

Transformer
minGPT
Karpathy의 minGPT를 여러 방법으로 실험하고 결과 정리
임베딩 및 기본 설정에 0.1 dropout 걸려 있으므로 주의. inference시 0 확인.
Multi-Head Attention
아래는 T=6 ~ 11, C=20, nh=4, hs=5
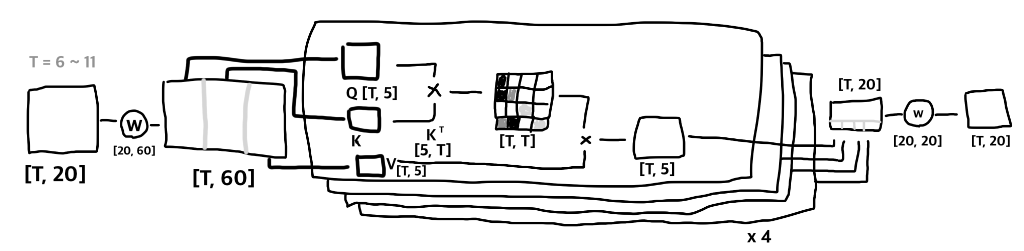
embedding을 3배수로 확장할 때 [:,:20]은 Q weights, [:,20:40]은 K weights, [:,40:]은 V weights로 가정할 수 있다. 결과 또한 동일하며 Q,K,V가 차례대로 나눠 갖고 nh(num of heads), T(context length) x T 필드를 펼쳐서 어텐션 맵을 형성한다.
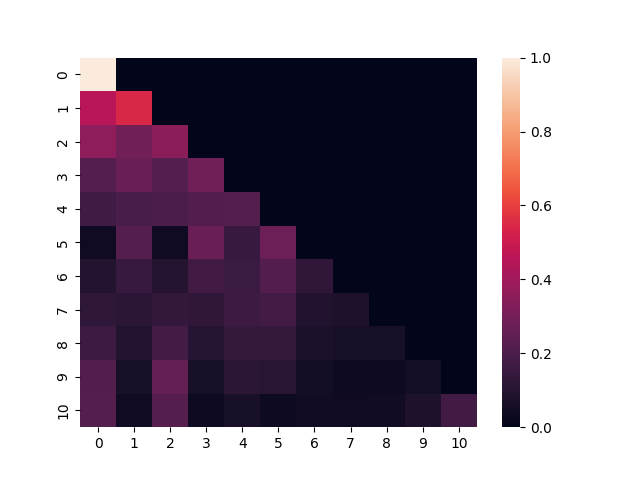
GPT는 masked multi-head attention(causal masking, 그림 어텐션맵 예제)이므로 첫 번째 토큰은 첫 번째에만 어텐션을 줄 수 있고, 마지막 토큰은 전체 토큰에 어텐션을 줄 수 있다. 즉 [1, 0]은 logit of how important “1” is to “0”.
이 맵은 nh 만큼 쪼갠 부분 임베딩 V에 어텐션을 주는 효과가 있으며 nh, T, hs로 나온 결과는 연결하여 원래값인 T x C(embedding dimensionality)로 만든다. 마지막으로 projection layer를 통과하고 이후에는 MLP forward를 진행한다. causal masking이므로 이전 token에 대한 logit은 모두 동일하며 캐싱할 수 있다. 만약 causal masking이 아니라면 뒤에 토큰에 따라 이전 값이 달라질 수 있다.
