensor(9.5208, device=’cuda:0’)1
- ai-book.raw(한글, 1-5장) #118 ETA 1.87 min
- Final estimate: PPL = 11.1382 +/- 0.16895
- #30 Perplexity: tensor(9.1947, device=’cuda:0’)
- bfloat16: Perplexity: tensor(9.1999, device=’cuda:0’)
- float32(많이 느림): Perplexity: tensor(9.1944, device=’cuda:0’)
f = open("./ai-book.raw") lines = f.readlines()
42dot_LLM-SFT-1.3B
$ CUDA_VISIBLE_DEVICES=2 ./perplexity -m /models/42dot_LLM-SFT-1.3B-gguf/ggml-model-F16.gguf -f wiki.test.raw
- wiki.test.raw #569 ETA 6.42 min
- Final estimate: PPL = 13.2594 +/- 0.09938
- #142 Perplexity: tensor(10.3943, device=’cuda:0’)
- ai-book.raw #118 ETA 1.75 min
- Final estimate: PPL = 12.6709 +/- 0.20299
- #30 Perplexity: tensor(10.2340, device=’cuda:0’)
Llama-2-7b
$ CUDA_VISIBLE_DEVICES=2 ./perplexity -m /models/Llama-2-7b-gguf/ggml-model-f16.gguf -f wiki.test.raw
- wiki.test.raw #655 ETA 28.80 min
- Final estimate: PPL = 5.7984 +/- 0.03236
- #164 Perplexity: tensor(4.9073, device=’cuda:0’)
- ai-book.raw #371 ETA 15.38 min
- Final estimate: PPL = 2.7178 +/- 0.01404
- #94 Perplexity: tensor(2.4290, device=’cuda:0’)
Llama-2-7b-chat
$ CUDA_VISIBLE_DEVICES=2 ./perplexity -m /models/Llama-2-7b-chat-gguf/ggml-model-f16.gguf -f wiki.test.raw
- wiki.test.raw #655 ETA 26.85 min
- Final estimate: PPL = 7.6338 +/- 0.05164
- #164 Perplexity: tensor(6.2608, device=’cuda:0’)
- ai-book.raw #371 ETA 15.82 min
- Final estimate: PPL = 3.9855 +/- 0.03160
- #94 Perplexity: tensor(3.4516, device=’cuda:0’)
gemma-7b
$ CUDA_VISIBLE_DEVICES=2 ./perplexity -m /models/gemma-7b/ggml-model-f16.gguf -f wiki.test.raw
- wiki.test.raw #569 ETA 25.75 min
- Final estimate: PPL = 7.8009 +/- 0.05042
- #142 Perplexity: tensor(5.9794, device=’cuda:0’)
- ai-book.raw #172 ETA 8.85 min
- Final estimate: PPL = 6.5314 +/- 0.07056
- #44 Perplexity: tensor(5.2072, device=’cuda:0’)
gemma-7b-it
$ CUDA_VISIBLE_DEVICES=2 ./perplexity -m /models/gemma-7b-it/ggml-model-f16.gguf -f wiki.test.raw
