

Text Generation
model.generate()
# $ CUDA_VISIBLE_DEVICES=2 python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained('.')
model = AutoModelForCausalLM.from_pretrained('.').to(0)
prompt = '<human>: 안녕? <bot>:'
input_ids = tokenizer(prompt, return_tensors='pt').to(0).input_ids
outputs = model.generate(
input_ids,
do_sample=True,
max_new_tokens=1,
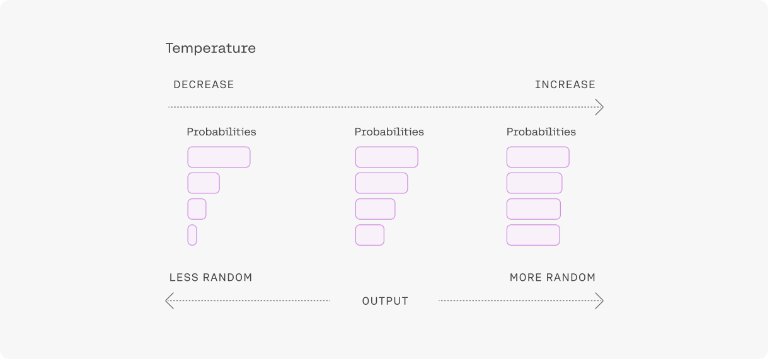
temperature=0.5,
top_p=0.95,
top_k=20,
repetition_penalty=1.2,
return_dict_in_generate=True,
output_scores=True,
)
print(tokenizer.decode(outputs['sequences'][0]))
max_length: input prompt + max_new_tokens
Orion-14B-Chat-RAG
# $ CUDA_VISIBLE_DEVICES=2 python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation.utils import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained(
"/models/Orion-14B-Chat-RAG", use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
"/models/Orion-14B-Chat-RAG",
torch_dtype=torch.bfloat16, trust_remote_code=True).to(0)
model.generation_config = GenerationConfig.from_pretrained("/models/Orion-14B-Chat-RAG")
messages = [{"role": "user", "content": "Hello, what is your name? "}]
print(model.chat(tokenizer, messages, streaming=False))
Temperature
Subword Tokenization
드물게 등장하는 단어를 더 작은 단위로 나눔
- BPE: GPT 사용. 단어를 유니코드 문자가 아닌 바이트 단위 구성으로 간주
- WordPiece: BERT 사용
- SentencePiece: BPE + Unigram LM Tokenizer
text = "Jack Sparrow loves New York!"
 WordPiece는 York과 ! 사이에 공백이 없다는 정보를 잃어버리지만 SentencePiece는 U+2581 또는 아래 1/4 블록 문자로 할당해 공백 정보를 보존한다.2
WordPiece는 York과 ! 사이에 공백이 없다는 정보를 잃어버리지만 SentencePiece는 U+2581 또는 아래 1/4 블록 문자로 할당해 공백 정보를 보존한다.2
pipeline
from transformers import pipeline
pipe = pipeline(model='.', device=3, task='text-generation')
text = '세계 최초로 달에 착륙한 우주인의 이름은 '
pipe(text, do_sample=True, top_p=0.9, max_new_tokens=256)
-
p142, 트랜스포머를 활용한 자연어 처리 ↩
Last Modified: 2024/02/23 18:29:52