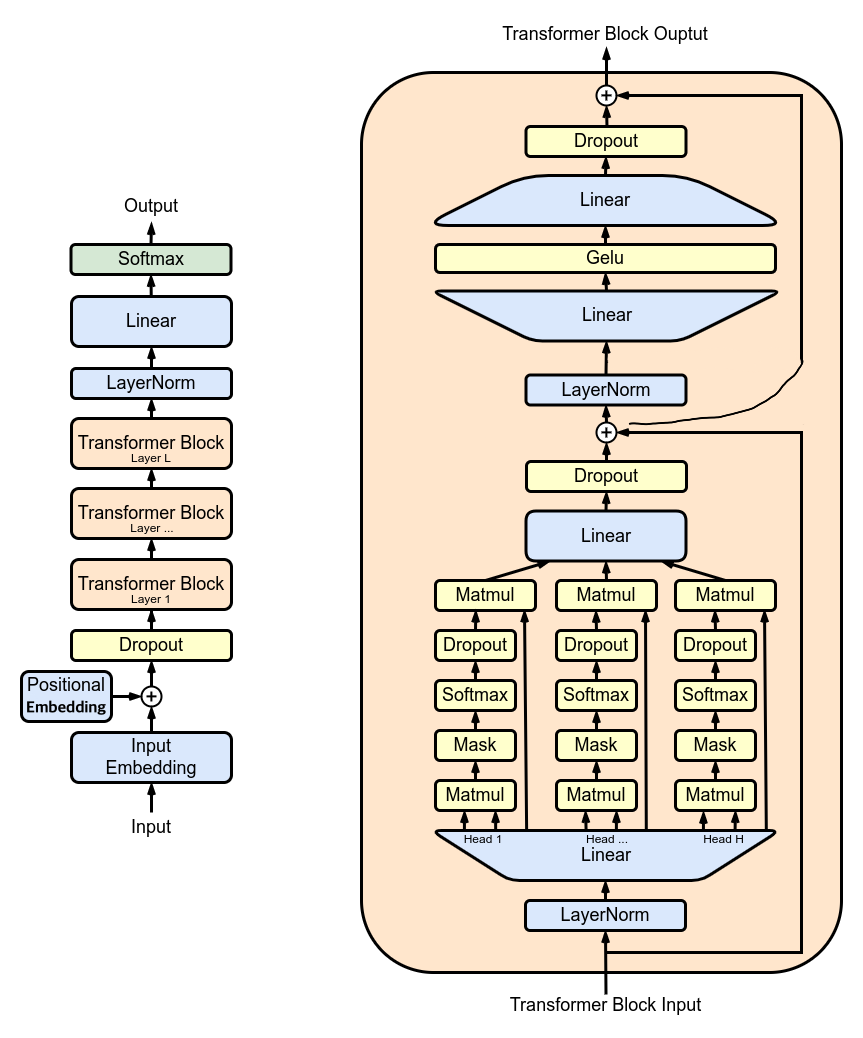
Scaled Dot-Product
Scaled Dot-Product attention from Transformer
\(Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V\)
scaling factor \(\frac{1}{\sqrt{d_k}}\) 없이도 학습은 가능하지만 \(d_k\) 값이 클 때 scaling은 성능을 더 높이고, “pushing softmax function into regions where it has extremely small gradients”(Vaswani et al, 2017) softmax가 매우 작은 기울기로 빠질 수 있는 문제를 방지한다. \(\sqrt{d_k}\)로 스케일링하면 벡터 합의 분산이 안정적으로 유지되도록 한다(1에 가까워지도록 한다). (만들면서 배우는 생성 AI, 2023)
원래 트랜스포머 아키텍처에서는 디코더의 두 번째 decoder-encoder attention에서 디코더의 값은 Q이고, 인코더의 값으로 K,V를 만들기 때문에 이런 구조가 등장했다. GPT는 인코더가 필요 없는 self-attention만 사용하므로 Q만 있어도 학습 실험은 가능하다.
loss 계산
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)
-1은 계산에 포함되지 않으며 정답 인덱스의 logit이 최대가 되도록 학습한다.
LayerNorm
layernorm 없이도(attention 이후, mlp 이후 2개 제거) loss가 좀 더 늦게 떨어질뿐 학습에는 문제가 없다.

파란색 nn.LayerNorm 결과. 좀 더 큰 폭으로 scailing 된다. LayerNorm도 C 만큼의 γ와 β 파라미터를 갖는다(2 * C).
Positional Encoding
PositionalEncoding1D 사용2. pos_enc 변수명이 되어야 하나 편의상 pos_emb로 통일
tok_emb = self.transformer.wte(idx) # token embeddings of shape (b, t, n_embd)
if self.pos_type == 'pos_enc':
pos_enc = PositionalEncoding1D(48)(tok_emb) # position encoding of shape (b, t, n_embd)
else:
pos_emb = self.transformer.wpe(pos) # position embeddings of shape (1, t, n_embd)
x = self.transformer.drop(tok_emb + (pos_enc if self.pos_type == 'pos_enc' else pos_emb))
position embedding 쪽이 loss가 훨씬 더 빨리, 작게 떨어진다. 사실상 positional encoding은 사용할 필요가 없다. 하지만 position 정보 없이는 학습되지 않으며, 당연히 token embeddings 없이도 학습되지 않는다.
Transformer 응용 모델
Pathways
여러 태스크를 수행할 수 있는 단일 학습 모델
Today’s models are dense and inefficient. Pathways will make them sparse and efficient.
인간은 문장을 해석할 때 뇌의 극히 일부만 활용한다는 점에서 착안, 동일하게 ‘희소하게(sparsely)’ 활성화 하는 단일 모델 구축.
Pathways 학습 논문이 PaLM이다.
Feed Forward Layer
커널 크기가 1인 1차원 합성곱이라고도 부른다. (오픈AI 코드는 이 명명법을 따름)
BigBird
트랜스포머 모델은 어텐션 메커니즘에 필요한 메모리가 시퀀스 길이의 제곱에 비례한다. BigBird는 Sparse Attention을 사용해 이 문제 해결. BERT에서 512토큰인데 반해 4,096으로 크게 늘어남.
Last Modified: 2024/05/13 11:24:47