
gguf
gguf quantization 기법
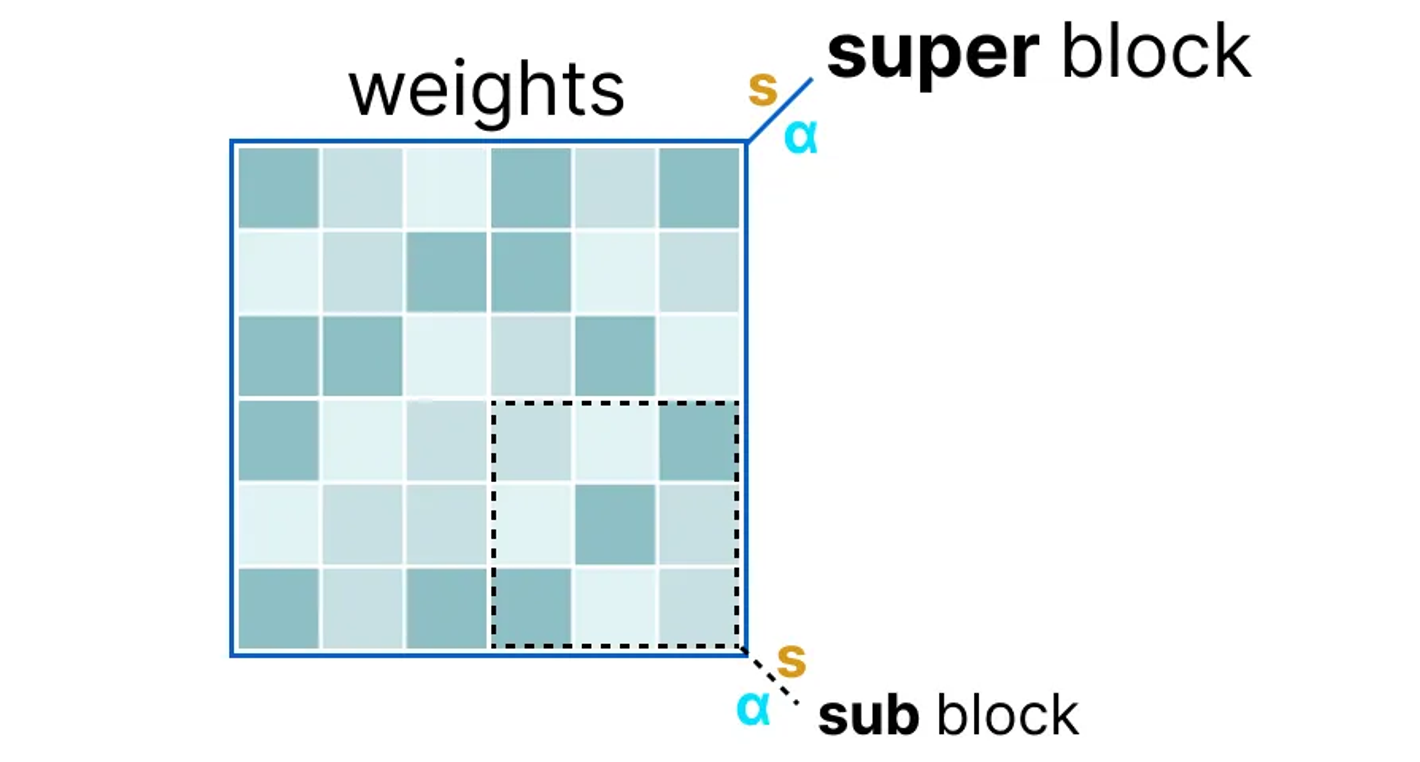 super block과 내부에 sub block으로 구분. 여기서 scaling factor s와 alpha a 추출.
super block과 내부에 sub block으로 구분. 여기서 scaling factor s와 alpha a 추출.
 sub block의 quantization은 scaling factor s를 곱한다.
sub block의 quantization은 scaling factor s를 곱한다.
 block-wise quantization은 s_sub를 quantize하기 위해 super block의 scaling factor, 즉 s_super를 사용한다.
block-wise quantization은 s_sub를 quantize하기 위해 super block의 scaling factor, 즉 s_super를 사용한다.