- wiki.test.raw #569 ETA 18.68 min
- Final estimate: PPL = 28.2536 +/- 0.31980
- #142 Perplexity: tensor(18.9067, device=’cuda:0’)
- ai-book.raw #172 ETA 7.42 min
- Final estimate: PPL = 48.1784 +/- 1.16831
- #44 Perplexity: tensor(31.1553, device=’cuda:0’)
gemma-ko-7b
$ CUDA_VISIBLE_DEVICES=2 ./perplexity -m /models/gemma-ko-7b/ggml-model-f32.gguf -f wiki.test.raw
float16에서는 nan으로 모델 평가가 진행되지 않는다(underflow?). gguf에서는 float32, hf에서는 bfloat16으로 진행
- wiki.test.raw #569 ETA 30.58 min
- Final estimate: PPL = 10.1615 +/- 0.06924
- #142 Perplexity: tensor(8.5561, device=’cuda:0’)
- ai-book.raw #172 ETA 12.13 min
- Final estimate: PPL = 4.7414 +/- 0.04712
- #44 Perplexity: tensor(4.1694, device=’cuda:0’)
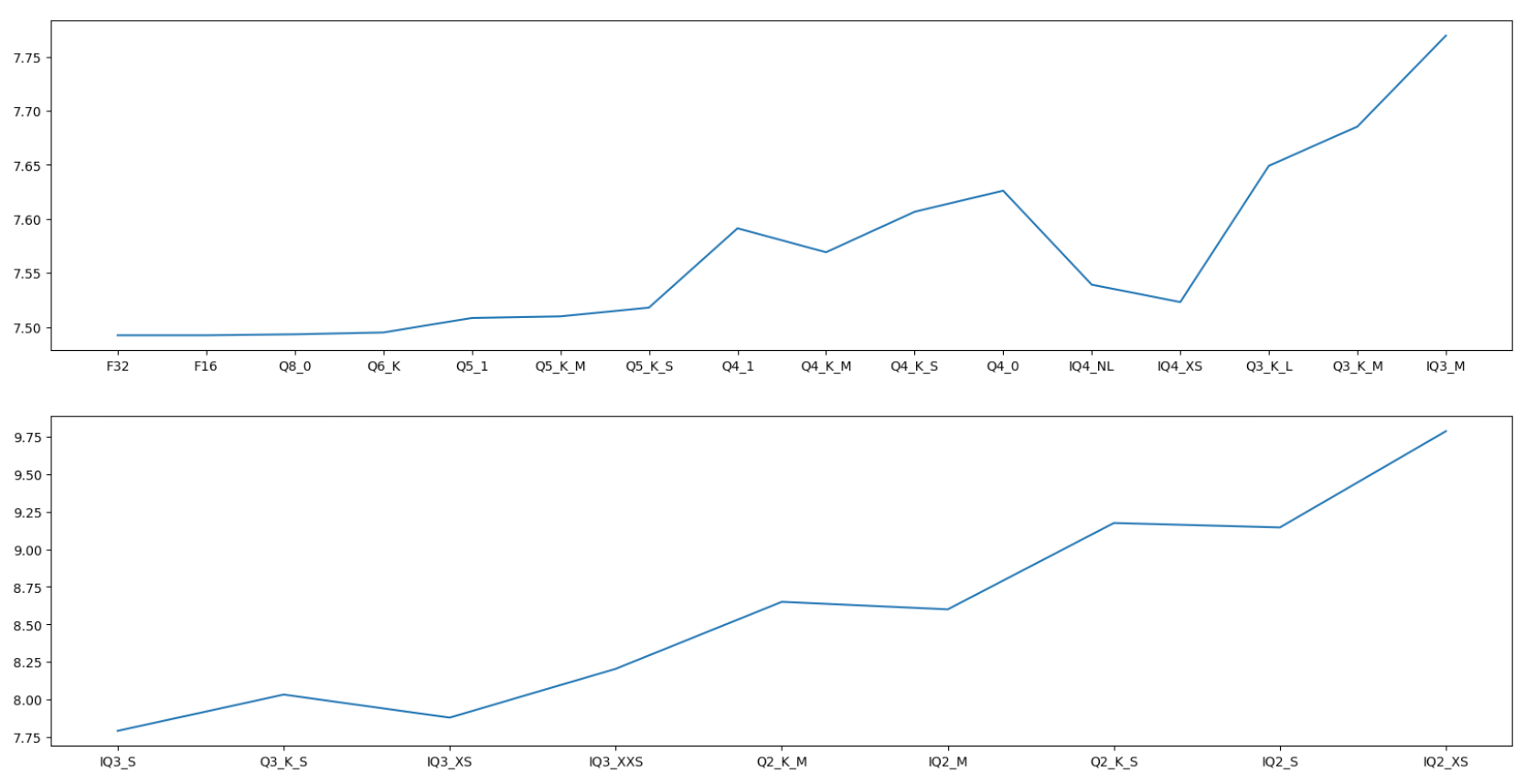
Llama 7B ppl
| Type | size | ppl |
|---|---|---|
| Llama 7B F32 | 25.10 GiB | 7.4924 |
| Llama 7B F16 | 12.55 GiB | 7.4924 |
| Llama 7B Q8_0 | 6.67 GiB | 7.4933 |
| Llama 7B Q6_K | 5.15 GiB | 7.4950 |
| Llama 7B Q5_1 | 4.72 GiB | 7.5084 |
| Llama 7B Q5_K_M | 4.45 GiB | 7.5099 |
| Llama 7B Q5_K_S | 4.33 GiB | 7.5180 |
| Llama 7B Q4_1 | 3.95 GiB | 7.5913 |
| Llama 7B Q4_K_M | 3.80 GiB | 7.5692 |
| Llama 7B Q4_K_S | 3.59 GiB | 7.6066 |
| Llama 7B Q4_0 | 3.57 GiB | 7.6261 |
| Llama 7B IQ4_NL | 3.56 GiB | 7.5392 |
| Llama 7B IQ4_XS | 3.37 GiB | 7.5231 |
| Llama 7B Q3_K_L | 3.35 GiB | 7.6491 |
| Llama 7B Q3_K_M | 3.07 GiB | 7.6854 |
| Llama 7B IQ3_M | 2.90 GiB | 7.7695 |
| Llama 7B IQ3_S | 2.75 GiB | 7.7904 |
| Llama 7B Q3_K_S | 2.75 GiB | 8.0321 |
| Llama 7B IQ3_XS | 2.60 GiB | 7.8787 |
| Llama 7B IQ3_XXS | 2.41 GiB | 8.2039 |
| Llama 7B Q2_K_M | 2.36 GiB | 8.6501 |
| Llama 7B IQ2_M | 2.20 GiB | 8.6002 |
| Llama 7B Q2_K_S | 2.16 GiB | 9.1756 |
| Llama 7B IQ2_S | 2.05 GiB | 9.1459 |
| Llama 7B IQ2_XS | 1.89 GiB | 9.7873 |
| Llama 7B IQ2_XXS | 1.73 GiB | 11.0326 |
| Llama 7B IQ1_S | 1.42 GiB | 28.7926 |
Last Modified: 2024/03/17 14:53:15