
Word Embedding
Word2Vec
x = np.mean(context, axis=0)
h = np.dot(W1.T, x)
u = np.dot(W2.T, h)
y_pred = softmax(u)
e = -center + y_pred
왜 word2vec이 단어 표현word representation을 잘 하는가?
The reasons for successful word embedding learning in the word2vec framework are poorly understood. Goldberg and Levy point out that the word2vec objective function causes words that occur in similar contexts to have similar embeddings (as measured by cosine similarity) 위키, 논문
Sent2Vec
- Unsupervised Learning of Sentence Embeddings using Compositional n-Gram Features
- 문장 임베딩 Sent2Vec과 fastText 구현
Shallow sentence embedding model. The window is a full semantic unit (sentence, paragraph, document …) instead of a few consequtive words words.1
fastText 구현
공통
saveOutout()과saveVector()의 차이가 궁금하다. 함수를 수정하여 둘 다 동일한 값이 나오도록 패치했다.saveVector()를 기준으로 했으며 이 값이 fasttext 콘솔에서 실행했을때와 동일한 결과다. vector는 gensim에서load_word2vec_format()으로 읽을 수 있다.- 버그가 좀 있다. fasttext 자체의 버그도 있고, sent2vec을 적용하면서 생긴 버그도 있다. 정체 불명의 값을 저장하는
saveOutput()버그를 패치했는데, upstream 코드 확인이 필요하다. fasttext 또한 upstream 기준으로 최신 반영이 필요해 보인다.
CBOW
- 원래 cbow는 context의 mean을 입력으로 한 번만 계산하는 것으로 알고 있는데 fasttext 구현은
[input]벡터가 들어가서 각각의 grad를 계산하는 것으로 보인다. 즉, ngram을 쓰지 않는 경우 skipgram과 차이가 없어 보인다.그러나 ngram을 쓴다면 모든 ngram이 context를 대상으로 계산하게 되므로 skipgram의 계산량은 훨씬 더 증가한다.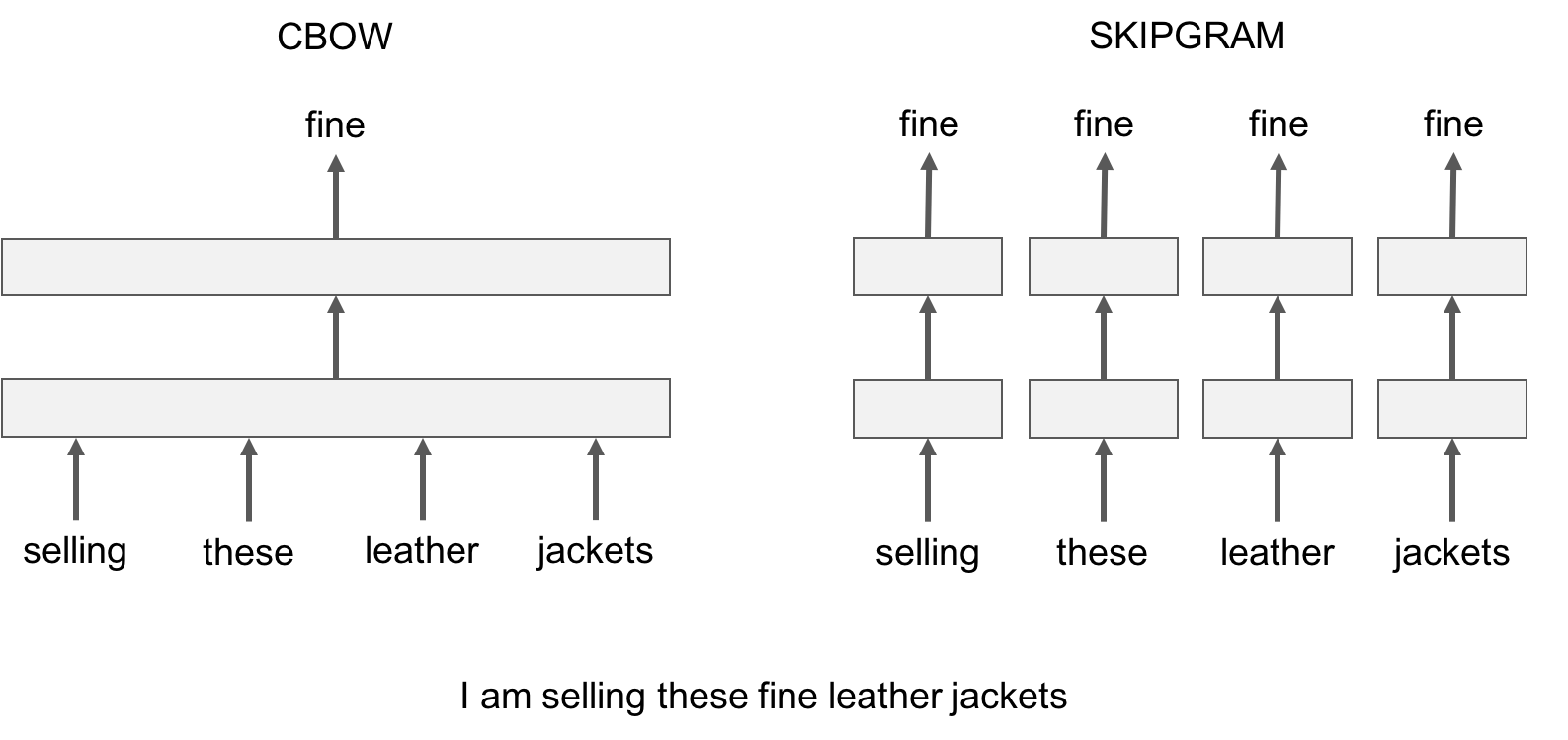