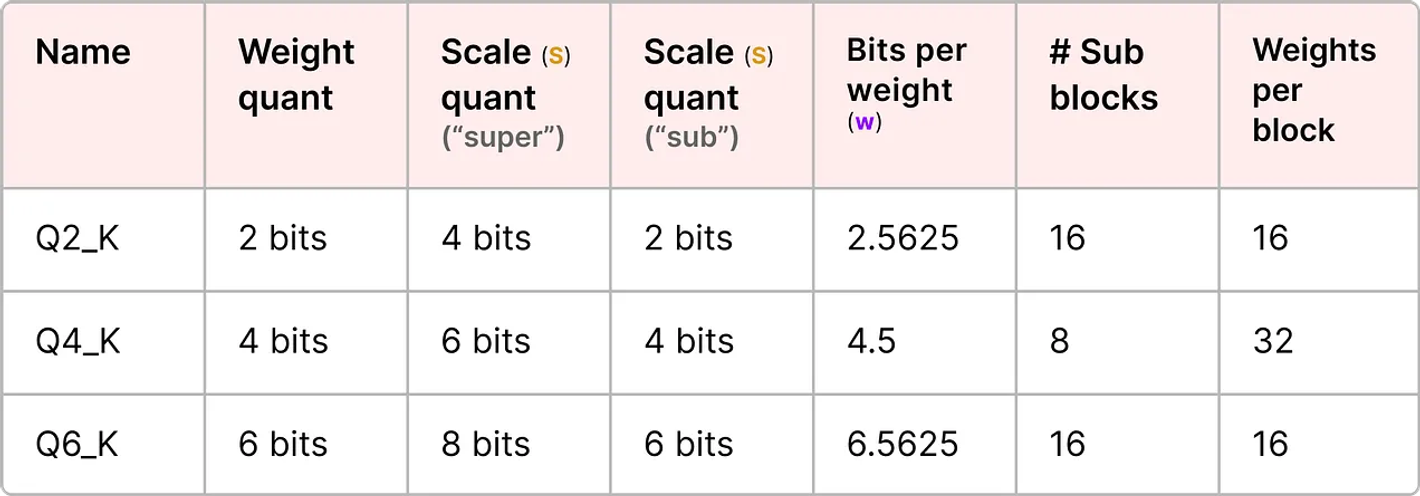 일반적으로 super block은 sub block의 scaling factor보다 더 높은 precision을 갖는다.
일반적으로 super block은 sub block의 scaling factor보다 더 높은 precision을 갖는다.
jay alammar와 visualize llm 책을 쓰고 있는 substack에서 참고함
HuggingFace
42dot 1.3B 모델의 경우 hf에서 구조를 확인할 수 있다.
model.embed_tokens.weight [50304,2048] F32
model.layers.0.input_layernorm.weight [2048] F32
model.layers.0.mlp.down_proj.weight [2048,5632] F32
model.layers.0.mlp.gate_proj.weight [5632,2048] F32
model.layers.0.mlp.up_proj.weight [5632,2048] F32
model.layers.0.post_attention_layernorm.weight [2048] F32
model.layers.0.self_attn.k_proj.weight [2048,2048] F32
model.layers.0.self_attn.o_proj.weight [2048,2048] F32
model.layers.0.self_attn.q_proj.weight [2048,2048] F32
model.layers.0.self_attn.v_proj.weight [2048,2048] F32
...
model.norm.weight [2048] F32
lm_head.weight [50304,2048] F32
layers는 23까지 올라가며 따라서 layer size는 24다.
gguf Tensors
gguf Q4_0 모델의 구조1는 다음과 같다.
Tensors:
+-----+---------------------------+------+---------------+-----------+
| # | Name | Type | Dimensions | Offset |
+====================================================================+
| 1 | output.weight | Q6K | [2048, 50304] | 0 |
|-----+---------------------------+------+---------------+-----------|
| 2 | token_embd.weight | Q4_0 | [2048, 50304] | 84510720 |
|-----+---------------------------+------+---------------+-----------|
| 3 | blk.0.attn_norm.weight | F32 | [2048] | 142460928 |
|-----+---------------------------+------+---------------+-----------|
| 4 | blk.0.ffn_down.weight | Q4_0 | [5632, 2048] | 142469120 |
|-----+---------------------------+------+---------------+-----------|
| 5 | blk.0.ffn_gate.weight | Q4_0 | [2048, 5632] | 148957184 |
|-----+---------------------------+------+---------------+-----------|
| 6 | blk.0.ffn_up.weight | Q4_0 | [2048, 5632] | 155445248 |
|-----+---------------------------+------+---------------+-----------|
| 7 | blk.0.ffn_norm.weight | F32 | [2048] | 161933312 |
|-----+---------------------------+------+---------------+-----------|
| 8 | blk.0.attn_k.weight | Q4_0 | [2048, 2048] | 161941504 |
|-----+---------------------------+------+---------------+-----------|
| 9 | blk.0.attn_output.weight | Q4_0 | [2048, 2048] | 164300800 |
|-----+---------------------------+------+---------------+-----------|
| 10 | blk.0.attn_q.weight | Q4_0 | [2048, 2048] | 166660096 |
|-----+---------------------------+------+---------------+-----------|
| 11 | blk.0.attn_v.weight | Q4_0 | [2048, 2048] | 169019392 |
...
| 219 | output_norm.weight | F32 | [2048] | 836487168 |
+-----+---------------------------+------+---------------+-----------+
- 대부분의 명칭이 다르므로 주의
- hf에서는
[vocab size, embedding length]인데, gguf는[embedding length, vocab size]로 되어 있음. 이외에 weight도 row, column이 반대이므로 주의
Last Modified: 2024/10/20 02:24:04