https://fasttext.cc/docs/en/unsupervised-tutorial.html
- fastText 문서에도 sum으로 처리한다고 되어 있다.
skipgram
line[w]가 target이다. 여기서는 context가 된다. boundary는 cbow와 마찬가지로 최대 윈도우 사이즈 내에서 랜덤하게 지정된다. seed가 따로 정의되지 않았기 때문에 학습마다 매 번 동일한 랜덤 값이 부여된다.
서비스
sent2vec fasttext 구현에서 5.5G 짜리 모델을 load_model()하는데 메모리가 모자라니(docker에서 4G만 할당한 상태) 로딩 중 Killed 메시지가 나오며 그냥 죽어버린다. 어떠한 예외처리도 되어 있지 않고 오류도 없이 그냥 죽어 당황스럽다. 메모리가 점점 차오르는 상황은 free -m으로 확인 가능하다. 1G 정도 차는데 6초 정도 소요됐다.
gensim은 mmap 옵션이 있어 다른 프로세스에서 메모리를 공유할 수 있는데 반해 fasttext는 그 기능이 없어 프로세스 마다 각각 메모리를 점유하므로 큰 모델의 경우 멀티 프로세스로 서비스가 어렵다.
Text Classification을 word2vec 중심으로 실험 해보니 SVC(linear kernel SVM)이 가장 성능이 좋고, word2vec이 그 다음을 차지했다고 한다.
getNgrams()는 cbow, skipgram을 위한 char ngram 함수이고addNgrams()는 sent2vec을 위한 토큰 ngram 생성 함수다.- negative sampling에서 unsupervised는 label이 존재하지 않을 것 같다.
word n-grams
ngram 확장이 (0,2), (0,6) 일때 마지막 (0,6)이 (2,6)과 같은 값을 갖는걸 확인할 수 있었다. 이는 hash collision으로 일종의 버그로 추측되며, 3 이상일때 문제가 발생한다.
nn.Embedding
Keras와 PyTorch 모두 Embedding은 lookup table 형태로 동작한다. 입력이 one-hot vector이기 때문에 W의 해당 row에 대한 단순 lookup이며 이 경우 Wx가 되어 미분이 가능하므로 loss를 전달 받아 training도 가능하다. 결국 embedding layer의 결과는 one-hot vector인 x와 학습된 W의 Wx 값이다. 당연히 CBOW나 Skip-gram 여부와 무관하게 원하는 어떤 형태의 임베딩도 가능하다.
Last Modified: 2022/04/14 11:19:01